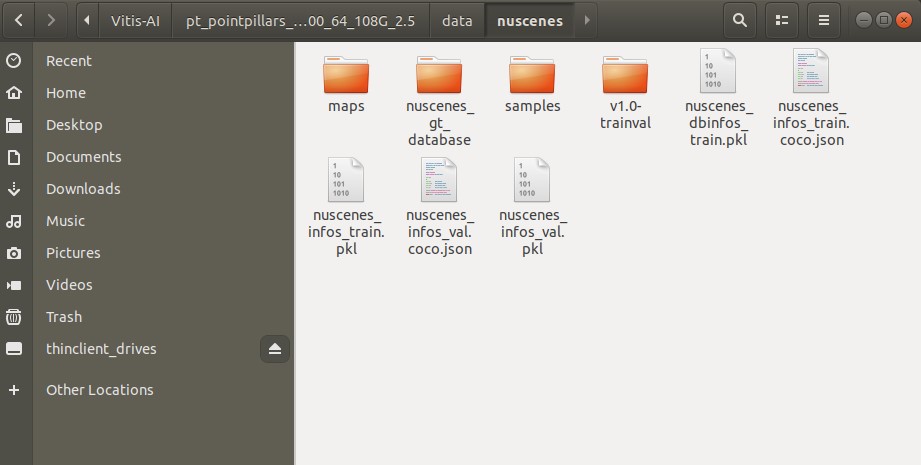
nuScenes形式のデータセットの学習前の前処理をしてみました。
3D物体検出をするために、LIDAR点群を処理しています。
データセットの入れ方から、プログラムの実行まで紹介します。
nuScenes formatのLidar点群の前処理をしてみたメモ
nuScenes形式のデータセットを取り扱ってみました。
第6回AIエッジコンテストのデータセットです。nuScenesのフォーマットでした。
自動車運転の画像・LIDAR点群で3D物体検出を行うことが目的です。
第6回AIエッジコンテストのデータセットにはnuScenesと違う箇所があります。
完全にはnuScenesとは同じで無いため、汎用のライブラリを使うとエラーになります。
- 速度情報が無いこと(nuScenesは有)
- 前方のカメラ・LIDAR情報しかない(nuScenesは複数のカメラが有)
エラーの内容・解決した方法含めて、紹介します。
実行環境
下記の環境で実行しました。
- Vitis AI 2.5 + nuScenes_PointPillarsのライブラリ
- 第6回AIエッジコンテストのデータセット
PC環境は下記となります。
- CPU…Core i5 6400
- GPU…NVIDIA GeForce GTX 1650
- メモリ…16GB
- SSD…500GB
nuScenes miniで動作確認済
同様なテスト環境下で、nuScenes miniにて前処理・評価・学習の動作を確認済です。
(nuScenes mini…4Gbyte程度の限定されたnuScenesのデータセット)
今回の記事との違いはデータセットの違いだけです。
Vitis AI上でのnuScenes_PointPillarsのライブラリでの実行例含めて説明しています。
詳細の環境に関しては下記記事をご確認お願いします。(リンク先はこちら)
mmdetection3dの環境でも確認済
今回はVitis AIの環境下で実行しています。
但し、Vitis AI(というDocker)上でmmdetection3dをインストールして実行しているだけです。
今回の前処理は単純にmmdetection3dだけをインストールしても対応できます。
また別の記事で紹介します。
nuScenes形式のLIDAR点群のデータを前処理します
予め、コンテストのデータセットのLIDAR情報(3d_labels)を用意します。
特に弄る必要はなく、「/data/nuscenes」に入れてもらえれば大丈夫でした。
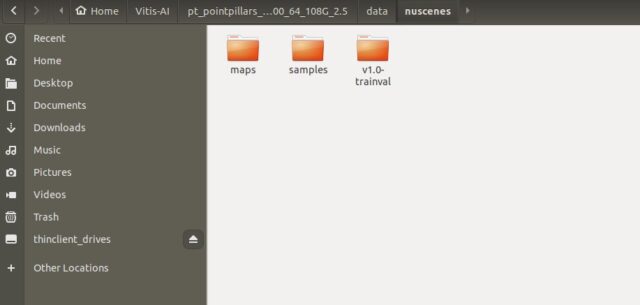
(今回は)sweepsを0にする
本来nuScenesには画像・LIDAR点群だけでなく、速度・マップなど多くのメタ情報が有ります。
線形補間することで、学習・評価に使うデータを増やすことが可能です。
本来のnuSceneのデータセットにはsweepsのフォルダ内にデータが入っていました。
但し、今回のコンテストのデータセットには速度が無いの無視しました。
(sweepsを有りにしても良いですが、データが増えて学習時間に影響します)
赤字の --max-sweeps 0 を追加してsweepsを無しにして、前処理を行います。
python code/mmdetection3d/tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes --max-sweeps 0
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
(vitis-ai-pt1_7) Vitis-AI /workspace/pt_pointpillars_nuscenes_40000_64_108G_2.5 > python code/mmdetection3d/tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes --max-sweeps 0 ====== Loading NuScenes tables for version v1.0-trainval... 20 category, 8 attribute, 4 visibility, 2176 instance, 2 sensor, 74 calibrated_sensor, 2475 ego_pose, 37 log, 37 scene, 2475 sample, 4950 sample_data, 42142 sample_annotation, 37 map, Done loading in 0.520 seconds. ====== Reverse indexing ... |
前方のカメラ・LIDARのみ処理する
今回、エラーで止まりました。前方右側のカメラの情報が無いとエラーがでます。
KeyError: 'CAM_FRONT_RIGHT'
コンテストのデータセットは前方にしかカメラ・LIDARがないためです。
|
1 2 3 4 5 6 7 8 9 10 |
[ ] 0/2475, elapsed: 0s, ETA:Traceback (most recent call last): File "code/mmdetection3d/tools/create_data.py", line 225, in <module> max_sweeps=args.max_sweeps) File "code/mmdetection3d/tools/create_data.py", line 55, in nuscenes_data_prep root_path, info_prefix, version=version, max_sweeps=max_sweeps) File "/workspace/pt_pointpillars_nuscenes_40000_64_108G_2.5/code/mmdetection3d/tools/data_converter/nuscenes_converter.py", line 74, in create_nuscenes_infos nusc, train_scenes, val_scenes, test, max_sweeps=max_sweeps) File "/workspace/pt_pointpillars_nuscenes_40000_64_108G_2.5/code/mmdetection3d/tools/data_converter/nuscenes_converter.py", line 202, in _fill_trainval_infos cam_token = sample['data'][cam] KeyError: 'CAM_FRONT_RIGHT' |
nuscenes_converter.pyを修正する
エラーが出たため下記の前処理のプログラムを弄ります。
「/code/mmdetection3d/tools/data_converter/nuscenes_converter.py」
前方カメラ・LIDAR情報のCAM_FRONT以外をコメントアウトしました。
def export_2d_annotation、def obtain_sensor2topの2か所同じ表記がありました。
|
1 2 3 4 5 6 7 8 9 |
# obtain 6 image's information per frame camera_types = [ 'CAM_FRONT', # 'CAM_FRONT_RIGHT', # 'CAM_FRONT_LEFT', # 'CAM_BACK', # 'CAM_BACK_LEFT', # 'CAM_BACK_RIGHT', ] |
再度実行すると、評価・学習に必要なデータの前処理が完了しました。
最後にテストデータが無いよとエラーが出ていますが、特に問題ないと思います。
コンテストには実際に試験するテストデータは用意されていないためです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
Create GT Database of NuScenesDataset [>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 2288/2288, 3.1 task/s, elapsed: 738s, ETA: 0s load 866 bicycle database infos load 12439 car database infos load 117 barrier database infos load 24 construction_vehicle database infos load 2431 pedestrian database infos load 1012 traffic_cone database infos load 2380 truck database infos load 178 motorcycle database infos load 4 animal database infos load 61 static_object.bicycle_rack database infos load 152 bus database infos load 5126 static.manmade database infos load 25 movable_object.debris database infos load 49 trailer database infos load 59 movable_object.pushable_pullable database infos load 1 human.pedestrian.personal_mobility database infos load 6 vehicle.emergency.police database infos Traceback (most recent call last): File "code/mmdetection3d/tools/create_data.py", line 233, in <module> max_sweeps=args.max_sweeps) File "code/mmdetection3d/tools/create_data.py", line 55, in nuscenes_data_prep root_path, info_prefix, version=version, max_sweeps=max_sweeps) File "/workspace/pt_pointpillars_nuscenes_40000_64_108G_2.5/code/mmdetection3d/tools/data_converter/nuscenes_converter.py", line 36, in create_nuscenes_infos nusc = NuScenes(version=version, dataroot=root_path, verbose=True) File "/home/vitis-ai-user/.local/lib/python3.7/site-packages/nuscenes/nuscenes.py", line 59, in __init__ assert osp.exists(self.table_root), 'Database version not found: {}'.format(self.table_root) AssertionError: Database version not found: ./data/nuscenes/v1.0-test |
無事学習・評価に必要なpklファイルが出来ています。
データベースのload情報数も、リファレンス環境で前処理したものと同じになりました。

まとめ
nuScenes形式の第6回AIエッジコンテストのデータセットでも前処理が出来ました。
次は少ないGPUメモリでも3D物体検出の学習を進めていきます。(リンク先はこちら)
今回の記事含めて、第6回AIエッジコンテストの一環でした。
下記にてコンテストでテスト・実施したことのまとめを紹介しています。

コメント