Vitis AIでKITTIとPointPillarsの機械学習を試してみました。
データセットの用意からFPGAへの量子化までの動作確認をしています。
その際にエラー出た内容含めて紹介します。
KITTIとPointPillarsをVitis AIのサンプルを調べたメモ
自動車の物体検出のデータセット(画像+LIDAR)であるKITTIを試してみました。
PointPillarsというLIDAR点群からの3D物体検出の処理をテストしてます。
FPGAの開発環境であるVitis-AIにサンプルがありますので、学習・量子化してみました。
基本的には下記のVitis AI 2.5のサンプルに沿って手順を実行しています。
yamlに記載している「type: float & quantized」のリンク先から入手できます。
|
1 2 |
wget https://www.xilinx.com/bin/public/openDownload?filename=pt_pointpillars_kitti_12000_100_10.8G_2.5.zip unzip openDownload\?filename\=pt_pointpillars_kitti_12000_100_10.8G_2.5.zip |
Vitis AIのPointpillarsはSECONDがベース
自動車のLIDAR点群の情報から3D物体検出するアルゴリズムと言っても数多くあります。
今回の処理はSECONDというものがベースになっています。
(SECOND: Sparsely Embedded Convolutional Detection)
正直、筆者は上手く説明できないのですが下記のQiita記事が分かりやすいと思います。
https://qiita.com/minh33/items/d0a67a8f253bde0cae14
SECONDの中でも色々な処理がある
Pytorch+SECONDだと下記のGithubの下記が一番有名かと思います。
TTIのデータセットだけでなく、nuScenesにも対応しています。
https://github.com/traveller59/second.pytorch
mmdetection3dというの最新の3D物体検出のライブラリにも組み込まれています。
(むしろ、古いVerが残っている感じです。第6回AIエッジコンテストのベースもこれです。)
今回のVitis AIのサンプル元は、上記のからフォークされた1つです。
https://github.com/nutonomy/second.pytorch
更にFPGAへの実装(量子化)ができるようにアレンジされています。
コンフィグファイルを見比べると、デフォルトのSECONDの設定が大きく違います。
SECONDの大きな3つのモジュールから異なっています。
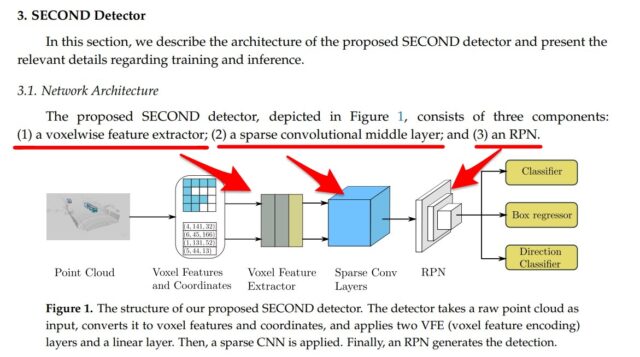
下記SECONDの論文の一部・図を引用させていただいています。
https://pdfs.semanticscholar.org/5125/a16039cabc6320c908a4764f32596e018ad3.pdf
・SimpleVoxelRadius ←大元のリポジストリ(第6回AIエッジコンテストのリファレンス)
・PillarFeatureNet ←フォークされたリポジストリ(Vitis AIは更に改良)
・SpMiddleFHD ←大元のリポジストリ(第6回AIエッジコンテストのリファレンス)
・PointPillarsScatter ←フォークされたリポジストリ(Vitis AIは更に改良)
・RPNV2 ←大元のリポジストリ(第6回AIエッジコンテストのリファレンス)
・RPN ←フォークされたリポジストリ(Vitis AIは更に改良)
Vitis AIでは量子化が出来ても…
Vitis AIのSECONDは、Githubに置かれているSECONDと何かしら差分があります。
今回サンプルに沿う形で量子化まで出来ていますが、あくまで一例です。
(他のGithubのSECONDでも簡単にFPGAの量子化ができるという訳ではなしです…)
※また別の記事で紹介したいと思います。
Vitis AIのサンプル通り学習→量子化を試してみる
Vitis AIのインストールや環境構築ついては下記記事で紹介しています。
VItis AI 2.5やPetaLinuxなどインストールしてみたメモ
README.mdを見て環境を整えます
README.mdに従ってKITTIのデータセットのダウンロードまで行います。
またVitis AIのGPU版のdocker上でcuda-toolkitの11.0とnvccが要求されています。
下記記事で紹介したように、Conda環境を入れ替えて対応します。
Vitis AIでPytorchのConda環境を新しく構築してみた

Conda環境を入れ替えるスクリプトはdocker/dockerfiles/replace_pytorch.shにあります。
但しデフォルトだとcuda-toolkitの10.2になってしまいます。
そのため下記のようにcuda-toolkitの11.0をインストールするように書き直します。
cudatoolkit=10.2 → cudatoolkit=11.0
|
1 2 3 4 |
#### Installing pytorch 1.7.1 packages ...torchvision==0.5.0+cu100 -f https://download.pytorch.org/whl/torch_stable.html if [ -d "/usr/local/cuda" ]; then mamba install -y pytorch==1.7.1 cudatoolkit=11.0 -c pytorch pip install torchvision==0.8.2 |
Vitis AI上での実行したコマンド
前処理・学習・量子化・コンパイルまでスクリプトになっています。
README.mdに従って実行すれば実施できます。下記が実施したコマンドです。
最初にnvccが動かせるようにcuda-toolokit-11-0を入れています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
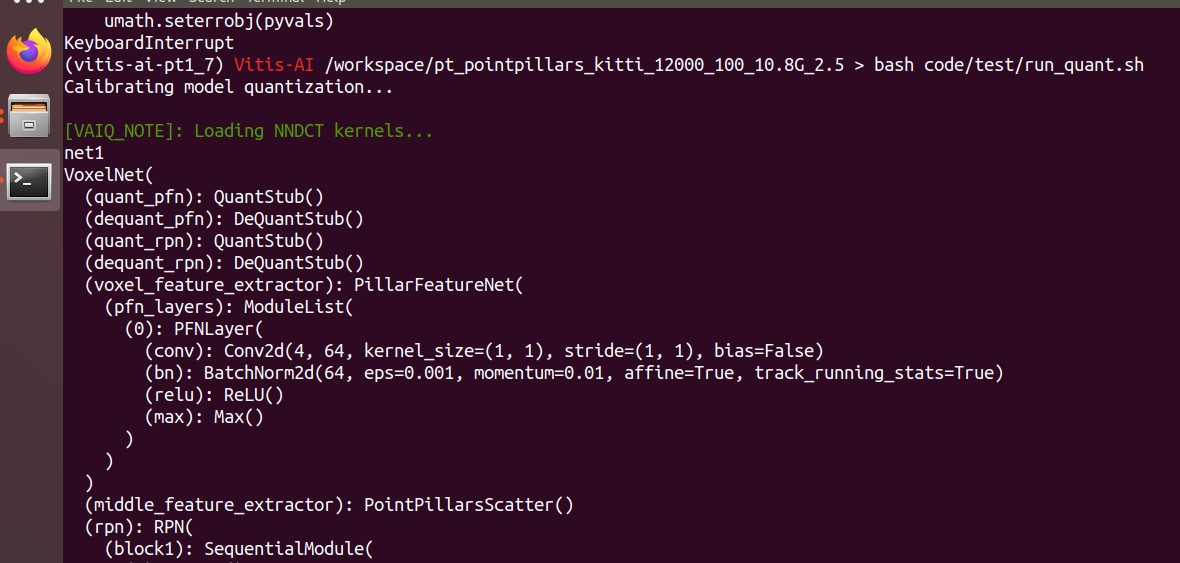
(vitis-ai-pt1_7) Vitis-AI /workspace/pt_pointpillars_kitti_12000_100_10.8G_2.5 > history 1 conda activate vitis-ai-pytorch 2 wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin 3 sudo mv cuda-ubuntu1804.pin /etc/apt/preferences.d/cuda-repository-pin-600 # wget http://developer.download.nvidia.com/compute/cuda/11.0.2/local_installers/cuda-repo-ubuntu1804-11-0-local_11.0.2-450.51.05-1_amd64.deb 4 sudo dpkg -i cuda-repo-ubuntu1804-11-0-local_11.0.2-450.51.05-1_amd64.deb 5 sudo apt-key add /var/cuda-repo-ubuntu1804-11-0-local/7fa2af80.pub 6 sudo apt-get update 7 sudo apt-get install -y cuda-toolkit-11-0 8 sh docker/dockerfiles/replace_pytorch_11.sh vitis-ai-pt1_7 9 conda activate vitis-ai-pt1_7 10 cd pt_pointpillars_kitti_12000_100_10.8G_2.5/ 11 pip install --user -r requirements.txt 12 sudo apt-get update && sudo apt-get install cuda-toolkit-11-0 13 export CUDA_HOME=/usr/local/cuda 14 export NUMBAPRO_CUDA_DRIVER=/usr/lib/x86_64-linux-gnu/libcuda.so 15 export NUMBAPRO_LIBDEVICE=${CUDA_HOME}/nvvm/libdevice 16 export NUMBAPRO_NVVM=${CUDA_HOME}/nvvm/lib64/libnvvm.so 17 sudo update-alternatives --config gcc 18 bash code/test/prepare_data.sh 19 bash code/test/run_eval.sh 20 bash code/train/run_train.sh 21 bash code/test/run_quant.sh ~~ここから先はあまり確認していません~~ ## bash code/qat/run_qat.sh ## bash code/qat/convert_test_qat.sh |
※筆者はあくまでサンプルの流れを確認した程度です。
長すぎる学習(run_train.sh)などは途中で止めています。
また量子化(run_quant.sh)してxmodelを出力した後の処理までは未確認です。
エラー出た内容
スクリプトを動かしていく上で出たエラーを数点紹介します。
No module named 'utils.non_max_suppression.nms'
non_max_suppression のライブラリを最初に使うときに一度コンパイルしている様子です。
そこでエラーが出ていた内容でした。(長いエラーのため一部切り取りです。)
RuntimeError: ('compile failed with retcode', 1)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
~~~~~~~~~~~~~~~~~~~~~ ../cc/nms/nms_cpu.h:165:26: note: ‘std::cout’ is defined in header ‘<iostream>’; did you forget to ‘#include <iostream>’? concurrent.futures.process._RemoteTraceback: """ Traceback (most recent call last): File "/workspace/pt_pointpillars_kitti_12000_100_10.8G_2.5/code/test/utils/non_max_suppression/nms_cpu.py", line 46, in <module> from .nms import ( ModuleNotFoundError: No module named 'utils.non_max_suppression.nms' During handling of the above exception, another exception occurred: Traceback (most recent call last): File "/opt/vitis_ai/conda/envs/vitis-ai-pt1_7/lib/python3.7/concurrent/futures/process.py", line 239, in _process_worker r = call_item.fn(*call_item.args, **call_item.kwargs) File "/opt/vitis_ai/conda/envs/vitis-ai-pt1_7/lib/python3.7/concurrent/futures/process.py", line 198, in _process_chunk return [fn(*args) for args in chunk] File "/opt/vitis_ai/conda/envs/vitis-ai-pt1_7/lib/python3.7/concurrent/futures/process.py", line 198, in <listcomp> return [fn(*args) for args in chunk] File "/workspace/pt_pointpillars_kitti_12000_100_10.8G_2.5/code/test/utils/buildtools/command.py", line 291, in compile_func raise RuntimeError("compile failed with retcode", ret.returncode) RuntimeError: ('compile failed with retcode', 1) ~~~~~~~~~~~~~~~~~~~~~~~ |
エラー内容に下記メッセージがありました。
../cc/nms/nms_cpu.h:165:26: note: ‘std::cout’ is defined in header ‘<iostream>’; did you forget to ‘#include <iostream>’?
確かnms_cpu.h含めて何か所か同様なメッセージが出てきます。
そのためエラー出た.hファイルに#include <iostream>を追記すると、エラーが消えました。
RuntimeError: CUDA out of memory
train(学習)とかqat(量子化後の精度向上)などCUDAメモリを食います。
筆者のGPUボードはGTX1650です。メモリ4GBです
KITTIのデータセットでも厳しく、必要に応じてバッチサイズなどを調整していました。
|
1 |
RuntimeError: CUDA out of memory. Tried to allocate 244.00 MiB (GPU 0; 3.82 GiB total capacity; 2.46 GiB already allocated; 124.44 MiB free; 2.83 GiB reserved in total by PyTorch) |
量子化後の評価値も大体一致した
量子化のスクリプトした結果も貼り付けておきます。
README.mdに各Performance値も記載していましたが、特に大きくは違いありません。
特に問題なくテスト出来ていたようです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 |
(vitis-ai-pt1_7) Vitis-AI /workspace/kitti_pt_pointpillars_kitti_12000_100_10.8G_2.5 > bash code/test/run_quant.sh Calibrating model quantization... [VAIQ_NOTE]: Loading NNDCT kernels... Restoring parameters from float/pointpillars.tckpt remain number of infos: 3769 [VAIQ_NOTE]: Quant config file is empty, use default quant configuration [VAIQ_NOTE]: Quantization calibration process start up... [VAIQ_NOTE]: =>Quant Module is in 'cuda'. [VAIQ_NOTE]: =>Parsing VoxelNet... [VAIQ_NOTE]: Start to trace model... [VAIQ_NOTE]: Finish tracing. [VAIQ_NOTE]: Processing ops... ██████████████████████████████████████████████████| 103/103 [00:00<00:00, 2168.96it/s, OpInfo: name = return_0, type = Return] [VAIQ_WARN]: The quantizer recognize new op `equal` as a float operator by default. [VAIQ_WARN]: The quantizer recognize new op `select` as a float operator by default. [VAIQ_WARN]: The quantizer recognize new op `stack` as a float operator by default. [VAIQ_WARN]: The quantizer recognize new op `index_put_inplace` as a float operator by default. [VAIQ_WARN]: The quantizer recognize new op `index` as a float operator by default. [VAIQ_NOTE]: =>Doing weights equalization... [VAIQ_NOTE]: =>Quantizable module is generated.(quantized/VoxelNet.py) [VAIQ_NOTE]: =>Get module with quantization. Generate output labels... Car AP@0.70, 0.70, 0.70:====>][2.48it/s][25:19>00:00] bbox AP:90.33, 80.52, 78.50 bev AP:89.66, 79.59, 76.45 3d AP:76.02, 64.65, 57.77 aos AP:90.20, 79.93, 77.43 Car AP@0.70, 0.50, 0.50: bbox AP:90.33, 80.52, 78.50 bev AP:90.82, 87.85, 85.37 3d AP:90.81, 87.60, 83.24 aos AP:90.20, 79.93, 77.43 Cyclist AP@0.50, 0.50, 0.50: bbox AP:71.08, 55.63, 52.28 bev AP:68.82, 50.20, 47.47 3d AP:61.32, 46.45, 43.39 aos AP:66.14, 50.63, 47.59 Cyclist AP@0.50, 0.25, 0.25: bbox AP:71.08, 55.63, 52.28 bev AP:71.90, 56.14, 53.75 3d AP:71.87, 55.58, 52.74 aos AP:66.14, 50.63, 47.59 Pedestrian AP@0.50, 0.50, 0.50: bbox AP:47.61, 44.38, 41.61 bev AP:51.37, 46.82, 43.04 3d AP:44.29, 38.55, 35.24 aos AP:26.98, 25.77, 24.50 Pedestrian AP@0.50, 0.25, 0.25: bbox AP:47.61, 44.38, 41.61 bev AP:60.13, 56.86, 53.49 3d AP:60.10, 56.29, 53.07 aos AP:26.98, 25.77, 24.50 Car coco AP@0.50:0.05:0.95: bbox AP:66.54, 60.66, 58.02 bev AP:63.49, 58.82, 56.04 3d AP:52.40, 46.60, 43.60 aos AP:66.45, 60.18, 57.18 Cyclist coco AP@0.25:0.05:0.70: bbox AP:62.79, 49.80, 47.41 bev AP:58.68, 44.54, 42.17 3d AP:52.92, 40.31, 37.91 aos AP:58.45, 45.39, 43.14 Pedestrian coco AP@0.25:0.05:0.70: bbox AP:42.52, 39.93, 38.26 bev AP:43.44, 40.21, 37.61 3d AP:39.45, 36.22, 33.87 aos AP:24.33, 23.44, 22.67 [VAIQ_NOTE]: =>Exporting quant config.(quantized/quant_info.json) Testing quantized model... [VAIQ_NOTE]: Loading NNDCT kernels... Restoring parameters from float/pointpillars.tckpt remain number of infos: 3769 [VAIQ_NOTE]: Quant config file is empty, use default quant configuration [VAIQ_NOTE]: Quantization test process start up... [VAIQ_NOTE]: =>Quant Module is in 'cuda'. [VAIQ_NOTE]: =>Parsing VoxelNet... [VAIQ_NOTE]: Start to trace model... [VAIQ_NOTE]: Finish tracing. [VAIQ_NOTE]: Processing ops... ██████████████████████████████████████████████████| 103/103 [00:00<00:00, 2191.47it/s, OpInfo: name = return_0, type = Return] [VAIQ_WARN]: The quantizer recognize new op `index_put_inplace` as a float operator by default. [VAIQ_WARN]: The quantizer recognize new op `select` as a float operator by default. [VAIQ_WARN]: The quantizer recognize new op `equal` as a float operator by default. [VAIQ_WARN]: The quantizer recognize new op `stack` as a float operator by default. [VAIQ_WARN]: The quantizer recognize new op `index` as a float operator by default. [VAIQ_NOTE]: =>Doing weights equalization... [VAIQ_NOTE]: =>Quantizable module is generated.(quantized/VoxelNet.py) [VAIQ_NOTE]: =>Get module with quantization. Generate output labels... Car AP@0.70, 0.70, 0.70:====>][9.61it/s][06:28>00:00] bbox AP:90.30, 80.50, 78.66 bev AP:89.52, 79.48, 76.59 3d AP:76.02, 64.63, 57.70 aos AP:90.17, 79.96, 77.60 Car AP@0.70, 0.50, 0.50: bbox AP:90.30, 80.50, 78.66 bev AP:90.78, 88.03, 85.34 3d AP:90.75, 87.04, 83.44 aos AP:90.17, 79.96, 77.60 Cyclist AP@0.50, 0.50, 0.50: bbox AP:70.74, 54.59, 52.43 bev AP:65.26, 49.71, 46.97 3d AP:59.25, 45.00, 42.49 aos AP:66.29, 49.66, 47.51 Cyclist AP@0.50, 0.25, 0.25: bbox AP:70.74, 54.59, 52.43 bev AP:71.85, 56.41, 53.31 3d AP:71.82, 55.10, 52.32 aos AP:66.29, 49.66, 47.51 Pedestrian AP@0.50, 0.50, 0.50: bbox AP:48.22, 44.23, 42.22 bev AP:50.95, 46.15, 42.53 3d AP:42.67, 38.13, 34.57 aos AP:27.46, 25.94, 24.94 Pedestrian AP@0.50, 0.25, 0.25: bbox AP:48.22, 44.23, 42.22 bev AP:60.33, 56.41, 53.51 3d AP:60.30, 56.36, 53.40 aos AP:27.46, 25.94, 24.94 Car coco AP@0.50:0.05:0.95: bbox AP:66.67, 60.99, 58.19 bev AP:63.48, 58.86, 56.04 3d AP:52.55, 46.78, 43.81 aos AP:66.58, 60.54, 57.38 Cyclist coco AP@0.25:0.05:0.70: bbox AP:61.04, 49.02, 46.88 bev AP:57.81, 44.11, 41.82 3d AP:51.76, 39.53, 37.33 aos AP:57.43, 44.69, 42.61 Pedestrian coco AP@0.25:0.05:0.70: bbox AP:42.34, 39.77, 38.07 bev AP:43.37, 39.94, 37.52 3d AP:38.47, 35.25, 32.90 aos AP:24.46, 23.55, 22.67 Dumping xmodel... [VAIQ_NOTE]: Loading NNDCT kernels... Restoring parameters from float/pointpillars.tckpt remain number of infos: 3769 [VAIQ_NOTE]: Quant config file is empty, use default quant configuration [VAIQ_NOTE]: Quantization test process start up... [VAIQ_NOTE]: =>Quant Module is in 'cpu'. [VAIQ_NOTE]: =>Parsing VoxelNet... [VAIQ_NOTE]: Start to trace model... [VAIQ_NOTE]: Finish tracing. [VAIQ_NOTE]: Processing ops... ██████████████████████████████████████████████████| 103/103 [00:00<00:00, 2185.14it/s, OpInfo: name = return_0, type = Return] [VAIQ_WARN]: The quantizer recognize new op `equal` as a float operator by default. [VAIQ_WARN]: The quantizer recognize new op `index` as a float operator by default. [VAIQ_WARN]: The quantizer recognize new op `stack` as a float operator by default. [VAIQ_WARN]: The quantizer recognize new op `index_put_inplace` as a float operator by default. [VAIQ_WARN]: The quantizer recognize new op `select` as a float operator by default. [VAIQ_NOTE]: =>Doing weights equalization... [VAIQ_NOTE]: =>Quantizable module is generated.(quantized/VoxelNet.py) [VAIQ_NOTE]: =>Get module with quantization. Generate output labels... [0.027%][....................][0.16it/s][00:06>06:40:18] [VAIQ_NOTE]: =>Converting to xmodel ... [VAIQ_NOTE]: =>Dumping 'VoxelNet_0'' checking data... [VAIQ_WARN]: Only dump first output of multi-output node:'VoxelNet::VoxelNet/PillarFeatureNet[voxel_feature_extractor]/PFNLayer[pfn_layers]/ModuleList[0]/Max[max]/inputs.2(max)'. [VAIQ_WARN]: Only dump first output of multi-output node:'VoxelNet::VoxelNet/PillarFeatureNet[voxel_feature_extractor]/PFNLayer[pfn_layers]/ModuleList[0]/Max[max]/inputs.2(max)'. [VAIQ_NOTE]: =>Finsh dumping data.(quantized/deploy_check_data_int/VoxelNet_0) [VAIQ_NOTE]: =>Dumping 'VoxelNet_1'' checking data... [VAIQ_NOTE]: =>Finsh dumping data.(quantized/deploy_check_data_int/VoxelNet_1) [VAIQ_NOTE]: =>Successfully convert 'VoxelNet_0' to xmodel.(quantized/VoxelNet_0_int.xmodel) [VAIQ_NOTE]: =>Successfully convert 'VoxelNet_1' to xmodel.(quantized/VoxelNet_1_int.xmodel) |
まとめ
テストとしては、あくまでサンプルのスクリプトに沿って実行した形となりました。
ただVitis AI上でのSECONDの中身含めて、確認することが出来ました。
次はVitis AIのサンプルにはない量子化ができるか試してみた内容を紹介します。
(結果は失敗ですが…)
Vitis-AI Quantizer(量子化)の3D物体検出に失敗したメモ
今回の記事含めて、第6回AIエッジコンテストの一環でした。
下記にてコンテストでテスト・実施したことのまとめを紹介しています。

コメント