
第5回AIエッジコンテストに参加していました。
(筆者の力量では)コンテストの課題が難しく、最後の実装まで到達できませんでした。
ただ貴重な勉強の機会になりましたし、自身への忘備録としても内容を紹介します。
AIエッジコンテストが勉強になった(難しかった)件
FPGAでAIの実装にチャレンジしたく、現在コンテストに参加しています。
参加しているコンテストは経済産業省が主催している「第5回AIエッジコンテスト」です。
コンテストに参加始めた時点で、一度記事を投稿させていただきました。
必要そうな開発環境を準備したことをまとめていました。

開始から2か月ほど経ちましたが、最後の実装まで全く到達できませんでした。
AIやデータ分析のコンペに参加するのは初めてでしたが、かなり難しい課題と感じました。
(筆者自身の技術、また取り組み時間が足りないのが本質だと思いますが…。)
ただ画像認識、FPGA、RISC-Vとした最新の技術を触れる良い経験になりました。
(日常の仕事では全く使わない技術ばかりで貴重な経験になります。)

自身への忘備録、また誰か・何かの参考になればと思いブログ記事として残しておきます。
※この記事はAIや機械学習のほぼ初心者が記載したものです。
色々と間違っているかもしれないので、面白半分に見てもらえればと思います。
書いている人のAI・画像認識のモデル作成の経験
書いている人は仕事でAIやモデルの学習の実務・経験は無く、ほぼ初心者レベルです。
AIエッジコンテストへの参加も初めてです。
つまり下記感じの、全く理解できていない・分かっていない奴です。
- TensorFlowって何か聞いたことはある!
- YOLOって何!夜露死苦!ってことでいいですか?
- caffe?カフェならコーヒーでも飲みたいです
完成されたモデルなどを使用して、画像認識で遊ぶ程度の経験があるぐらいです。
正直な所、このレベルだと今回のコンテストはかなりハードルがありました。
コンテストで勉強になった(難しかった)こと
私見ですが、今回の課題で勉強になった(逆の意味で難しかった)と感じたことが下記例です。
- FPGAでAI開発をするための環境構築
- 画像認識のモデルを一から作る経験
- FPGAで画像認識を行うまでの開発フロー
- FPGAにRISC-Vを実装した上で、画像認識にどう組み込むか
本題のFPGAのRISC-Vの実装までが本当に遠かったです。
(というか出来なかった…。サンプルちょっと触る程度で終わりました)
モデルを作成、FPGAに使えるように変換しているところで時間を使っていました。
過去の入賞者レポートは参考になる
今回の第5回はFPGAにRISC-Vを実装して画像認識を行うという課題です。
また課題の中身(データ)としては過去(第3回)のコンテストでも同じということです。
そのため、まずは第3回の入賞者レポートを参考にして一度通したいと試みました。
特に一番参考にさせていただいたのが、下記第3回の3位チームのものです。
プログラム・スクリプトなぞるだけでも勉強になりました。

もしこれから始める人は下記の学習箇所の流れは参考になると思います。
ffmpeg使った動画から静止画への変換から、kerasでの学習まで丁寧に書かれていました。
https://github.com/Machine-Learning-Tokyo/EdgeAIContest3/blob/master/src/ObjectDetectionTraining.md
作りたかった構成
最初から画像認識の全ての機能をFPGAのRISC-V上で実装するのは無理だと感じていました。
そのため、下記構成で作りたいと考えていました。
★作りたかった(作れなかった)構成
~~~~~~~~~~~~~~~~~~~~
●物体検出(Object Detection)…FPGAのDPU
●物体検出した後の補正処理…FPGAのRISC-V
~~~~~~~~~~~~~~~~~~~~
FPGAのDPUを使った画像認識は第4回のAIエッジコンテストでも実施されています。
先ほど紹介した、第3回の3位のチームの手法を真似したいと考えていました。
赤字の対応をしてFPGAで一通り課題を通してみたいと…。(結局出来ませんでしたが…)
★第3回の3位の手法
~~~~~~~~~~~~~~~~~~~~
●物体検出(Object Detection)…keras-retinanet
→DPUで使えるように変換できる?
●物体検出した後の補正処理…Hungarian Algorithm
→RISC-Vで動かせるようにC++で似たように書き直す?
~~~~~~~~~~~~~~~~~~~~
ただそれすらも非常に難しく、途中で終わってしまった形になります。
(スコア何それ?といった感じで、コンペしている余裕は無かったです)
失敗に終わりましたが、色々試した・勉強になったことを記載していきます
モデル学習をGoogleColabで試したが…
第3回3位のGitHubをCloneしてモデル学習を真似していくと、すぐに壁に当たりました。
「GPU無しの個人のノートPCでは、学習時間がかかりすぎて無理!」となりました。
学習開始すると、CPU使用率が100%になり数日~数週間続きます。
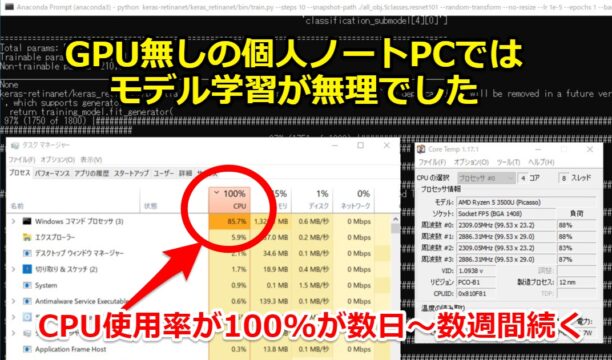
機械学習のコンペなどではGPU必要!と聞いていましたが、身をもって感じました。
そのため、ブラウザ上で無料で使える計算機資源のGoogleColabを使えないか試してみました。
ただColab上で実施すると途中で止まる結果になりました。
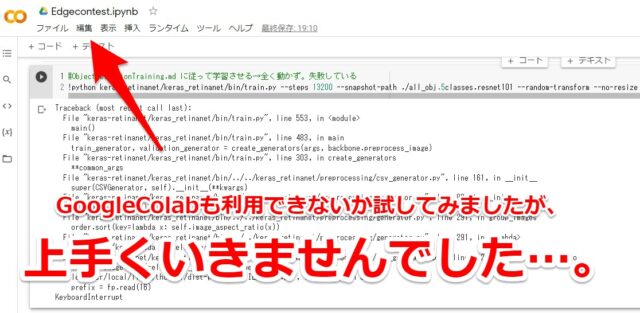
第3回3位の学習をColabで実行したコードは下記です。
ダウンロード・解凍など2回目以降不要なコードは#を付けています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
# 残り時間の表示 !cat /proc/uptime | awk '{printf("残り時間 : %.2f", 12-$1/60/60)}' # 作業用フォルダの作成 from google.colab import drive drive.mount('/content/drive') #!mkdir -p '/content/drive/My Drive/work/' %cd '/content/drive/My Drive/work/' #第3回3位のGitHubをクローン #!git clone https://github.com/Machine-Learning-Tokyo/EdgeAIContest3.git #ソースコード場所に移動 import os path = '/content/drive/MyDrive/work/EdgeAIContest3/src' #作業ディレクトリをpathに移動する os.chdir(path) #作業ディレクトリ直下のファイルを確認 !ls #学習用のビデオのフォルダ作成 + GoogleDrive上でデータをコピーする #!mkdir train_videos #学習用のアノテーションのフォルダ作成 + GoogleDrive上でデータをコピーする #!mkdir train_annotations #ffmpegを使えることを確認 !ffmpeg -version #ObjectDetectionTraining.md に従って動画→静止画の変換 数時間かかる #!bash convert_video_to_image.sh #ObjectDetectionTraining.md に従って学習用のアノテーションの変換 #!python generate_retinanet_train_annotation.py #ObjectDetectionTraining.md に従って評価用のアノテーションの変換 #!python generate_retinanet_val_annotation.py #パラメータ設定済のkeras-retinanetが入っていた。解凍。必要な場合はcloneする #!unzip keras-retinanet.zip #ObjectDetectionTraining.md に従ってkeras-retinanetを使えるようにする import os path = '/content/drive/MyDrive/work/EdgeAIContest3/src/keras-retinanet' #作業ディレクトリをpathに移動する os.chdir(path) !pwd !pip install . --user !python setup.py build_ext --inplace #ソースコード場所に移動 import os path = '/content/drive/MyDrive/work/EdgeAIContest3/src' #作業ディレクトリをpathに移動する os.chdir(path) #ObjectDetectionTraining.md に従って学習させる→全く動かず。失敗している !python keras-retinanet/keras_retinanet/bin/train.py --steps 13200 --snapshot-path ./all_obj.5classes.resnet101 --random-transform --no-resize --lr 1e-5 --epochs 100 --backbone resnet101 csv retinanet_annotations.csv.train.all_frames.all_objects.5_classes class_id_map.txt.5classes --val-annotations retinanet_annotations.csv.val.all_frames.all_objects.5_classes |
エラーの内容としては下記です。
個人のPC上では学習できるのに、Colabではkeras-retinanetの学習で止まっていました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
Traceback (most recent call last): File "keras-retinanet/keras_retinanet/bin/train.py", line 553, in <module> main() File "keras-retinanet/keras_retinanet/bin/train.py", line 483, in main train_generator, validation_generator = create_generators(args, backbone.preprocess_image) File "keras-retinanet/keras_retinanet/bin/train.py", line 303, in create_generators **common_args File "keras-retinanet/keras_retinanet/bin/../../keras_retinanet/preprocessing/csv_generator.py", line 161, in __init__ super(CSVGenerator, self).__init__(**kwargs) File "keras-retinanet/keras_retinanet/bin/../../keras_retinanet/preprocessing/generator.py", line 89, in __init__ self.group_images() File "keras-retinanet/keras_retinanet/bin/../../keras_retinanet/preprocessing/generator.py", line 291, in group_images order.sort(key=lambda x: self.image_aspect_ratio(x)) File "keras-retinanet/keras_retinanet/bin/../../keras_retinanet/preprocessing/generator.py", line 291, in <lambda> order.sort(key=lambda x: self.image_aspect_ratio(x)) File "keras-retinanet/keras_retinanet/bin/../../keras_retinanet/preprocessing/csv_generator.py", line 202, in image_aspect_ratio image = Image.open(self.image_path(image_index)) File "/usr/local/lib/python3.7/dist-packages/PIL/Image.py", line 2852, in open prefix = fp.read(16) KeyboardInterrupt |
データが大きすぎるのが問題?
今回の学習モデルは2分(120秒)の動画が25本あり、1秒5フレームでした。
そのため動画→静止画にすると120*5*25=15000枚ほどの静止画となります。
解像度を1932*1216(1枚当たり約3MB)で使うと合計で学習データが約50GBほどになりました。
※GoogleDriveも無料の15GBでは足りず、課金しました。
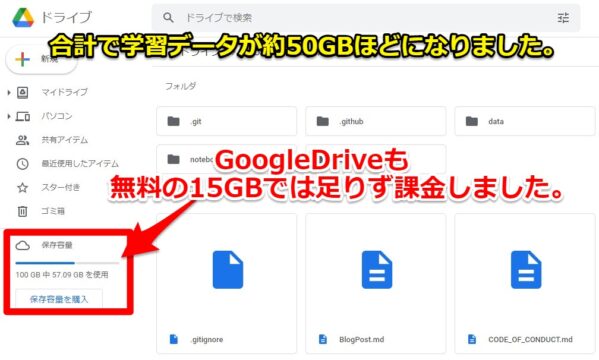
エラーをネットで調べていくと他にも同様な事象がありましたが、解決は出来ませんでした。
おそらく学習の最中に大容量のcsvを展開する時に、エラーになっていたのかと思われます。
結局Colab上でのkeras-retinanetの学習はあきらめました
個人のPC上では一応学習できたのでエポック数減らして、不完全ですがモデルを作成しました。
時間はかかりましたが、Anaconda上では問題なくkeras-retinanetの学習が出来ました。
keras(.h5)→TensorFlow(.pb)の変換で躓いた
第3回3位のモデルはkeras-retinanetで作られています。(重みファイルは.h5の形式です)
FPGAのDPUで使うには、TensorFlowかcaffeかPytorchに変換する必要がありました。
※今回のFPGAはXilinxのため、Vitis-AIの環境で対応した形にする必要があります。
keras(.h5)→TensorFlow(.pb)の変換方法に関しては、Vitis-AIの公式からも紹介されています。
チュートリアルはdocker環境でスクリプトで選んでいくものですが、中身は参考になります。
GitHubに紹介されていました。

Keras2TF.py
チュートリアルのフォルダの中に変換プログラム(Keras2TF.py)があります。
ただこのままでは個人的な用途では使えないので、改造する必要があります。
keras_to_tensorflow.py
keras(.h5)→TensorFlow(.pb)の変換方法に関しては、既に多くの先人達が展開しています。
下記Qiita記事が分かりやすく記載しています。今回は下記手法を使って変換しました。

余談ですが上記記事作者の「からあげ」さんには数年前にAIの勉強会でお世話になりました。
(AI関連の本を出したり、役に立つブログ記事を数多く書いているスゴイ人です)
その際のブログ記事は下記となります。
AIの勉強会に初心者がLT枠で参加してみた!AIchi勉強会

keras-retinanetの変換ができなかった
まずは第3回3位のkeras-retinanetの変換を試みたのですが、エラーが出てしまいました。
作成したh5のファイルが重みのみで、モデルのアーキテクチャーが入っていないためです。
(そもそもh5ファイルの中身がよく分かっていませんでした。恥ずかしい…)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
Using TensorFlow backend. E0205 12:47:44.844760 140468331542400 keras_to_tensorflow.py:95] Input file specified only holds the weights, and not the model definition. Save the model using model.save(filename.h5) which will contain the network architecture as well as its weights. If the model is saved using the model.save_weights(filename) function, either input_model_json or input_model_yaml flags should be set to to import the network architecture prior to loading the weights. Check the keras documentation for more details (https://keras.io/getting-started/faq/) Traceback (most recent call last): File "keras_to_tensorflow.py", line 184, in <module> app.run(main) File "/usr/local/lib/python3.7/dist-packages/absl/app.py", line 312, in run _run_main(main, args) File "/usr/local/lib/python3.7/dist-packages/absl/app.py", line 258, in _run_main sys.exit(main(argv)) File "keras_to_tensorflow.py", line 128, in main model = load_model(FLAGS.input_model, FLAGS.input_model_json, FLAGS.input_model_yaml) File "keras_to_tensorflow.py", line 106, in load_model raise wrong_file_err File "keras_to_tensorflow.py", line 63, in load_model model = keras.models.load_model(input_model_path) File "/tensorflow-1.15.2/python3.7/keras/engine/saving.py", line 492, in load_wrapper return load_function(*args, **kwargs) File "/tensorflow-1.15.2/python3.7/keras/engine/saving.py", line 584, in load_model model = _deserialize_model(h5dict, custom_objects, compile) File "/tensorflow-1.15.2/python3.7/keras/engine/saving.py", line 274, in _deserialize_model model = model_from_config(model_config, custom_objects=custom_objects) File "/tensorflow-1.15.2/python3.7/keras/engine/saving.py", line 627, in model_from_config return deserialize(config, custom_objects=custom_objects) File "/tensorflow-1.15.2/python3.7/keras/layers/__init__.py", line 168, in deserialize printable_module_name='layer') File "/tensorflow-1.15.2/python3.7/keras/utils/generic_utils.py", line 140, in deserialize_keras_object ': ' + class_name) ValueError: Unknown layer: Functional |
Poly-Yoloの変換は出来た
とりあえずモデルを変えて試してみることにしました。
第3回2位のPoly-Yoloの(.h5)モデルを変換したところ、無事変換出来ました。
(完成された.h5ファイル(chleba.h5など)も置いてくれていました)

TensorFlowのバージョンも変更する必要がありましたので、これもColab上で実施しました。
ダウンロード・解凍など2回目以降不要なコードは#を付けています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
#tensorflowのバージョンを1.xにする %tensorflow_version 1.x #tensorflow/kerasのバージョンを確認する import tensorflow as tf print(tf.__version__) import keras print(keras.__version__) # 作業用フォルダの作成 from google.colab import drive drive.mount('/content/drive') #!mkdir -p '/content/drive/My Drive/work/' %cd '/content/drive/My Drive/work/' # keras_to_tensorflowをCloneする #!git clone https://github.com/karaage0703/keras_to_tensorflow.git #ソースコード場所に移動 import os path = '/content/drive/MyDrive/work/keras_to_tensorflow' #作業ディレクトリをpathに移動する os.chdir(path) #作業ディレクトリ直下のファイルを確認 !ls #AttributeError: 'str' object has no attribute 'decode'のエラーが出るためh5pyを再インストール # まずはバージョン確認 !pip3 show h5py # アンインストール !sudo pip3 uninstall h5py # バージョン指定インストール !sudo pip3 install h5py==2.10.0 #第3回3位のkeras-retinanetの変換が上手くいかなかったので、第3回2位のPoly-Yoloのモデルを試す + GoogleDrive上でデータをコピーする #!python keras_to_tensorflow.py --input_model="resnet101_csv_01.h5" --output_model="model.pb" !python keras_to_tensorflow.py --input_model="chleba.h5" --output_model="model.pb" #pbファイルが作成されたか確認 !ls -l |
モデル変換したり、Vitis-AIを触っていたら時間が溶けた
その後はFPGAにモデルを使えるようにしていたら、あっという間に時間が溶けていきました。
- keras-retinanetの変換が出来ないか色々弄る
- 作成したpbファイルをVitis-AIに入れて、量子化・コンパイルなどの対応
- そもそもVitis-AIがdockerで動かすもので、初めてのdocker環境に四苦八苦
結局FPGAでモデル動かせることはできませんでした。
正直なところ、モデルを作ってFPGAに組み込むまでの経験・知識が全く足りなかったです。
本当にここらへん出来る人、凄い…と思いました。
RISC-Vはリファレンスを少し触る程度で終わった
モデル変換難しい時は、息抜きにRISC-Vのリファレンスデザインを触っていました。
petalinuxを使うのも初めてで、貴重な経験になりました。
※petalinux…XilinxのFPGA上のLinuxをカスタマイズするツール
参考になったのは下記記事です。
下記作者の方はリファレンス展開後、すぐに丁寧な記事を作られており凄い人だと思いました。


筆者の力量では(仮に)モデル作成ができても、RISC-Vでの実装でも力尽きていたと思います。
もし筆者の作りたい構成だと、DPUとRISC-Vが混在する環境が必要です。
ただそのハードウェア環境を作るにも相当な壁があると強く感じました。
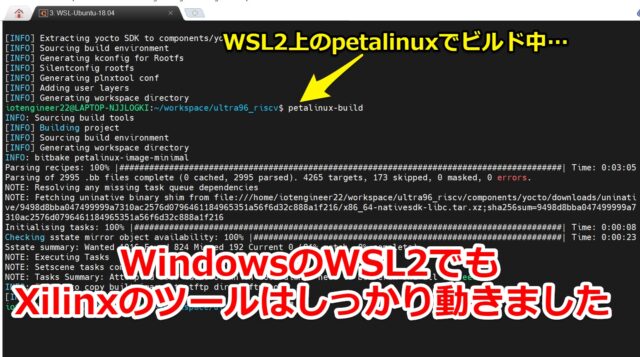
WSL2上でもXilinxのツールは動かせた
今回使えるLinuxの環境が手元になくWindowsのWSL2で対応しました。
下記記事でも紹介しましたが、本来XilinxのツールはLinux上の動作を推奨されています。
一通りVivado,Vitis,petalinuxなどXilinxのツールがWSL2上で動かせました。
特に問題なく、petalinuxでRISC-Vのコンパイルまで出来ました。
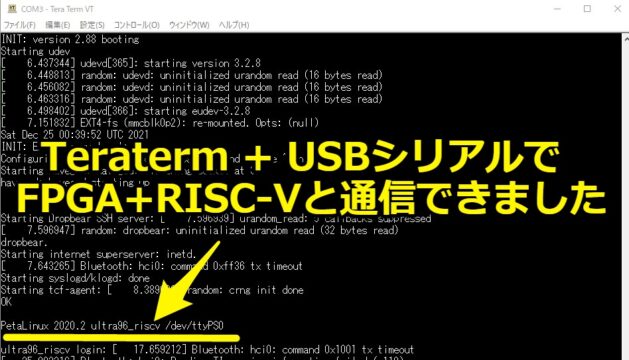
Wifiの設定が面倒だったのでuartを使った
今回のFPGA評価ボード(Ultra96-V2)にはWifiがあります。
ただWifi設定が少し手間で、また他の手段(USB-LAN,専用ボード)も手元にありませんでした。
そのためUSBシリアルケーブルをuartに接続して通信させていました。

コンソール上のログ見るぐらいならば115200bpsのシリアルで十分に出来ました。
Teratermで問題なく通信出来ています。
(サンプル触ってFPGA上でRISC-Vを動くのを見て、ちょっと感動していた…)
詳しいピン接続方法に関しては、下記記事で紹介しています。
Ultra96-V2のuart1にUSBシリアル通信で接続してみた

コンテストで失敗したと思ったこと
という感じで、本当に今回の第5回のAIエッジコンテストは残念な結果となりました。
特に環境面・進め方に失敗したと思ったことを記載していきます。
PCのスペック貧弱すぎた
書いている人のPCは標準的なWindowsのノートPC(Lenovo)です。
やはり「FPGA+AIの環境構築」、「モデル学習」するにはノートPCでは厳しかったです。
- CPU…Ryzen 5
- GPU…無し
- メモリ…4GB+16GB(増設)
- SSD…Cドライブ_256GB + Dドライブ_512GB(増設)

なるべく重い開発環境(Xilinxのツールなど)はDドライブに入れていました。
ただそれでも、特にメインのCドライブ容量(256GB)が少ないのは厳しかったです。
(下記環境もDに移行できそうでしたが、一度始めたら基本変えたくなかったです。)
- dockerの環境がガンガン入る
- WSL2も使って拡張していくと重くなっていく。
- petalinuxなどCに入れないとエラーが出るものがあった
GPUはあった方がいい
Vitis-AIやモデル学習に関しては「GPU無し」でも(一応)実施できるようになっています。
ただ、GPU無いと非常に時間かかる + CPU100%となりPCがまともに動かせなくなります。
途中でも記載しましたが、学習の仕方によっては数日~数週間かかる場合があります
GoogleColabで結構時間使った
「個人PCがスペック不足ならば、GoogleColabだ!」と最初は思っていました。
ただColabは無料で使える貴重な計算資源ですが、上手く使えるかはまた別の話になります。
(多分、筆者がColabを使い慣れていないのが一番大きいですが…)
特にPCのAnaconda上では学習するのに、Colabでエラー出ると時間を使いました。
WSL2でLinuxの代わりになるが…
WSL2がLinuxの代替になりましたが、やはり個人的にはLinuxの実環境が欲しい時がありました。
(おそらく筆者が慣れていないだけで、WSL2を使える人ならば問題ないと思います)
- インストールなどで失敗したとき、環境なのか手順が悪いのか???となる
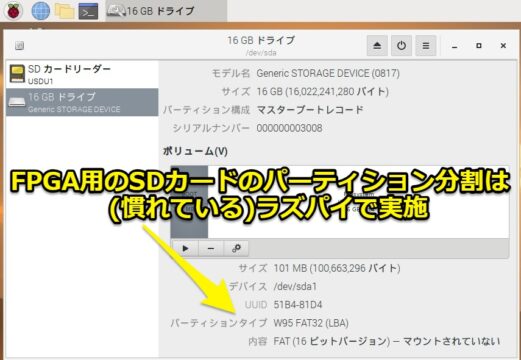
- (FPGA用の)SDカードのフォーマット作業するとき、実環境の方が楽だった
結局、FPGA用のSDカードのパーティション分割は慣れているラズパイで実施しました。
ネットに制限があると厳しい
凄く個人的な事情になるのですが、筆者が家にネット回線を引いていない人です
基本的に使用制限のあるWiMAXで十分の人です。(3日で10GB以上で通信制限が入る)
ただネット制限がある環境はこのAI系のコンテストはかなり厳しかったです。
dockerやFPGAの開発環境は数GB~数十GBのダウンロードが普通にありました。
過去の入賞者のレポートは参考までに
今回、筆者は画像認識のモデルを一から学習させることが初めてです。
なるべく、過去の同じ問題である第3回の入賞者の手法を真似る形で進めていました。
ただ過去の手法ではFPGAのモデルには直接使えなく、変換に結構手間取りました。
もう少し事前に知識を付けて、FPGAのモデルに直接使える学習ができれば…とは思いました。
AIエッジコンテストで良かったこと
結果はどうあれ、今回AIエッジコンテストに参加して良かったと思います。
日々の業務には無い、画像認識、FPGA、RISC-Vとした最新の技術を触れることができました。
正直、書いている人にとっては今回全てが新鮮な技術でした。
- FPGA(Ultra96-V2)…仕事ではまず使う機会が無いシリーズ。
- RISC-V…今回弄れなかったが、GitHubにあるリファレンスのベース含めて勉強したい。
- ffmpeg…動画から静止画にこんなに簡単に変換できるのかと感動した。
- TensorFlow,keras…相変わらず全然分からん。もっと使えるようになりたい。
- Python…久しぶりにコードとにらめっこした。
- GoogleColab…本当に便利な計算資源です。もっと使いこなしたい。
- Vitis-AI,petalinux…本当に分からん。もっと使えるようになりたい。
コンテスト・コンペに参加する人によって色んな技術バックグラウンドがあると思います。
ただ、新しいこと・新しい技術に取り組むという姿勢は日々持ち続けたいです。
また次の機会があれば、課題提出できるまでは実力を付けたいと思いました。
第5回は課題提出できるだけでも凄いと思う
過去のAIエッジコンテストのレポートも見ましたが、今回は特に課題量が多いかと思いました。
今回の第5回に関しては課題提出できるだけでも凄いと思います。(本当に、マジで…)
画像認識のモデル作成・FPGAの初心者の方にはかなり厳しい戦いになったと思います。
まとめ
今回はAIエッジコンテストが勉強になった(難しかった)件に関して紹介させていただきました。
記事をまとめますと下記になります。
参加したコンテストは経済産業省が主催している「第5回AIエッジコンテスト」です。
FPGAを使ったAIの開発できる貴重なコンテストでした。
大会の運営者様にはデータや資料を始め、評価用ボードまで提供していただきました。
この場を借りて、お礼申し上げます。


コメント