
第6回AIエッジコンテストに参加していました。
RISC-Vを使用して、画像とLIDAR点群による3D物体検出が課題でした。
残念ながら完走は出来ませんでした。
ただ貴重な勉強の機会になりましたし、自身への忘備録としても内容を紹介します。
第6回AIエッジコンテストが凄く難しいけど勉強になった感想
経済産業省が主催していた、「第6回AIエッジコンテスト」に参加していました。
テーマは「RISC-Vを使用した自動車走行時の画像・点群データによる3D物体検出」です。
もの凄く難しかったです。
残念ながら最後まで実装することは出来ませんでした。
ただ、本当に勉強になりました。忘備録として感想を紹介したいと思います。
書いている人のAIエッジの業務経験
正直なところ、筆者のAI・エッジなどの業務経験は「無し」です。
仕事はハードウェアのエンジニアをしています。(主に電気回路や基板を設計している人)
AIどころか、C++やPythonのプログラムも普段の仕事では全く使わない人です。
土日の趣味でブログとか書きつつ、電子工作やプログラムで遊んでいる人です。
(このブログの過去記事をさらっと見てもられば、普段何しているのか分かると思います)
去年の第5回AIエッジコンテストにも参加していました
去年の第5回AIエッジコンテストにも参加していました。
もちろん去年の第5回も完走できませんでした。手も足も出なかったです。
サンプルライブラリを少し触った・弄った程度です。第5回の感想記事は下記です。

そのリベンジマッチということもあり、最後の実装までの完走が今年の目標でした。
RISC-Vを使用した自動車の画像・点群データによる3D物体検出
とりあえず、テーマ名だけでお腹いっぱいになるぐらいのコンテストでした。
第6回(赤字箇所)の課題の難易度のイメージとしては下記感じです。
年々、難易度が上がっていく…。
②FPGAを使った画像認識 ←まだ分かる(第4回の課題)
③RISC-Vを使用した画像認識 ←分からんでもない(第5回の課題)
★①②③+LIDAR点群を使った3D物体検出 ←New!(第6回の課題)
文章だけでも、第6回の課題範囲が分かって貰えると思います。
やることも多かったですし、結局分からないこと・出来なかったことも沢山ありました。
まずはテーマについて、筆者の感想を紹介していきます。
自動車走行のLIDAR点群を使った3D物体検出
最初は本当に下記イメージ・感想でした。
正直な所、「LIDAR点群」「3D物体検出」を何も分かっていない所からスタートでした。
- データセットがnuScenes形式? → KITTI形式と何が違いますか?
- LIDAR座標?世界座標?カメラ座標? → すみません、統一してもらえませんか?
- PointPainting?VoxelNet? →新手の必殺技・スタンド名ですか?
自動車走行のデータセット形式も絡んでくるので、混乱に混乱しました。
分け分からずコードを弄って、変数の中身を試しにprintを叩いてみようならば…
下記のようなdict構造・行列・配列が大量に連続で襲ってきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
{'voxels': tensor([[[ 3.8857e+01, 3.0844e+01, 1.3182e+00, ..., 9.9577e-01, 3.8643e-03, 3.7033e-04], [ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00, 0.0000e+00, 0.0000e+00], [ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00, 0.0000e+00, 0.0000e+00], [ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00, 0.0000e+00, 0.0000e+00], [ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00, 0.0000e+00, 0.0000e+00]], ..., 0.0000e+00, 0.0000e+00]]], device='cuda:0'), 'num_points': tensor([1, 2, 1, ..., 2, 2, 2], device='cuda:0', dtype=torch.int32), 'coordinates': tensor([[ 0, 31, 1608, 777], [ 0, 26, 1507, 648], [ 0, 30, 1512, 656], ..., [ 2, 20, 649, 576], [ 2, 20, 647, 574], [ 2, 20, 643, 576]], device='cuda:0', dtype=torch.int32), 'num_voxels': tensor([[15147], [15151], [15049]]), 'metrics': [{'voxel_gene_time': 0.002718210220336914, 'prep_time': 0.002747774124145508}, {'voxel_gene_time': 0.0027320384979248047, 'prep_time': 0.002760171890258789}, {'voxel_gene_time': 0.0026803016662597656, 'prep_time': 0.00270843505859375}], 'anchors': tensor([[[ 0.0000, -49.6000, -0.9390, ..., 3.9000, 1.5600, 0.0000], [ 0.4033, -49.6000, -0.9390, ..., 3.9000, 1.5600, 0.0000], [ 0.8065, -49.6000, -0.9390, ..., 3.9000, 1.5600, 0.0000], ..., [ 48.7935, 49.6000, -0.7391, ..., 0.8000, 1.7300, 1.5700], [ 49.1967, 49.6000, -0.7391, ..., 0.8000, 1.7300, 1.5700], [ 49.6000, 49.6000, -0.7391, ..., 0.8000, 1.7300, 1.5700]]], device='cuda:0'), 'metadata': [{'token': 'b05ff89145b374f19c20b7ea6755f007'}, {'token': '792e28ae3402fb79ce87fc414c5a8b53'}, {'token': '2b41120736de26519c22cea7c9874133'}]} |
初めはLIDARの点群データを見ても、全く分からん…(そっ閉じ)。と言った感じでした。
FPGAへの実装で手一杯でした
筆者は、3D物体検出の機械学習→量子化→FPGAへの実装でタイムアップでした。
(RISC-Vを使った実装まで辿り着けませんでした。)
普通にFPGA(KV260)で3D物体検出をするのにも相当な課題量でした。
コンテストの期間は2022年/8月末~2023年1月末で、約5か月間と長めでした。
休みの日の隙間時間などでコツコツやっていました。(それでも時間が足りなかった…)
筆者の一例ですが、実施した概要と大体の実施時期を並べると下記形です。
2. ライブラリの準備・前処理をする ~10月
3. 3D物体検出の学習を行う ~11月
4. 3D物体検出のモデルをFPGAで使えるように量子化する ~12月
5. コンパイルしてFPGA用のモデルを作る ~12月
6. FPGA(KV260)へ実装・テストする ~1月 ←タイムアップ
7. RISC-Vを実装・テストする 未
RISC-Vで実装したかった(出来なかった)処理
多くのライブラリ・FPGAのDPUの力を借りて、メインの3D物体検出は動作出来ました。
RISC-Vは最後のサブ的な処理として、座標変換を行いたい…とは考えていました。
コンテストの最終出力結果として、グローバル(世界)座標で出す必要があったためです。
実装したかった構成としては下記です。
・検出したLIDAR座標をグローバル座標に変換 → FPGAのRISC-Vで実装
しかし、単に「RISC-Vの実装だけが出来なかった」という状況ではありませんでした。
RISC-V以外でも、本当にまだまだでした。正直なところ、実力不足でした。
後半に詳細を記述しますが、RISC-Vは遠かったです。
第6回AIエッジコンテストに関してのブログ記事
今回のコンテストで多くのことにトライ・テストしました。
忘備録として、苦労した・ハマった箇所はなるべく各ブログ記事にまとめています。
但し、まだまだ書ききれなかったことが一杯です。(また何処かで紹介したいと思います)
各記事の概要を紹介します。リンク先も貼っておきますので、興味ある方はどうぞ)
コンテストのデータセット・リファレンス環境への入門
今年はコンテストの運営サイドが、多くのリファレンス環境を用意してくれました。
ソフトウェア(3D物体検出)・ハードウェア(KV260)の環境ともに本当に助かりました。
最初にコンテストのデータセットをColabで触ってみた記事です。
Colabで大量のデータを送付・解凍すると何かしらエラー出る気がします。
ColabでMMDetectionとOpera Datasetを動かしてみた

最初にdocker環境でリファレンス環境を触ってエラーが出た内容です。
GPUメモリ不足(CUDA out of memory)の対応をブログ記事にしています。
GPUやCUDA含めた、FPGAでの開発環境の構築
今回Vitis AIには一番苦労しましたし、一番お世話になりました。
(Vitis AI…Xilinx(AMD)のFPGAのAI開発環境)
筆者の手法ではGPUが必須で、CUDA周辺含めての環境構築もかなり手間でした。
コンテストの最初にVitis AI 2.5などをインストールした記事です。
既に最新はVitis AI 3.0ですが、今回のコンテストでは2.5で対応していました。
VItis AI 2.5やPetaLinuxなどインストールしてみたメモ

Vitis AIのGPU版にはメモリが32GB必要で、仮想メモリで対応した記事です。
最近のVitis-AIの環境構築は要求は、一般PCには荷が重いです..。
Vitis AIでdocker_build_gpu.shが失敗するメモ
Vitis-AI 2.5のGPU版の環境構築をしたブログ記事です。
cuda-toolkitやらdockerなど結構大変でした。何回も入れ直しました(n敗)。
リファレンス環境の量子化(失敗)
筆者の最初の進め方は「リファレンス環境をそのままFPGAに実装してみる」でした。
ただテスト進める上で(筆者にとって)相当ハードル高いことが分かり、途中で諦めました。
学習したモデルをFPGAで使えるようにする「量子化」が本当に難しかったです。
Vitis AIから紹介されている量子化(vai_q_pytorch)のインストール方法の記事です。
但し、後述するConda環境毎入れ替えてしまう手段の方が良く使いました。
Vitis AIでvai_q_pytorchをインストールしてみたメモ
vai_q_pytorchをインストールする際にninjaが必要になったブログ記事です。
色々ライブラリ触ると、ninjaは結構使われていると実感します。
量子化(vai_q_pytorch)する上でのConda環境を新しく構築したブログ記事です。
今回のコンテストで一番触ったコマンド・スクリプトでした。
Vitis AIでPytorchのConda環境を新しく構築してみた

Vitis AI上でspconvの古いVer1.2.1のインストールしたブログ記事です。
リファレンス環境をVitis AIで動かすには古いspconvを何とかする必要がありました。
spconvの古いVer1.2.1のインストールが苦労したメモ
リファレンス環境とVitis AIのサンプルのSECONDの違いを調べたブログ記事です。
コンテストのリファレンス環境とVitis AIのサンプルの違いに苦しみました。
KITTIとPointPillarsのVitis AIのサンプルを調べたメモ
リファレンス環境(SECOND)の量子化にトライしたが失敗したブログ記事です。
Vitis AIのサンプル外の量子化は本当に難しかったです。
Vitis-AI Quantizer(量子化)の3D物体検出に失敗したメモ
Vitis AIサンプル環境での量子化
失敗したリファレンス環境の量子化で相当な時間使っていました。
(確かこの時点で11月末ぐらいで、コンテストも残り2か月ぐらいでした)
Vitis AIのサンプル環境をベースにして、量子化を進めていく方針に切り替えました。
Vitis AI上でnuScenesのデータの練習するためにminiを触ったブログ記事です。
nuScenesの本番環境は数百GB近いので、まずはminiで練習しました。
コンテストのデータセットの前処理をVitis AI上で実施したブログ記事です。
Vitis AI+コンテストのデータセットで学習・量子化できる環境を整えました。
nuScenes formatのLidar点群の前処理をしてみたメモ
コンテストのデータセットをVitis AIのPointPillarsで学習したブログ記事です
nuScenesで学習されたVitis AIのサンプルのモデル(重み)は強かったです。
量子化でPointPillarsのxmodelを出力したブログ記事です
ようやくコンテストのデータセットでFPGA向けに学習→量子化まで出来ました。
量子化のFast Finetuningをメモリ不足で諦めたメモ
KV260に向けてのコンパイル・テスト
何とか量子化できて、FPGAで使えるようにコンパイルまで進みました。(この時点で12月末)
最後は何とかFPGA(KV260)で3D物体検出のテスト実装して終わりました。
YOLOXやPointPillarsでVitis AIのコンパイルの練習をしたブログ記事です。
Vitis AIの中でもPointPillarsの処理(OP)は特殊でした。
Vitis AIでPytorchのcompileをしてみたメモ
KV260の練習としてYOLOXを動かしてみたブログ記事です。
Vitis AIのサンプル使って簡単にテストしてみた内容です。
nuScenes形式の前にKITTI形式を練習したブログ記事です。
やはりKITTI形式の方がデータセットとしてシンプルで楽でした。
KITTI形式の3D物体検出をKV260(FPGA)で試したメモ
nuScenes(mini)、コンテストのデータセットで3D物体検出したブログ記事です。
本当に、本当に長かったです。ただここでタイムアップでした。
(恐ろしいことに、まだコンテストの序章です。RISC-Vはこれからです。)
nuScenes形式の3D物体検出をKV260(FPGA)で試したメモ

第6回AIエッジコンテストで出来なかったこと
最後にKV260上で自分で量子化したモデルでも一応は3D物体検出を動かせました。
ただVitis AIのサンプルに頼りっきりで、(自力で)実装できたと言うには程遠い状況でした。
RISC-Vもですが、出来なかったこと多かったです。簡単に紹介します。
CPUの処理(OP)絡めた量子化・コンパイル
今回Vitis AIのサンプルベースで、3D物体検出のモデルを量子化→コンパイルしました。
しかしモデルが特殊で2つに分かれていました。(下記記事で紹介しています)
Vitis AIでPytorchのcompileをしてみたメモ
一部は(FPGAの)CPUの処理を入れ込む必要がありました。
公式の手順見たりして試したのですが、どうも上手くいかなかった箇所です。
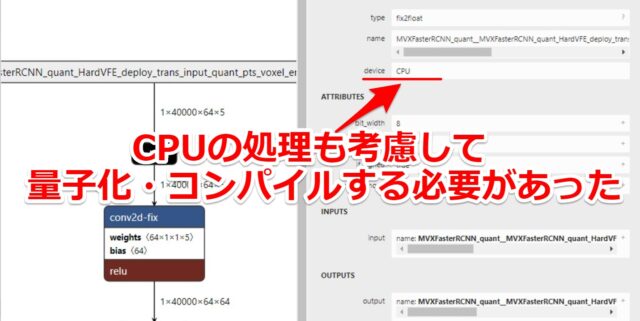
上手くいかなかった一部は、Xilinxのコンパイル済のモデルを一部使うなどしました。
またこれも後日、ブログ記事にしたいと思います。
RISC-Vを動かせるFPGA領域の確保
一応動いた3D物体検出はKV260で使える一番大きいDPU(B4096)の設定で使っていました。
使用したXilinxの提供の一部モデルがB4096のためです。合わせる必要がありました。
ただし、リファレンスのRISC-Vをそのまま入れるとFPGAの容量不足になりました。
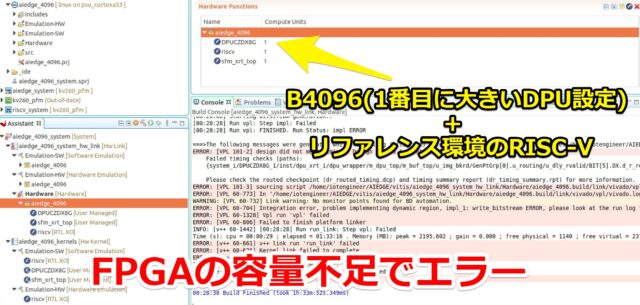
恐らく今回のコンテストでは、下記のような構成で組む必要があったと思います。
この辺りも時間が間に合わず、対応出来ませんでした。
- B3136(2番目に大きいDPU設定) + リファレンス環境のRISC-V
- B4096(1番目に大きいDPU設定) + カスタマイズ(軽量化)したRISC-V
RISC-Vの実装
RISC-Vに関しては、正直何も手を付けれていないです。
やりたいこと(座標変換)はあっても、実装するイメージから全く出来ていないです。
(メモリの受け渡し、DPUと並列化した処理などやりたい事は沢山ありました)
何事も一歩づつなので、RISC-Vに関しては今年度は積極的に勉強していきたいです。
第6回AIエッジコンテストの感想(良かった点)
残念ながらコンテストは完走できずでした。
ただ良かった点として、コンテストを通じて出来るようになったことも沢山あります。
3D物体検出をFPGAへの実装まで通せたこと
今年はLIDAR点群の前処理から始まり、学習~量子化~FPGA実装まで一通り通せました。
去年はシンプルな画像認識(YOLO)の学習・量子化すら、まともに出来ませんでした。
この辺りは成長を実感できたので、素直に嬉しいです。(去年の感想は下記です)
ブログの内容も失敗やエラーが多かったです。
ただ何かしら身に付いたことは、エラー出して苦労して悩んだところです。
やはり自分でドキュメント調べて、プログラムを弄ることが一番力が付くと再実感しました。
コンテストでもなければ、サンプルをポチポチ動かして終わっていたと思います。
多くのライブラリ含めて、やはり自分の手を動かしたので本当に力になったと思います。
- Python・Pytorch…ここまでプログラム触ったのは大学以来(普段は電気屋で使わない…)
- docker…神。無ければ開発環境を何回壊して、何回諦めていたか分からない。
- KITTI・nuScenes…自動車のデータセットをここまで調べるとは、夢にも思わなかった。
- Vitis AI…感謝。もしサンプルライブラリが無かったら、3D物体検出は出来なかった。
GPU・CUDAのインストールを恐れなくなったこと
今回のコンテストで初めて、機械学習用にCUDA環境をまともにインストールしました。
(今まではGPUボードを買っても、基本はディスプレイ用に画像出す程度です)
コンテスト前で機械学習+GPUが必要な際は、Colab環境で実施していました。

(初心者が)GPU+CUDA環境を正確にインストールするのは難易度が高かったです。
下記ループが何回も発生しました。(n敗)
2. CUDA環境を入れ直そうとするが、綺麗に消しきれない。
3. CUDA環境を再インストールしきれない。
4. OS(Ubuntu)ごとインストールし直す。
今までCUDAの環境構築が手間ということは聞いていたので、(食わず嫌いで)避けていました。
コンテスト(GPU+CUDA環境が必要)でなければ、身につかなかったと思うことの1つです
最初は何回も、CUDAを入れ直しては環境を壊して…を繰り返しました。
ただ、環境を壊した分だけ強くなるとは思いました。(壊さないに越したことはないですが…)
今回のコンテストの本題とは少し外れる内容ですが、下記ブログ記事でも紹介しています。
第6回AIエッジコンテストの感想(反省点)
コンテストを終えて、もう少しこうすれば良かったという反省点です。
(筆者自信の実力不足が一番の反省点ですが…)
一つのことに集中しすぎて時間を溶かしすぎた
約5か月のコンテストのため、筆者は休みの隙間(暇な)時間などでコツコツやっていました。
ただエラーに関して、試行錯誤して解決するのに休日が消えた…というのもザラでした。
時間が溶ける溶ける…といった感じでした。
個人的には試行錯誤の過程含めて、楽しんではやれたと思います。
ただ最初の方針(リファレンス環境の量子化(失敗))に関しては、若干粘りすぎたと思います。
諦めた時にはコンテスト期間の約60%終わっていて、残り2か月でした。
コンテストという枠組みですので、検討できる時間は限られています。
(今だから言えることかもしれないですが…)
もう少し早い段階から色んなアプローチを模索出来れば良かったかと思います。
もう少し良いPC環境を用意しても良かった
今回は古いデスクトップPCを用意して、OSをLinux(Ubuntu)にして開発環境にしました。
3D物体検出の前処理~学習~量子化~コンパイル含めて、基本1台で対応しました。
やはり「もしCUDAなどで環境が壊れても、OS入れ直せばいい」の精神は楽です。
ただスペックが少し貧弱だったかと思います。
5~6年前の汎用PCに少し改造して、補助電源無しのGPUボード(メモリ4GB)積んだだけでした。
(電源の制約で使えるGPUが限られる。PCメモリもDDR3の2枚挿しで実質最大16GB。)

3D物体検出の学習・量子化を進める上で、何回もメモリ不足に悩まされました。
次回までにPCの自作?改善?した方が良いかも…と思いました。
謝辞
コンテスト内のフォーラムでの有識者のコメント、Slackでの情報に助けられました。
本当にありがとうございました。
運営者・関係者の皆さま
今回は、いつもと違うこと・新たなことが多くあったので本当に大変だったと思います。
- 初めて扱う(nuScenes形式の自動車運転の)データセット
- 電子部品難の中でコンテスト中に使用する評価ボードの変更対応
- 多くのリファレンス環境の準備
ただ今年も良い意味で尖ったコンテストだと(個人的に)感じています。
大会の運営者様にはデータや資料を始め、評価用ボードまで提供していただきました。
この場を借りて、お礼申し上げます。
参加者の皆さま
今年も最後まで実装出来た人の方が少ないと思います。
おそらく初めての方・専門外の人にとっては苦しい戦いになったはずです。
(というかRISC-V、FPGA、3D物体検出を全て専門の人など、ほぼいないと思いますが…)
前回の第5回もでしたが、今回の第6回も完走した人はマジで凄いと思います。
本当にリスペクト・尊敬しかないです。
ただ、完走できた人・完走できなかった人ともにお疲れ様でした。
Web記事賞をいただきました
3/11追記。今回の第6回AIエッジコンテストで「Web記事賞」を頂きました。
※上位の入賞ではないです。
※コンテストで「教育効果の高い記事をブログ等でWeb上に執筆した」旨での賞です。
主催者側から声をかけてもらい、コンテストの表彰式・懇親会に参加してきました。
その際の感想を下記記事で紹介しています。(リンク先はこちら)
AIエッジコンテストの表彰式・懇親会に呼ばれたので参加してみた

まとめ
「第6回AIエッジコンテスト」の感想をブログ記事として紹介させていただきました。
テーマは「RISC-Vを使用した自動車走行時の画像・点群データによる3D物体検出」でした。
難易度も高く、中身も良い意味で尖っている、貴重なハードウェアのコンテストだと思います。
おそらく来年もあると思いますので、興味持った方は是非トライしてみて下さい。

コメント