Vitis AIのFPGA向けの量子化で精度ロスを防ぐFast Finetuningという機能があります。
但しPCのメモリが有る程度必要でした。(今回だと28GB程度)
低スペックPCには難しく、普通の量子化をした旨を紹介します。
量子化のFast Finetuningをメモリ不足で諦めたメモ
3D物体検出のモデルを量子化してみました。
Xilinxのサンプルを基にFast FinetuningをONにした量子化をしてみました。
但し、PCのメモリが足りなくエラーが出て止まりました。
結局は普通の量子化をして対応したのですが、エラーの内容含めて紹介します。
実行環境
下記の環境で実行しました。
最終的にはXilinxのFPGAに実装したいため、Vitis AI上の環境で学習しています。
- Vitis AI 2.5 + nuScenes_PointPillarsのライブラリ
- 第6回AIエッジコンテストのデータセット
PC環境は下記となります。3D物体検出の学習を行うには大分貧弱なPCです。
- CPU…Core i5 6400
- GPU…NVIDIA GeForce GTX 1650(メモリ4GB)
- メモリ…16GB
- SSD…500GB
3D物体検出の学習まで対応済
学習・評価に必要なデータセットの用意・前処理は下記記事で対応済です。
nuScenes formatのLidar点群の前処理をしてみたメモ
下記記事で実際に学習してモデル(.pth)ファイルまで作成しています。
またnuScenes(mini)の公式のデータでも同様に対応できました。
下記記事でVitis AIの使ったサンプル、またDocker上のコマンド含めて紹介しています。
Fast Finetuningで発生したエラー
XilinxのnuScenes_PointPillarsのサンプルでは量子化のスクリプトが用意されています。
スクリプトの中身を確認してみます。(下記はrun_quant.shの一部抜粋です)
Fast Finetuningの目的をコメント文で「量子化での精度向上」と記載していました。
|
1 2 3 4 5 |
# Note: for this model, utilize the fast-finetune trick could improve the accuracy of quantized model Q_DIR=quantized echo "Calibrating model quantization..." MODE='calib' python code/mmdetection3d/tools/quant.py ${Q_CONFIG} ${WEIGHTS} --quant_mode ${MODE} --quant_dir ${Q_DIR} --calib_len 400 --fast_finetune |
量子化のプログラムにオプションとして赤字の「--fast_finetune」が用意されています。
python code/mmdetection3d/tools/quant.py ${Q_CONFIG} ${WEIGHTS} --quant_mode ${MODE} --quant_dir ${Q_DIR} --calib_len 400 --fast_finetune
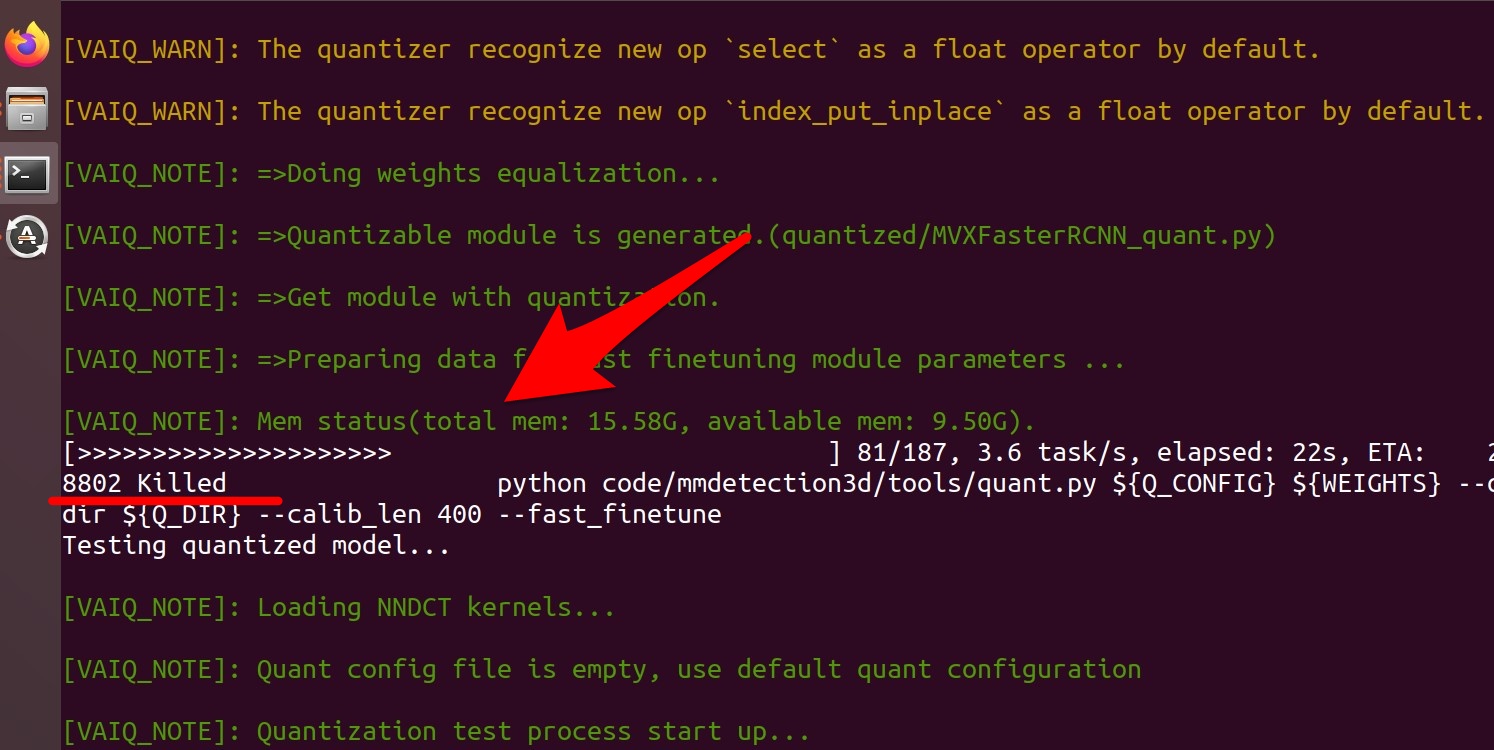
実際にスクリプトをそのまま動かしてみますと、エラーが発生しました。
量子化の途中で処理が止められていました。
run_quant.sh: line 42: 8802 Killed
|
1 2 3 4 5 |
(vitis-ai-pt1_7) Vitis-AI /workspace/pt_pointpillars_nuscenes_40000_64_108G_2.5 > bash run_quant.sh Calibrating model quantization... ~~~~~~~~~~~~~~~~~~~~~ [VAIQ_NOTE]: Mem status(total mem: 15.58G, available mem: 9.50G). [>>>>>>>>>>>>>>>>>>>>> ] 81/187, 3.6 task/s, elapsed: 22s, ETA: 29srun_quant.sh: line 42: 8802 Killed |
どうやら普通の量子化と違って、PCのメモリをかなり使用するようです。
今回の3D物体検出のモデルのデフォルトの量子化だと28GBほど必要そうでした。
ただ筆者のPCメモリが16GBのため、Fast Finetuningを使った量子化は諦めました。
(他にもパラメータなど弄って調整してみましたが、16GB以下には出来ず…)
一応PC上の仮想メモリを増やして対応できるかも確認してみましたが、ダメでした。
下記コマンドのようにVitis AIのdocker起動前に実行しています。
PCのメモリ16GB+仮想メモリ16GBでは同様にエラーが出ました。
|
1 2 3 |
sudo dd if=/dev/zero of=/var/swap bs=1M count=32768 sudo mkswap /var/swap sudo swapon /var/swap |
通常の量子化では対応できました
量子化によって精度ロスは発生するかもしれませんが、通常の量子化で対応しました。
スクリプト(run_quant.sh)には通常の量子化がコメントアウトされていました。
Fast Finetuningの方をコメントアウトして、通常の方でxmodel出力まで対応します。
|
1 2 3 4 5 6 7 8 9 10 |
Note: for this model, direct 8bit-quantization gets an accuracy that is not so satisfactory, so we use the fast-finetune trick Q_DIR=quantized echo "Calibrating model quantization..." MODE='calib' python code/mmdetection3d/tools/quant.py ${Q_CONFIG} ${WEIGHTS} --quant_mode ${MODE} --quant_dir ${Q_DIR} --calib_len 1 echo "Testing quantized model..." MODE='test' python code/mmdetection3d/tools/quant.py ${Q_CONFIG} ${WEIGHTS} --quant_mode ${MODE} --quant_dir ${Q_DIR} --eval 'bbox' echo "Dumping xmodel..." python code/mmdetection3d/tools/quant.py ${Q_CONFIG} ${WEIGHTS} --quant_mode ${MODE} --quant_dir ${Q_DIR} --dump_xmodel |
また量子化の際に使うデータセットでキャリブレーションが取れます。
但し、この設定を一旦デフォルトの400から1にしています。「--calib_len 1」箇所です。
理由は量子化の際にGPUメモリ不足エラーが発生するためです。
python code/mmdetection3d/tools/quant.py ${Q_CONFIG} ${WEIGHTS} --quant_mode ${MODE} --quant_dir ${Q_DIR} --calib_len 1
最終的には、FPGAの量子化をしてコンパイルに必要なxmodelの出力まで出来ました。
(今回のPointPillarsでは2個のxmodelがモデルが出力されています)
[VAIQ_NOTE]: =>Successfully convert 'MVXFasterRCNN_quant_0' to xmodel.(quantized/MVXFasterRCNN_quant_0_int.xmodel)
[VAIQ_NOTE]: =>Successfully convert 'MVXFasterRCNN_quant_1' to xmodel.(quantized/MVXFasterRCNN_quant_1_int.xmodel)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
(vitis-ai-pt1_7) Vitis-AI /workspace/pt_pointpillars_nuscenes_40000_64_108G_2.5 > bash run_quant.sh ~~~~~~~~~~~~~~~~~~~~~ [VAIQ_NOTE]: =>Converting to xmodel ... [VAIQ_NOTE]: =>Dumping 'MVXFasterRCNN_quant_0'' checking data... [VAIQ_WARN]: Only dump first output of multi-output node:'MVXFasterRCNN_quant::MVXFasterRCNN_quant/HardVFE_deploy_trans_input_quant[pts_voxel_encoder]/VFELayer_deploy_quant[vfe_layers]/ModuleList[0]/Max[max]/inputs.2(max)'. [VAIQ_WARN]: Only dump first output of multi-output node:'MVXFasterRCNN_quant::MVXFasterRCNN_quant/HardVFE_deploy_trans_input_quant[pts_voxel_encoder]/VFELayer_deploy_quant[vfe_layers]/ModuleList[0]/Max[max]/inputs.2(max)'. [VAIQ_NOTE]: =>Finsh dumping data.(quantized/deploy_check_data_int/MVXFasterRCNN_quant_0) [VAIQ_NOTE]: =>Dumping 'MVXFasterRCNN_quant_1'' checking data... [VAIQ_NOTE]: =>Finsh dumping data.(quantized/deploy_check_data_int/MVXFasterRCNN_quant_1) [VAIQ_NOTE]: =>Successfully convert 'MVXFasterRCNN_quant_0' to xmodel.(quantized/MVXFasterRCNN_quant_0_int.xmodel) [VAIQ_NOTE]: =>Successfully convert 'MVXFasterRCNN_quant_1' to xmodel.(quantized/MVXFasterRCNN_quant_1_int.xmodel) |
量子化での精度ロスを確認してみる
今回の量子化前後でどれほど精度ロスが出たのか確認してみます。条件は下記です。
- Vitis AI 2.5 + nuScenes_PointPillarsのライブラリ
- 第6回AIエッジコンテストのLIDAR点群のデータセット(3d_labels)
- 量子化したモデルはライブラリで提供のもの(pointpillars-nus.pth)
量子化前の評価
量子化前は自動車(car)はAP_0.665、人(pedestrian)はAP_0.046という評価結果でした。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
(vitis-ai-pt1_7) Vitis-AI /workspace/pt_pointpillars_nuscenes_40000_64_108G_2.5 > bash run_eval.sh [>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 187/187, 1.4 task/s, elapsed: 132s, ETA: 0s Formating bboxes of pts_bbox Start to convert detection format... [>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 187/187, 30.6 task/s, elapsed: 6s, ETA: 0s Results writes to /tmp/tmpct_xzh2q/results/pts_bbox/results_nusc.json Evaluating bboxes of pts_bbox mAP: 0.0914 mATE: 0.5661 mASE: 0.5572 mAOE: 1.2971 mAVE: 1.4948 mAAE: 0.6287 NDS: 0.1705 Eval time: 7.0s Per-class results: Object Class AP ATE ASE AOE AVE AAE car 0.665 0.226 0.217 0.278 3.834 0.387 truck 0.109 0.548 0.283 0.755 2.388 0.514 bus 0.000 0.613 0.383 2.534 1.633 0.824 trailer 0.000 1.000 1.000 1.000 1.000 1.000 construction_vehicle 0.002 0.725 0.340 1.074 0.583 0.473 pedestrian 0.046 0.152 0.494 1.738 0.899 0.464 motorcycle 0.000 1.000 1.000 1.000 1.000 1.000 bicycle 0.000 0.253 0.318 2.295 0.622 0.366 traffic_cone 0.093 0.143 0.537 nan nan nan barrier 0.000 1.000 1.000 1.000 nan nan |
量子化後の評価
量子化後は自動車(car)はAP_0.647、人(pedestrian)はAP_0.056という評価結果でした。
ある程度評価出来ている自動車(car)を前後で比較すると、確かに精度ロスが発生してました。
AP_0.665 → AP_0.647
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
[VAIQ_NOTE]: =>Get module with quantization. [>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 187/187, 5.3 task/s, elapsed: 35s, ETA: 0s Formating bboxes of pts_bbox Start to convert detection format... [>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 187/187, 31.5 task/s, elapsed: 6s, ETA: 0s Results writes to /tmp/tmp0cofbf8i/results/pts_bbox/results_nusc.json Evaluating bboxes of pts_bbox mAP: 0.0950 mATE: 0.5646 mASE: 0.5516 mAOE: 1.2753 mAVE: 1.4863 mAAE: 0.6036 NDS: 0.1755 Eval time: 7.2s Per-class results: Object Class AP ATE ASE AOE AVE AAE car 0.647 0.262 0.209 0.322 4.019 0.371 truck 0.143 0.576 0.286 0.662 2.660 0.540 bus 0.000 0.549 0.376 2.477 1.075 0.604 trailer 0.000 1.000 1.000 1.000 1.000 1.000 construction_vehicle 0.002 0.707 0.325 1.050 0.519 0.444 pedestrian 0.056 0.161 0.476 1.710 0.900 0.484 motorcycle 0.000 1.000 1.000 1.000 1.000 1.000 bicycle 0.000 0.248 0.302 2.256 0.718 0.384 traffic_cone 0.101 0.142 0.542 nan nan nan barrier 0.000 1.000 1.000 1.000 nan nan |
まとめ
3D物体検出で学習したモデルをFPGAに向けて、量子化することが出来ました。
次の記事ではFPGAに使えるように、(半分失敗した)コンパイルまでの記事を紹介します。
Vitis AIでPytorchのcompileをしてみたメモ
今回の記事含めて、第6回AIエッジコンテストの一環でした。
下記にてコンテストでテスト・実施したことのまとめを紹介しています。


コメント