Vitis-AIのサンプル・ライブラリにないFPGAの量子化(Quantizer)を試してみました。
ただ3D物体検出(pointpainting)の対応は難しく失敗に終わりました。
忘備録として一連の流れを紹介します。
Vitis-AI Quantizer(量子化)の3D物体検出に失敗したメモ
XilinxのFPGAで3D物体検出(pointpainting)が出来るように量子化を試してみました。
テストしたのは第6回AIエッジコンテストのリファレンス環境です。
ただVitis AIがサンプルで用意されている量子化とは、(筆者にとって)難易度が別物でした。
結局失敗に終わりましたが、色々と試した内容をブログ記事として残したいと思います。
本当に超個人的な失敗メモです。あくまで参考までにお願いします
3D物体検出を量子化したい理由
筆者が第6回AIエッジコンテストに参加していました。
自動車の画像+LIDAR点群データからの3D物体検出をFPGAで実装する必要が有りました。
(ちなみにRISC-Vの実装も取り入れないといけない…)
また公式からリファレンス環境(3D物体検出のプログラム)が用意されていました。
下記のようにdocker・Colab上では簡単にテスト実行できるようになっています。
そのため、リファレンス環境をFPGA向けに量子化すれば一番楽では…と考えたためです。
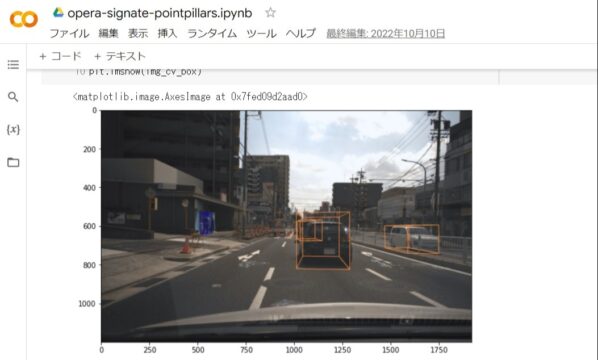
実行環境
あくまで下記の環境の一例です。
- Vitis AI 2.5
- spconv v1.2.1
- 第6回AIエッジコンテストのリファレンス環境(SECOND)
Vitis AIのdocker上で、第6回AIエッジコンテストのリファレンス環境は動作確認済です。
下記記事で対応した内容を紹介しています。(リンク先はこちら)
spconvの古いVer1.2.1のインストールが苦労したメモ
第6回AIエッジコンテストのリファレンス環境(SECOND)は下記です。
https://github.com/pometa0507/6th-ai-reference2
Vitis AIのインストール・GPUのdocker環境については下記記事で紹介しています。
VItis AI 2.5やPetaLinuxなどインストールしてみたメモ
Vitis AIの3D物体検出のサンプルを参考にする
Vitis AI 2.5には3D物体検出のサンプルが複数用意されていました。
下記3つはリファレンスと同じくSECONDという3D物体検出の処理が使われています。
(SECOND: Sparsely Embedded Convolutional Detection)
- PointPillars + KITTI ←リファレンス環境のコードに一番近い形
- PointPillars + nuScenes ←mmdetection3dがベース
- PointPainting + nuScenes ←mmdetection3dをベース
第6回AIエッジコンテストのデータセットはnuScenes形式でした。(KITTI形式ではなし)
またリファレンス環境も画像と点群データを利用するPointPaintingの処理でした。
処理だけ見ると「3.PointPainting + nuScenes」がリファレンスに近いです。
ただ2.3はmmdetection3dというライブラリ経由でSECONDが利用されています。
コード的には「1.PointPillars + KITTI」がリファレンス環境に近い形です。
(リファレンス環境が、「1」のフォーク元になっているリポジストリをベースにしています)
結局のところ3つのサンプルを全て参考にさせてもらいました。
ただ量子化としてのコードとして一番見たのは「1.PointPillars + KITTI」でした。
(最終的には2,3も使いました。また別の記事で紹介します)
ただしサンプルをそのまま流用できない…
Vitis AIのサンプルと第6回AIエッジコンテストのリファレンス環境には差分があります
Vitis AIのSECONDについては下記記事で調べて、紹介しています。
KITTIとPointPillarsのVitis AIのサンプルを調べたメモ
SECOND内の大きな3つのモジュールから異なっています。
Vitis AIのサンプルは参考には出来ますが、コードをそのまま流用はできない形です。
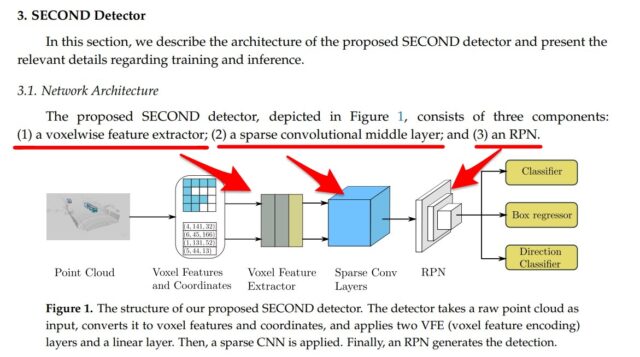
下記SECONDの論文の一部・図を引用させていただいています。
https://pdfs.semanticscholar.org/5125/a16039cabc6320c908a4764f32596e018ad3.pdf
・SimpleVoxelRadius ←大元のリポジストリ(第6回AIエッジコンテストのリファレンス)
・PillarFeatureNet ←フォークされたリポジストリ(Vitis AIは更に改良)
・SpMiddleFHD ←大元のリポジストリ(第6回AIエッジコンテストのリファレンス)
・PointPillarsScatter ←フォークされたリポジストリ(Vitis AIは更に改良)
・RPNV2 ←大元のリポジストリ(第6回AIエッジコンテストのリファレンス)
・RPN ←フォークされたリポジストリ(Vitis AIは更に改良)
量子化(quantizer)の処理を試してみる
Vitis AIの量子化に関してはVitis AIの公式ドキュメントにも記載されています。
またpointpillarsの量子化の事例も紹介されています。
https://docs.xilinx.com/r/2.5-English/ug1414-vitis-ai/Pytorch-Custom-OP-Model-Example
pytorchでモデルや重みなど設定した後、下記量子化(torch_quantizer)の関数に入れていきます。
下記はVitis AIのサンプルのpointpillarsの量子化例です
|
1 2 3 4 5 6 7 8 9 10 11 12 |
if quant_mode != 'float': max_voxel_num = config.eval_input_reader.max_number_of_voxels max_point_num_per_voxel = model_cfg.voxel_generator.max_number_of_points_per_voxel aug_voxels = torch.randn((1, 4, max_voxel_num, max_point_num_per_voxel)).to(device) coors = torch.randn((max_voxel_num, 4)).to(device) quantizer = torch_quantizer(quant_mode=quant_mode, module=net, input_args=(aug_voxels, coors), output_dir=output_dir, device=device, ) net = quantizer.quant_model |
SECONDのtrain.pyをベースに作る
一から量子化のプログラムを作るのは手間です。
そのためSECONDの評価(学習)のプログラム(train.py)を流用していきます
第6回AIエッジコンテストのリファレンス環境だと下記です。
https://github.com/pometa0507/6th-ai-reference2/blob/master/second.pytorch/second/pytorch/train.py
train.pyの中はdef でevaluate(評価)の関数がありますので、コピーしてベースにしました。
pytorchでモデル・データセットが作成されて、config設定が終わった箇所で量子化をします。
プログラムの一部ですが、下記感じで変数を合わせて実行しました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
quant_mode='calib' if quant_mode != 'float': quant_dir = '../quantized' max_voxel_num = config.eval_input_reader.preprocess.max_number_of_voxels max_point_num_per_voxel = model_cfg.voxel_generator.max_number_of_points_per_voxel voxels = torch.randn((max_voxel_num, max_point_num_per_voxel, 7)).to(device) coors = torch.randn((max_voxel_num, 4)).to(device) quantizer = torch_quantizer(quant_mode=quant_mode, module=net, input_args=(voxels, coors), output_dir=quant_dir, device=device, ) net = quantizer.quant_model |
プログラムの頭には量子化関連のimportも追加します。
|
1 2 3 |
import pytorch_nndct import torch from pytorch_nndct.apis import torch_quantizer |
実行すると(一応)量子化の関数(quantizer)が動き出します。
ただVitis AIのサンプル同様にvoxelとcoorsの変数を入れるだけではエラーが出ました。
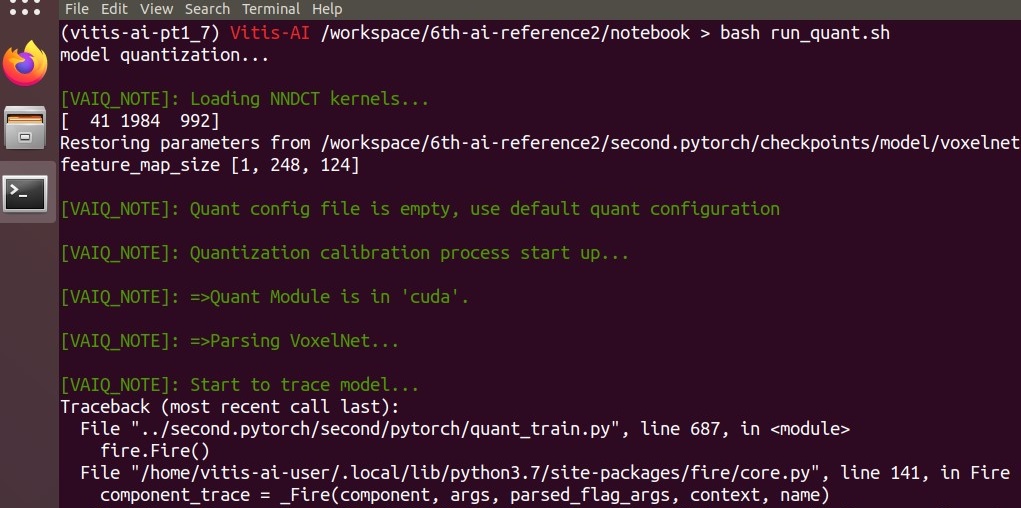
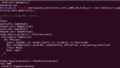
エラーの最後の所の切り取りです。
モジュール(モデル)へforward(前処理)の引数が合っていないよ。ということでした。
量子化のために、単純に正規分布の変数として入れるだけでは駄目でした。
|
1 2 3 4 5 6 7 8 9 |
File "/home/vitis-ai-user/.local/lib/python3.7/site-packages/torch/jit/_trace.py", line 130, in forward self._force_outplace, File "/home/vitis-ai-user/.local/lib/python3.7/site-packages/torch/jit/_trace.py", line 116, in wrapper outs.append(self.inner(*trace_inputs)) File "/home/vitis-ai-user/.local/lib/python3.7/site-packages/torch/nn/modules/module.py", line 725, in _call_impl result = self._slow_forward(*input, **kwargs) File "/home/vitis-ai-user/.local/lib/python3.7/site-packages/torch/nn/modules/module.py", line 709, in _slow_forward result = self.forward(*input, **kwargs) TypeError: forward() takes 2 positional arguments but 3 were given |
voxelnet.pyも修正する
SECONDでは座標からVoxel化(Voxelnet.py)しています。
量子化の際にも下記Voxelnet.pyのdef foward箇所を通過していました。
リファレンス環境では、Vitis AIのサンプルのようにVoxelへの座標だけでは駄目でした。
(よく考えたら、nuScenesのデータは多くのメタ情報持っているから当然か…)
多くの情報をまとめた構造で渡す必要があります。
本来リファレンス環境のVoxelnet.pyに引き渡すデータは下記のようなdict構造です。
voxels,num_points,num_voxels…など多くの情報が入った形です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
{'voxels': tensor([[[ 3.8857e+01, 3.0844e+01, 1.3182e+00, ..., 9.9577e-01, 3.8643e-03, 3.7033e-04], [ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00, 0.0000e+00, 0.0000e+00], [ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00, 0.0000e+00, 0.0000e+00], [ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00, 0.0000e+00, 0.0000e+00], [ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00, 0.0000e+00, 0.0000e+00]], ..., [[ 2.8821e+01, -1.7415e+01, -9.9234e-01, ..., 2.8959e-01, 7.0863e-01, 1.7776e-03], [ 2.8821e+01, -1.7415e+01, -9.9234e-01, ..., 2.8959e-01, 7.0863e-01, 1.7776e-03], [ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00, 0.0000e+00, 0.0000e+00], [ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00, 0.0000e+00, 0.0000e+00], [ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00, 0.0000e+00, 0.0000e+00]]], device='cuda:0'), 'num_points': tensor([1, 2, 1, ..., 2, 2, 2], device='cuda:0', dtype=torch.int32), 'coordinates': tensor([[ 0, 31, 1608, 777], [ 0, 26, 1507, 648], [ 0, 30, 1512, 656], ..., [ 2, 20, 649, 576], [ 2, 20, 647, 574], [ 2, 20, 643, 576]], device='cuda:0', dtype=torch.int32), 'num_voxels': tensor([[15147], [15151], [15049]]), 'metrics': [{'voxel_gene_time': 0.002718210220336914, 'prep_time': 0.002747774124145508}, {'voxel_gene_time': 0.0027320384979248047, 'prep_time': 0.002760171890258789}, {'voxel_gene_time': 0.0026803016662597656, 'prep_time': 0.00270843505859375}], 'anchors': tensor([[[ 0.0000, -49.6000, -0.9390, ..., 3.9000, 1.5600, 0.0000], [ 0.4033, -49.6000, -0.9390, ..., 3.9000, 1.5600, 0.0000], [ 0.8065, -49.6000, -0.9390, ..., 3.9000, 1.5600, 0.0000], ..., [ 48.7935, 49.6000, -0.7391, ..., 0.8000, 1.7300, 1.5700], [ 49.1967, 49.6000, -0.7391, ..., 0.8000, 1.7300, 1.5700], [ 49.6000, 49.6000, -0.7391, ..., 0.8000, 1.7300, 1.5700]]], device='cuda:0'), 'metadata': [{'token': 'b05ff89145b374f19c20b7ea6755f007'}, {'token': '792e28ae3402fb79ce87fc414c5a8b53'}, {'token': '2b41120736de26519c22cea7c9874133'}]} |
torch_quantizerがtuple/list構造のみ
ただtorch_quantizerにメタ情報が多く入ったdictの形で入れるとエラーが出ます。
torch_quantizerはtuple/list構造だけ引数に使ってくれと言われます。
そのため、モデル(Voxelnet)のコードも書き換える必要があります。
|
1 2 3 4 5 6 7 8 9 |
File "../second.pytorch/second/pytorch/quant_train.py", line 551, in quant device=device, File "/opt/vitis_ai/conda/envs/vitis-ai-pt1_7/lib/python3.7/site-packages/pytorch_nndct/apis.py", line 98, in __init__ quant_config_file = quant_config_file) File "/opt/vitis_ai/conda/envs/vitis-ai-pt1_7/lib/python3.7/site-packages/pytorch_nndct/qproc/base.py", line 101, in __init__ self._check_args(module, input_args) File "/opt/vitis_ai/conda/envs/vitis-ai-pt1_7/lib/python3.7/site-packages/pytorch_nndct/qproc/base.py", line 47, in _check_args raise TypeError(f"type of input_args should be tuple/list/torch.Tensor.") TypeError: type of input_args should be tuple/list/torch.Tensor. |
W_QUANT=1で量子化の処理を入れる
また量子化の処理も入れる必要があります。
Vitis AIのサンプルでいうW_QUANT=1の処理を入れている箇所です。
Voxelnet.pyの頭、またdef network箇所にも修正しました。
|
1 2 3 |
import os if os.environ["W_QUANT"]=='1': from pytorch_nndct.nn import QuantStub, DeQuantStub |
|
1 2 3 4 5 |
if os.environ["W_QUANT"]=='1': self.quant_pfn = QuantStub() self.dequant_pfn = DeQuantStub() self.quant_rpn = QuantStub() self.dequant_rpn = DeQuantStub() |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
def network_forward(self, voxels, num_points, coors, batch_size): print("network_forward") """this function is used for subclass. you can add custom network architecture by subclass VoxelNet class and override this function. Returns: preds_dict: { box_preds: ... cls_preds: ... dir_cls_preds: ... } """ if os.environ["W_QUANT"]=='1': voxels = self.quant_pfn(voxels) self.start_timer("voxel_feature_extractor") voxel_features = self.voxel_feature_extractor(voxels, num_points, coors) self.end_timer("voxel_feature_extractor") if os.environ["W_QUANT"]=='1': voxel_features = self.dequant_pfn(voxel_features) self.start_timer("middle forward") spatial_features = self.middle_feature_extractor( voxel_features, coors, batch_size) self.end_timer("middle forward") if os.environ["W_QUANT"]=='1': spatial_features = self.quant_rpn(spatial_features) self.start_timer("rpn forward") preds_dict = self.rpn(spatial_features) self.end_timer("rpn forward") if os.environ["W_QUANT"]=='1': preds_dict = self.dequant_rpn(preds_dict) return preds_dict |
またVoxel化(Voxelnet.py)箇所だけでなく、他に量子化する箇所は追加します。
おそらくpointpillars箇所(pointpillars.py)、他encoder箇所なども必要だと思います。
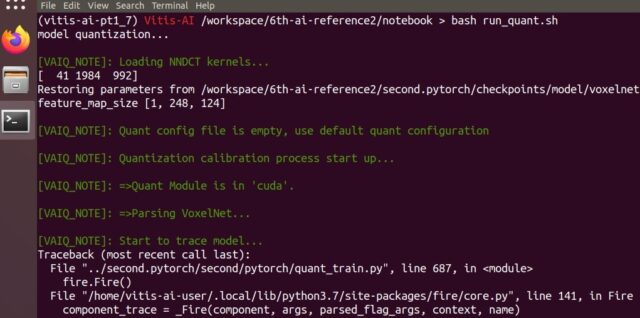
色々エラー修正したが、量子化の最後まで行けなかった
他にも色々エラー処理したのですが、結局最後まで行けませんでした。
エラー消すのに時間が溶ける溶けると言った感じでした。
(色々弄りすぎて、ブログには書ききれませんでした…。)
結果の一部切り取りが下記です、量子化の最後のxmodel出力までが遠かったです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
(vitis-ai-pt1_7) Vitis-AI /workspace/6th-ai-reference2/notebook > bash run_quant.sh model quantization... [VAIQ_NOTE]: Loading NNDCT kernels... [ 41 1984 992] Restoring parameters from /workspace/6th-ai-reference2/second.pytorch/checkpoints/model/voxelnet-24000.tckpt feature_map_size [1, 248, 124] [VAIQ_NOTE]: Quant config file is empty, use default quant configuration [VAIQ_NOTE]: Quantization calibration process start up... [VAIQ_NOTE]: =>Quant Module is in 'cuda'. [VAIQ_NOTE]: =>Parsing VoxelNet... [VAIQ_NOTE]: Start to trace model... [VAIQ_NOTE]: Finish tracing. [VAIQ_NOTE]: Processing ops... ████▌ | 19/211 [00:00<00:00, 1726.99it/s, OpInfo: name = VoxelNet/SpMiddleFHD[middle_feature_extractor]/SparseSequential[middle_conv]/Defau Traceback (most recent call last): File "../second.pytorch/second/pytorch/quant_train.py", line 891, in <module> fire.Fire() ~~~~~~~~~~~~~~~~~~~~~ File "/opt/vitis_ai/conda/envs/vitis-ai-pt1_7/lib/python3.7/site-packages/pytorch_nndct/parse/parser.py", line 213, in _convert_node nndct_node.op = self._create_op(raw_node.kind, nndct_node, node_input_args) File "/opt/vitis_ai/conda/envs/vitis-ai-pt1_7/lib/python3.7/site-packages/pytorch_nndct/parse/parser.py", line 248, in _create_op op = op_creator.custom_op(nndct_node, op_type, *node_input_args) File "/opt/vitis_ai/conda/envs/vitis-ai-pt1_7/lib/python3.7/site-packages/pytorch_nndct/parse/op_dispatcher.py", line 1284, in custom_op attrs = GLOBAL_MAP.get_ele(NNDCT_KEYS.CUSTOM_OP_ATTRS_MAP).get(op_type, None) AttributeError: 'NoneType' object has no attribute 'get' |
Vitis AI上で実行したコマンド
今回Vitis AIのdocker上で実行したコマンドは下記です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
(vitis-ai-pt1_7) Vitis-AI /workspace/6th-ai-reference2/notebook > history 1 conda activate vitis-ai-pytorch 2 wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin 3 sudo mv cuda-ubuntu1804.pin /etc/apt/preferences.d/cuda-repository-pin-600 # wget https://developer.download.nvidia.com/compute/cuda/10.2/Prod/local_installers/cuda-repo-ubuntu1804-10-2-local-10.2.89-440.33.01_1.0-1_amd64.deb 4 sudo dpkg -i cuda-repo-ubuntu1804-10-2-local-10.2.89-440.33.01_1.0-1_amd64.deb 5 sudo apt-key add /var/cuda-repo-10-2-local-10.2.89-440.33.01/7fa2af80.pub 6 sudo apt-get update 7 sudo apt-get install -y cuda-toolkit-10-2 8 sh docker/dockerfiles/replace_pytorch.sh vitis-ai-pt1_7 9 conda activate vitis-ai-pt1_7 10 cd 6th-ai-reference2/ 11 cd spconv/ 12 pip install ./dist/spconv*.whl 13 cd .. 14 pip install --user -r docker/requirements.txt 15 cd notebook/ 16 bash run_quant.sh |
実行で使っているスクリプト(run_quant.sh)は特に大したことしていないです。
下記のようにtrain.pyから改造したプログラム(quant_train.py)を動かしているだけです。
|
1 2 3 4 5 6 7 8 9 10 |
export CUDA_VISIBLE_DEVICES=0 export PYTHONPATH=${PWD}:${PYTHONPATH} export W_QUANT=1 CONFIG_PATH=../second.pytorch/second/configs/nuscenes/pointpainting.config MODEL_DIR=../second.pytorch/checkpoints/model echo "model quantization..." python ../second.pytorch/second/pytorch/quant_train.py quant --config_path ${CONFIG_PATH} --model_dir ${MODEL_DIR} --measure_time=True --batch_size=4 |
まとめ
リファレンス環境の量子化は、時間的にも難しいと判断して途中でギブアップしました。
(多分これ以上続けてもハマるイメージしかありませんでした)
次の記事からは、また違ったアプローチでの3D物体検出の量子化を紹介します。
今回の記事含めて、第6回AIエッジコンテストの一環でした。
下記にてコンテストでテスト・実施したことのまとめを紹介しています。


コメント