Vitis AIのPytorchのモデル(.xmodel)をコンパイルしてみました。
練習を兼ねて、複数の物体検出(YOLOX、PointPillars)のモデルでテストしています。
FPGA(KV260)向けにコンパイルしたコマンド例含めて紹介します。
Vitis AIでPytorchのcompileをしてみたメモ
FPGA(KV260)向けにVitis AIのPytorchのモデル(.xmodel)をコンパイルしました。
複数の物体検出(YOLOX、PointPillars)のモデルで練習した例を紹介します。
実行環境
Vitis AI 2.5の環境でコンパイルしました。PC環境は下記となります。
- CPU…Core i5 6400
- GPU…NVIDIA GeForce GTX 1650(メモリ4GB)
- メモリ…16GB
- SSD…500GB
Vitis AIのコンパイルに関してはCPUで実行されますのでGPUが無くても大丈夫です。
GPU用のdocker上でコンパイルしても、実際にはCPUで実施されていました。
物体検出のモデルをコンパイルします
今回の一番の目的は、3D物体検出のモデルをFPGA向けにコンパイルすることです。
下記記事にて学習したモデル(.pth)をFPGA向けのモデル(.xmodel)に量子化済です。
量子化のFast Finetuningをメモリ不足で諦めたメモ
ただし、3D物体検出(PointPillars)のモデルは特殊な形です。
※量子化する際に2個のモデル(.xmodel)に分かれています。
そのため、一般的な物体検出(YOLOX)の1個のモデルでもテストしてみます。
DPUCZDX8G_ISA1_B4096
今回はKV260というFPGAの評価ボード向けにコンパイルします。
KV260で使えるAI向けのDPUが「DPUCZDX8G」という型番になります。
その中でも容量がB4096,B3136…と分かれています。
今回使用するのは「DPUCZDX8G_ISA1_B4096」です。
KV260で使える中では一番大きなDPUサイズです。
(Vitis AIがKV260向けに提供しているコンパイル済のモデルもB4096です)
「DPUCZDX8G_ISA1_B4096」を指定するモデルが下記となります。
コンパイル実行する際にarch.jsonのファイル名で使います。中身は型番が書いているだけです。
|
1 |
{"fingerprint":"0x101000016010407"} |
Vitis AI 2.0以前のプラットフォームは注意
Vitis AI 2.0から2.5にかけて、コンパイルに使うモデル名が大きく変更されています。
コンパイルする際に実際にFPGAに使うモデル名(arch.json)を指定します。
従来の2.0以前までコンパイルできたモデル名で2.5だと出来ないケースがあります。
※今回は使いませんが、もし古いプラットフォーム向けにコンパイルしたい場合
古いVitis AIをpullするかチェックアウトするしかないと思います。
Vitis AI 2.5環境下では公式が下記を紹介していました。
https://github.com/Xilinx/Vitis-AI/tree/2.5#previous-vitis-ai-version
実際に下記例で古いVitis AI CPU版(1.4)のdocker環境を実行できました。
./docker_run.sh xilinx/vitis-ai-cpu:1.4.1.978
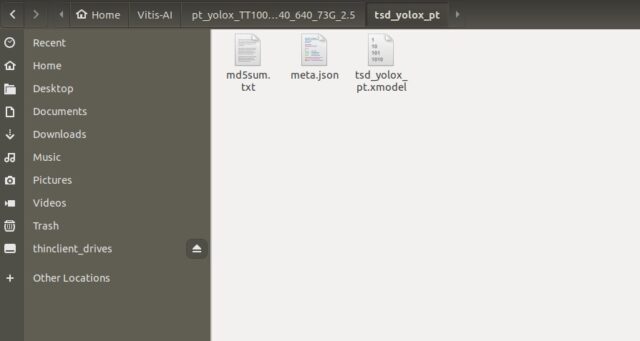
YOLOX(物体検出)のモデルをコンパイル
YOLOXのVitis AI 2.5のライブラリに関しては下記のyamlにリンク先があります。
(B4096でコンパイル済のモデルのリンク先も記載されています)
https://github.com/Xilinx/Vitis-AI/tree/2.5/model_zoo/model-list/pt_yolox_TT100K_640_640_73G_2.5
下記のようにライブラリ自体はダウロード・解凍して確認できます。
量子化前・後のモデル(重み)ファイルが用意されています。
|
1 2 3 4 |
wget https://www.xilinx.com/bin/public/openDownload?filename=tsd_yolox_pt-zcu102_zcu104_kv260-r2.5.0.tar.gz tar -xzvf openDownload\?filename\=tsd_yolox_pt-zcu102_zcu104_kv260-r2.5.0.tar.gz cd pt_yolox_TT100K_640_640_73G_2.5/ ls |
またVitis AIのPytorch用のConda環境下でコンパイルは実行します。
コンパイルする量子化後モデル(.xmodel)は「/quantized」のフォルダ内に入っています。
|
1 2 |
Vitis-AI /workspace/pt_yolox_TT100K_640_640_73G_2.5 > conda activate vitis-ai-pytorch (vitis-ai-pytorch) Vitis-AI /workspace/pt_yolox_TT100K_640_640_73G_2.5 > |
出力するファイル名・フォルダ名を「tsd_yolox_pt」としています
※フォルダ内にモデルを指定するarch.jsonを置いて実行しています
vai_c_xir -x quantized/YOLOX_0_int.xmodel -a arch.json -n tsd_yolox_pt -o ./tsd_yolox_pt
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
(vitis-ai-pytorch) Vitis-AI /workspace/pt_yolox_TT100K_640_640_73G_2.5 > vai_c_xir -x quantized/YOLOX_0_int.xmodel -a arch.json -n tsd_yolox_pt -o ./tsd_yolox_pt ************************************************** * VITIS_AI Compilation - Xilinx Inc. ************************************************** [UNILOG][INFO] Compile mode: dpu [UNILOG][INFO] Debug mode: function [UNILOG][INFO] Target architecture: DPUCZDX8G_ISA1_B4096 [UNILOG][INFO] Graph name: YOLOX_0, with op num: 780 [UNILOG][INFO] Begin to compile... [UNILOG][INFO] Total device subgraph number 5, DPU subgraph number 1 [UNILOG][INFO] Compile done. [UNILOG][INFO] The meta json is saved to "/workspace/pt_yolox_TT100K_640_640_73G_2.5/./tsd_yolox_pt/meta.json" [UNILOG][INFO] The compiled xmodel is saved to "/workspace/pt_yolox_TT100K_640_640_73G_2.5/./tsd_yolox_pt/tsd_yolox_pt.xmodel" [UNILOG][INFO] The compiled xmodel's md5sum is 3617ab082e95cd399501e98b513fd277, and has been saved to "/workspace/pt_yolox_TT100K_640_640_73G_2.5/./tsd_yolox_pt/md5sum.txt" |
無事、コンパイルされたモデルが出力されました。
tsd_yolox_ptのフォルダが作成されて、tsd_yolox_pt.xmodelがコンパイル後のファイルです。
一緒にメタファイル(meta.json)、チェックサム(md5sum.txt)も出力されます。
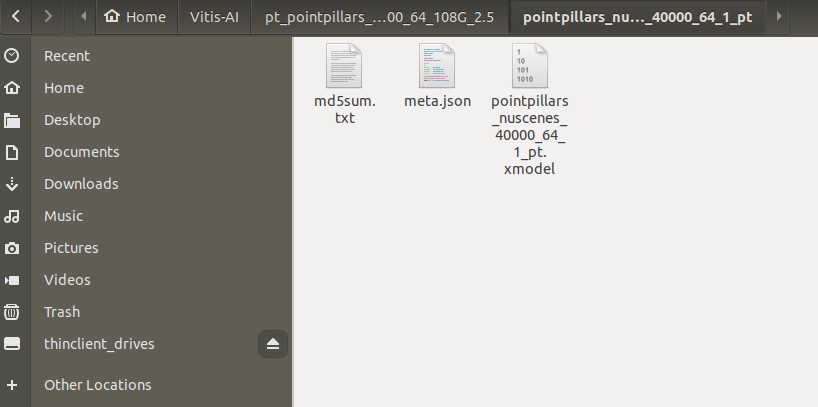
PointPillars(3D物体検出)のモデルをコンパイル
PointPillarsも同様にコンパイルしていきます。
nuScenes用のもあり、Vitis AIサンプルは下記のyaml内のリンクからダウンロードできます。
(B4096でコンパイル済のモデルのリンク先も記載されています)
|
1 2 |
wget https://www.xilinx.com/bin/public/openDownload?filename=pt_pointpillars_nuscenes_40000_64_108G_2.5.zip unzip openDownload?filename=pt_pointpillars_nuscenes_40000_64_108G_2.5.zip |
CPUの処理含むモデルは直接コンパイルできなかった
PointPillars + nuScenesの量子化後のモデルは2つに分かれています。
サンプルだと「/quantized」のフォルダ中にあります。
特殊な形で、一つ目のモデルは最後の処理(OP)でCPUが絡んできます。
- MVXFasterRCNN_quant_0_int.xmodel ←CPUの処理(OP)が最後に入っている
- MVXFasterRCNN_quant_1_int.xmodel
Xilinxの公式にも、今回の特殊なCustom_OPの手順が記載されています。
https://docs.xilinx.com/r/2.5-English/ug1414-vitis-ai/Custom-OP-Workflow
コンパイル前のxmodelのOPを弄る必要があるということです。
(失敗に終わりましたが…)また別の記事で紹介します。
1個目の「MVXFasterRCNN_quant_0_int.xmodel」はコンパイル出来ませんでした。
実際にコンパイルすると、途中のBegin to compile...で固まります。
(サンプルでも、筆者オリジナルの量子化後のモデル(.xmodel)でも同様な結果でした)
vai_c_xir --xmodel quantized/MVXFasterRCNN_quant_0_int.xmodel --arch arch.json --net_name pointpillars_nuscenes_40000_64_0_pt --output_dir ./pointpillars_nuscenes_40000_64_0_pt
|
1 2 3 4 5 6 7 8 9 |
(vitis-ai-pytorch) Vitis-AI /workspace/pt_pointpillars_nuscenes_40000_64_108G_2.5 > vai_c_xir --xmodel quantized/MVXFasterRCNN_quant_0_int.xmodel --arch arch.json --net_name pointpillars_nuscenes_40000_64_0_pt --output_dir ./pointpillars_nuscenes_40000_64_0_pt ************************************************** * VITIS_AI Compilation - Xilinx Inc. ************************************************** [UNILOG][INFO] Compile mode: dpu [UNILOG][INFO] Debug mode: function [UNILOG][INFO] Target architecture: DPUCZDX8G_ISA1_B4096 [UNILOG][INFO] Graph name: MVXFasterRCNN_quant_0, with op num: 11 [UNILOG][INFO] Begin to compile... |
1個目に関しては、一旦Xilinxから提供されているコンパイル済のモデルを流用します。
2個目の「MVXFasterRCNN_quant_1_int.xmodel」はコンパイル出来ました。
vai_c_xir --xmodel quantized/MVXFasterRCNN_quant_1_int.xmodel --arch arch.json --net_name pointpillars_nuscenes_40000_64_1_pt --output_dir ./pointpillars_nuscenes_40000_64_1_pt
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
(vitis-ai-pytorch) Vitis-AI /workspace/pt_pointpillars_nuscenes_40000_64_108G_2.5 > vai_c_xir --xmodel quantized/MVXFasterRCNN_quant_1_int.xmodel --arch arch.json --net_name pointpillars_nuscenes_40000_64_1_pt --output_dir ./pointpillars_nuscenes_40000_64_1_pt ************************************************** * VITIS_AI Compilation - Xilinx Inc. ************************************************** [UNILOG][INFO] Compile mode: dpu [UNILOG][INFO] Debug mode: function [UNILOG][INFO] Target architecture: DPUCZDX8G_ISA1_B4096 [UNILOG][INFO] Graph name: MVXFasterRCNN_quant_1, with op num: 152 [UNILOG][INFO] Begin to compile... [UNILOG][INFO] Total device subgraph number 5, DPU subgraph number 1 [UNILOG][INFO] Compile done. [UNILOG][INFO] The meta json is saved to "/workspace/pt_pointpillars_nuscenes_40000_64_108G_2.5/./pointpillars_nuscenes_40000_64_1_pt/meta.json" [UNILOG][INFO] The compiled xmodel is saved to "/workspace/pt_pointpillars_nuscenes_40000_64_108G_2.5/./pointpillars_nuscenes_40000_64_1_pt/pointpillars_nuscenes_40000_64_1_pt.xmodel" [UNILOG][INFO] The compiled xmodel's md5sum is a35ccc326dd733bbbe5a5d908b040272, and has been saved to "/workspace/pt_pointpillars_nuscenes_40000_64_108G_2.5/./pointpillars_nuscenes_40000_64_1_pt/md5sum.txt" |
vai_c_xirのオプション
今回Vitis AIのvai_c_xirを使ってコンパイルしました。
基本は量子化後のモデル(.xmodel)を全ての処理(OP)をコンパイルします。
但しオプションを使えば、一部だけ実施できる旨も紹介します。(本当に小ネタです。)
Xilinxの公式のドキュメントでは、下記に記載されています。
https://docs.xilinx.com/r/2.5-English/ug1414-vitis-ai/VAI_C-Usage
Use --options '{"output_ops": "op_name0,op_name1"}' to specify output ops
例えば、モデル名のノード名はNetronで確認できます。
途中の箇所のノードの名前を指定することで、途中までのコンパイルとなります。
下記例ですとデフォルトのvai_c_xirと比較すると、op numが11→9となっています。
Graph name: MVXFasterRCNN_quant_0, with op num: 11 → 9
|
1 2 3 4 5 6 7 8 9 10 |
(vitis-ai-pytorch) Vitis-AI /workspace/pt_pointpillars_nuscenes_40000_64_108G_2.5 > vai_c_xir --xmodel quantized/MVXFasterRCNN_quant_0_int.xmodel --arch arch.json --net_name pointpiars_nuscenes_40000_64_0_pt --output_dir ./pointpillars_nuscenes_40000_64_0_pt --options '{"output_ops":"MVXFasterRCNN_quant__MVXFasterRCNN_quant_HardVFE_deploy_trans_input_quant_pts_voxel_encoder__VFELayer_deploy_quant_vfe_layers__ModuleList_0__ReLU_relu__3063_fix"}' ************************************************** * VITIS_AI Compilation - Xilinx Inc. ************************************************** [UNILOG][INFO] xir::Op{name = MVXFasterRCNN_quant__MVXFasterRCNN_quant_HardVFE_deploy_trans_input_quant_pts_voxel_encoder__VFELayer_deploy_quant_vfe_layers__ModuleList_0__ReLU_relu__3063_fix, type = fix} has been assigned to be an output op. [UNILOG][INFO] Compile mode: dpu [UNILOG][INFO] Debug mode: function [UNILOG][INFO] Target architecture: DPUCZDX8G_ISA1_B4096 [UNILOG][INFO] Graph name: MVXFasterRCNN_quant_0, with op num: 9 [UNILOG][INFO] Begin to compile... |
まとめ
量子化後のモデルをFPGA(KV260)用にコンパイルすることが出来ました。
次からは実際にKV260で3D含めた物体検出をテストしていきます。
下記記事にてYOLOX(物体検出)のテストをしています。(リンク先はこちら)
今回の記事含めて、第6回AIエッジコンテストの一環でした。
下記にてコンテストでテスト・実施したことのまとめを紹介しています。

コメント