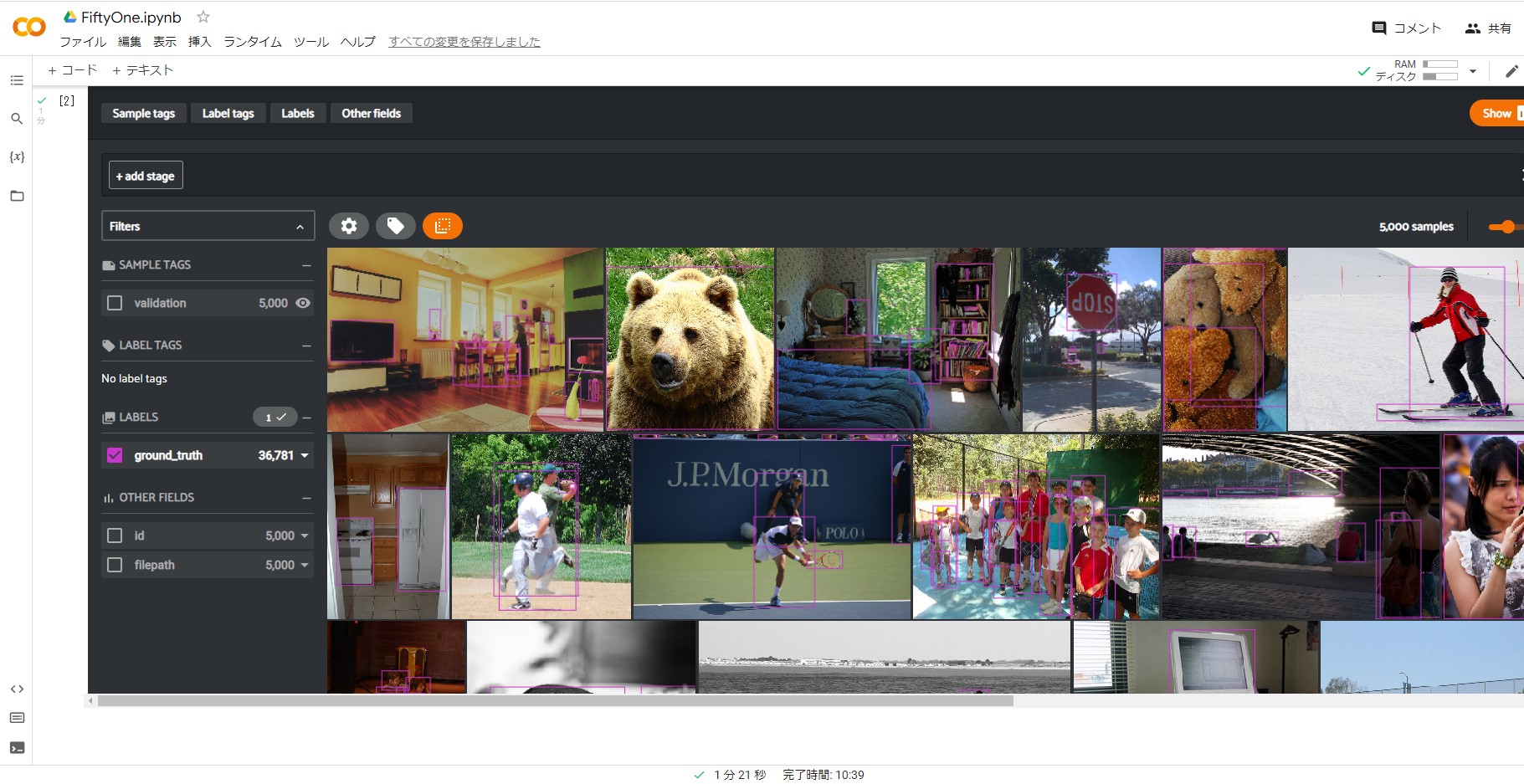
COCOのデータセットを簡単な使い方を紹介します。
Fifityoneというツールを使えば、任意のデータセットを簡単に作成可能です。
Colab上で動かしましたので、誰でも同様にテストできます。
COCOのデータセットの簡単な使い方!FiftyOneを試してみた
Fifityone を利用することで、COCOのデータセットを簡単に使うことが出来ました。
- 視覚的にデータセットの中身を確認できます。
- Colab上でも簡単に操作可能です。
- 必要なラベルを絞って、データセットを作成できます。
COCOの公式も紹介しているツールです。誰でも同様に実施できます。
Colab上での使用例含めて、詳細を紹介していきます。
COCOのデータセット
本来、COCOのデータセットは下記公式ページからダウンロードできます。

学習用(train)のデータセット含めると容量が20GB近くあります。
今回紹介するFiftyone以外にも、Linux上でのコマンドやAPIでも取得可能です。
参考記事
下記記事を参考にさせていただきました。非常に丁寧に記載されています。
作成者の方にこの場を借りてお礼申し上げます。

ColabでCOCOのデータセットを使用する
Google ColabでのFiftyOneを使ったCOCOの使用例を紹介します。
FiftyOneの公式ページは下記です

FiftyOne をインストールする
FiftyOneをインストールします。
但し、2022/5時点のColab環境だとopencv-python-headlessでエラーが出ました。
そのため、動作するバージョンを再インストールしています。
|
1 2 3 4 |
# FiftyOne をインストール # 2022/5時点でのopencv-python-headless 4.5.5.64では動作しないので4.5.4.60を再インストール !pip install fiftyone !pip install opencv-python-headless==4.5.4.60 |
COCOのデータセットを視覚的に確認する
FiftyOneを使ってCOCOのデータセットを確認してみます。
どのような写真でラベル分けされているのか、視覚的に分かります。
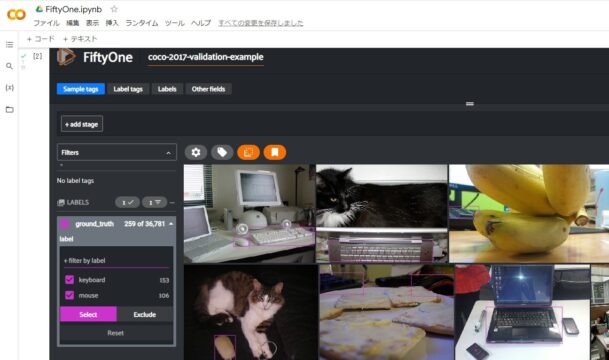
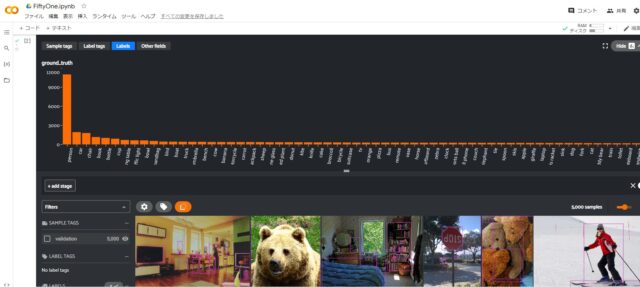
今回確認したのは、FiftyOneのサンプルコードそのままでvalidation(検証用)データです。
split="train"にすれば学習(train)データもダウンロード可能でした。
但し容量が20GB近いのでご注意下さい。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
#split="train"にすれば学習(train)データもダウンロード可能だが、容量が20GB近いので実施しない #サンプルコードのままsplit="validation"の検証用データを表示 import fiftyone as fo import fiftyone.zoo as foz # List available zoo datasets print(foz.list_zoo_datasets()) # # Load the COCO-2017 validation split into a FiftyOne dataset # # This will download the dataset from the web, if necessary # dataset = foz.load_zoo_dataset("coco-2017", split="validation") # Give the dataset a new name, and make it persistent so that you can # work with it in future sessions dataset.name = "coco-2017-validation-example" dataset.persistent = True # Visualize the in the App session = fo.launch_app(dataset) |
COCOのデータセットを出力する
COCOの形式でデータセットを出力します。
ダウンロードした5000個の検証用データをそのまま出力できます。
下記だと、写真が詰まったdataフォルダとCOCO形式のlabel.jsonが出力されます。
|
1 2 3 4 5 |
#検証用データを出力 dataset.export( export_dir=f"/content/COCO", dataset_type=fo.types.COCODetectionDataset, ) |
ラベル分けして出力する
データセットを全て使うと、学習に時間が掛かりますのでデータを減らしています。
そして"book", "bottle", "cup"の3つのラベルのみをCOCO形式で出力しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
classes = ["book", "bottle", "cup"] train_dataset = dataset[:700] val_dataset = dataset[700:800] test_dataset = dataset[800:1000] # COCO形式でエクスポート train_dataset.export( export_dir=f"/content/data/train/", dataset_type=fo.types.COCODetectionDataset, split="train", classes=classes, ) val_dataset.export( export_dir=f"/content/data/val/", dataset_type=fo.types.COCODetectionDataset, split="val", classes=classes, ) test_dataset.export( export_dir=f"/content/data/test/", dataset_type=fo.types.COCODetectionDataset, split="test", classes=classes, ) |
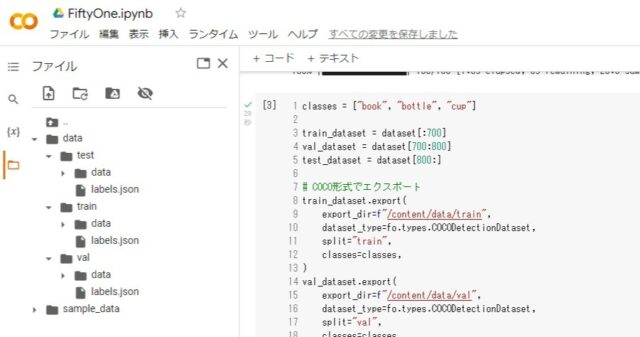
実行後は下記のように各フォルダ(train,val,test)が作られます。
写真が詰まったdataフォルダとCOCO形式のlabel.jsonが出力されます。
まとめ
FiftyOneでCOCOのデータセットを簡単に使い方を紹介させていただきました。
次の記事では入手したデータを利用して、YOLOXの学習まで実施しています。
是非一緒にご覧ください。(リンク先はこちら)
コメント