ONNXのYOLOXをDPUとPythonで動かしてみました。
KR260上でONNX専用の環境構築して、onnxruntimeを実行しています。
Vitis AI ONNXRuntime Engine (VOE) を使用した旨を紹介します。
ONNXをDPUとVitis AI環境で動かしてみた。YOLOX編
ONNX環境のYOLOXをDPUとPythonで動かしてみました。
KR260上でONNX専用の環境構築して、onnxruntimeを実行しています。
Vitis AI ONNXRuntime Engine (VOE) を使用した旨を紹介します。
実際のテスト動画は下記となっています。
Vitis AIの3.5のONNX
Vitis AIの3.5のONNXではC++とPythonがサポートされています。

またC++のYOLOXに関しては、下記に公式からサンプルが用意されています。
下記記事でPyTorchのYOLOXを、DPU-PYNQ環境で作成・実行していました。
PYNQでYOLOX-nano + PyTorchの物体検出してみた
今回はPythonのコードを書き直して、ONNXのYOLOXを動かしています。
bspからpetalinuxで環境構築
今回はPetalinuxを使って、KR260上のOS環境を作成しています。
bspファイルを下記からダウンロードして、Petalinuxでビルドします。
正しい手順は下記URLを参照ください。
https://xilinx-wiki.atlassian.net/wiki/spaces/A/pages/1641152513/Kria+SOMs+Starter+Kits#PetaLinux-Build-instructions
|
1 2 3 4 5 6 |
source /opt/petalinux/2023.1/settings.sh petalinux-create -t project -s xilinx-kr260-starterkit-v2023.1-05080224.bsp cd xilinx-kr260-starterkit-2023.1/ petalinux-build petalinux-package --boot --u-boot --force petalinux-package --wic --images-dir images/linux/ --bootfiles "ramdisk.cpio.gz.u-boot,boot.scr,Image,system.dtb,system-zynqmp-sck-kr-g-revB.dtb" --disk-name "sda" |
Petalinuxで作成したsdカードのイメージ(.wic)を書き込みます。下記のフォルダにあります。
~/xilinx-kr260-starterkit-2023.1/images/linux/
筆者はbalenaEtcherを使用して、SDカードに書き込んでいます。
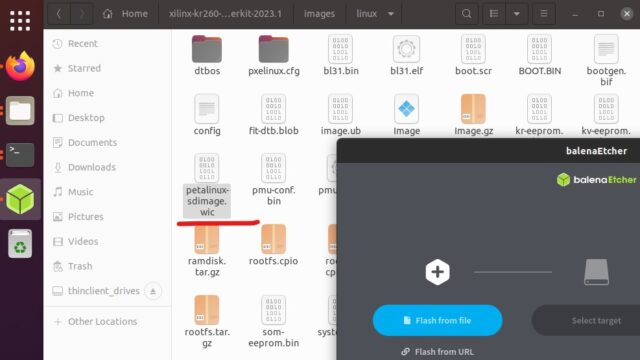
onnxruntimeをインストールする
KR260で最初のログイン名は「petalinux」です。
下記公式ドキュメントに従って、KR260にVitis AIやONNXのruntimeなどをインストールします
https://docs.amd.com/r/en-US/ug1414-vitis-ai/Programming-with-VOE
|
1 2 3 4 5 6 7 |
wget https://www.xilinx.com/bin/public/openDownload?filename=vitis_ai_2023.1-r3.5.0.tar.gz sudo tar -xzvf openDownload\?filename\=vitis_ai_2023.1-r3.5.0.tar.gz -C / ls wget https://www.xilinx.com/bin/public/openDownload?filename=voe-0.1.0-py3-none-any.whl -O voe-0.1.0-py3-none-any.whl pip3 install voe*.whl wget https://www.xilinx.com/bin/public/openDownload?filename=onnxruntime_vitisai-1.16.0-py3-none-any.whl -O onnxruntime_vitisai-1.16.0-py3-none-any.whl pip3 install onnxruntime_vitisai*.whl |
*今回petalinuxを使っているのは、Ubuntu環境はonnxruntimeがインストールできないためです。
一度実行してみましたが、インストールできませんでした
xrt packagegroup-petalinux-opencvをインストールする
公式ドキュメント通りインストール実行しても、Pythonでimportするとエラーがでました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
xilinx-kr260-starterkit-20231:~$ python3 Python 3.10.6 (main, Aug 1 2022, 20:38:21) [GCC 12.2.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import onnxruntime Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/home/petalinux/.local/lib/python3.10/site-packages/onnxruntime/__init__.py", line 55, in <module> raise import_capi_exception File "/home/petalinux/.local/lib/python3.10/site-packages/onnxruntime/__init__.py", line 23, in <module> from onnxruntime.capi._pybind_state import ExecutionMode # noqa: F401 File "/home/petalinux/.local/lib/python3.10/site-packages/onnxruntime/capi/_pybind_state.py", line 33, in <module> from .onnxruntime_pybind11_state import * # noqa ImportError: libglog.so.0: cannot open shared object file: No such file or directory |
おそらくxrt周辺が入っていないと思われるエラーでしたので、下記で対応しました。
|
1 |
sudo dnf install xrt packagegroup-petalinux-opencv |
上記実行後は問題なく、pythonでonnxruntimeをimportできるようになりました。
|
1 2 3 4 5 |
xilinx-kr260-starterkit-20231:~$ python3 Python 3.10.6 (main, Aug 1 2022, 20:38:21) [GCC 12.2.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import onnxruntime >>> exit() |
PetalinuxでDPU環境を作成する
UbuntuではPYNQ-DPUのライブラリ経由で、FPGAのDPU環境をオーバレイが出来ました。
Petalinuxではxmutilを使って、DPU環境を用意していきます。
xmutilに必要なファイル含めて用意していきます。下記GitHubにも置いています
https://github.com/iotengineer22/AMD-Pervasive-AI-Developer-Contest/tree/main/src/onnx-test
この章での作業はVivado, VitisをインストールしたLinux環境で実行しています。
pl.dtbo
下記記事で作成したVivadoでのFPGAのデザインファイル(.xsa)を使います。

下記コマンドにより、CUIのVitis経由でデバイスツリーの「pl.dtbo」のファイルを作成します。
|
1 2 3 4 5 6 |
xsct createdts -hw amd_contest_design.xsa -zocl -platform-name mydevice -git-branch xlnx_rel_v2023.1 -overlay -compile -out mydevice exit dtc -@ -O dtb -o mydevice/mydevice/mydevice/psu_cortexa53_0/device_tree_domain/bsp/pl.dtbo mydevice/mydevice/mydevice/psu_cortexa53_0/device_tree_domain/bsp/pl.dtsi mkdir dtg_output cp mydevice/mydevice/mydevice/psu_cortexa53_0/device_tree_domain/bsp/pl.dtbo dtg_output |
shell.json
XRT_FLAT情報を記載した「shell.json」ファイルも作成しておきます。
DPUをロードするときに必要なファイルとなります。
|
1 2 3 4 |
echo '{' > shell.json echo ' "shell_type" : "XRT_FLAT",' >> shell.json echo ' "num_slots": "1"' >> shell.json echo '}' >> shell.json |
dpu.xclbin
またVitisでDPUを合成時に作成したDPUのビットストリームファイル(dpu.xclbin)も使います。
今回のDPUはB4096の300MHzで動作させています。
Vitisのプロジェクトの「***_hw_link」のフォルダにあります。
~/***_hw_link/Hardware/
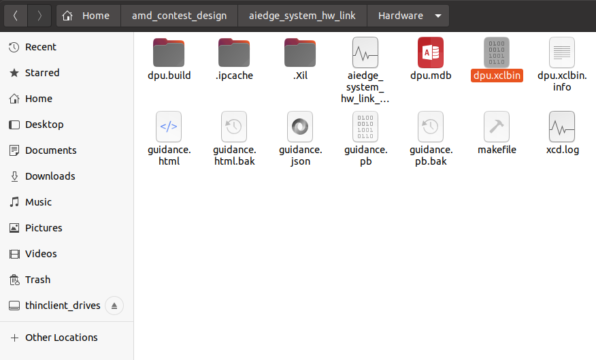
vart.conf
Vitis AI ランタイム (VART) の設定ファイルである、vart.confも作成しときます。
|
1 |
echo 'firmware: /home/petalinux/onnx-test/dpu.xclbin' > vart.conf |
今回はdpu.xclbinを置くファイル場所を記載しているだけです。
「firmware: /home/petalinux/onnx-test/dpu.xclbin」
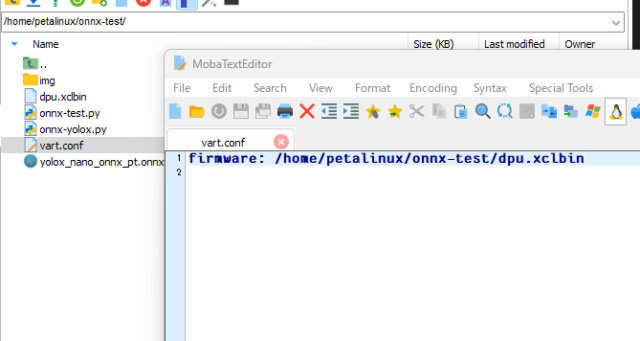
onnxruntimeなどをインストール時に下記フォルダに自動的に作成されていました。
/etc/vart.conf
デフォルトは「firmware: /run/media/mmcblk0p1/dpu.xclbin」となっていました。
今回は仮にテストする仮のフォルダを指定し直しています。
ONNXを動かすときにvart.confを参照して実行します。
正しい記載にしておかないとプログラム実行時に下記のようなエラーが出ました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
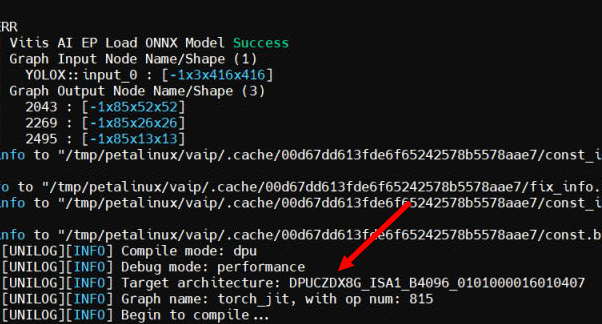
xilinx-kr260-starterkit-20231:~/onnx-test$ python3 onnx-test.py WARNING: Logging before InitGoogleLogging() is written to STDERR I20240706 09:27:31.883738 1134 vitisai_compile_model.cpp:242] Vitis AI EP Load ONNX Model Success I20240706 09:27:31.883842 1134 vitisai_compile_model.cpp:243] Graph Input Node Name/Shape (1) I20240706 09:27:31.884214 1134 vitisai_compile_model.cpp:247] YOLOX::input_0 : [-1x3x416x416] I20240706 09:27:31.884447 1134 vitisai_compile_model.cpp:253] Graph Output Node Name/Shape (3) I20240706 09:27:31.884640 1134 vitisai_compile_model.cpp:257] 2043 : [-1x85x52x52] I20240706 09:27:31.884748 1134 vitisai_compile_model.cpp:257] 2269 : [-1x85x26x26] I20240706 09:27:31.884855 1134 vitisai_compile_model.cpp:257] 2495 : [-1x85x13x13] I20240706 09:27:32.802131 1134 pass_imp.cpp:379] save const info to "/tmp/petalinux/vaip/.cache/00d67dd613fde6f65242578b5578aae7/const_info_before_const_folding.txt" I20240706 09:27:33.475831 1134 pass_imp.cpp:288] save fix info to "/tmp/petalinux/vaip/.cache/00d67dd613fde6f65242578b5578aae7/fix_info.txt" I20240706 09:27:33.476284 1134 pass_imp.cpp:379] save const info to "/tmp/petalinux/vaip/.cache/00d67dd613fde6f65242578b5578aae7/const_info_after_const_folding.txt" I20240706 09:27:33.478890 1134 pass_imp.cpp:406] save const info to "/tmp/petalinux/vaip/.cache/00d67dd613fde6f65242578b5578aae7/const.bin" I20240706 09:27:39.314126 1134 xrt_bin_stream.cpp:49] Please check your /etc/vart.conf Its format should be : firmware: xx Example: firmware: /run/media/mmcblk0p1/dpu.xclbin F20240706 09:27:39.314198 1134 xrt_bin_stream.cpp:53] [UNILOG][FATAL][VART_OPEN_DEVICE_FAIL][Cannot open device] open(/run/media/mmcblk0p1/dpu.xclbin) failed. I20240706 09:27:39.439172 1134 vitisai_compile_model.cpp:270] Catch fatal exception, skip this subgraph. Set XLNX_ENABLE_SKIP_FATAL=0 to stop skip. |
ONNXのYOLOXのモデル(.onnx)
今回はVitis AIから提供されているモデルを使用します。
学習済・量子化済のモデルは、Xilinx(AMD)からサンプルが提供されています。
PyTorchのモデルをONNXに変換したものです。
https://github.com/Xilinx/Vitis-AI/tree/master/model_zoo/model-list/pt_yolox-nano_3.5
YOLOXのサンプルのモデルをダウンロードして解凍します。
|
1 2 |
wget https://www.xilinx.com/bin/public/openDownload?filename=pt_yolox-nano_3.5.zip unzip openDownload\?filename\=pt_yolox-nano_3.5.zip |
「quantized」のフォルダの中に「yolox_nano_onnx_pt.onnx」があります。
特にコンパイルなどせず、そのままKR260に送ります。

ONNXのYOLOXのPythonのプログラム(.py)
実際に動かしたプログラムは下記GitHubに置いています。
このプログラムをKR260上で実行しています。
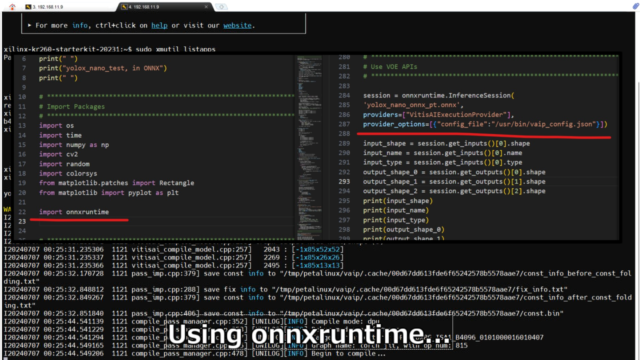
onnxruntimeをインポートして、onnxで推論できるようにセッションを作成しています。
プログラムの一部を下記に記載します。
公式の手順ではconfigファイルが下記記載でしたが、KR260上の配置に修正しました。
provider_options=[{"config_file":"/etc/vaip_config.json"}]
|
1 2 3 4 5 6 |
import onnxruntime session = onnxruntime.InferenceSession( 'yolox_nano_onnx_pt.onnx', providers=["VitisAIExecutionProvider"], provider_options=[{"config_file":"/usr/bin/vaip_config.json"}]) |
あとPyTorchをそのままONNXに変換しているため、特に高速化はできていません。
sigmoid,softmaxの処理もPyTorch同様に入れています。
あとONNXのためにswapもしているので、PyTorchより後処理は遅くなっています。
KR260でONNXのテスト
KR260に作成したファイルを送付します。
最初にDPUをxmutilでロードできるように設定しています。
b4096_300mというアプリケーションを作成しました。
|
1 2 3 4 5 |
ls /lib/firmware/xilinx/ sudo mkdir /lib/firmware/xilinx/b4096_300m sudo cp pl.dtbo shell.json /lib/firmware/xilinx/b4096_300m/ sudo cp dpu.xclbin /lib/firmware/xilinx/b4096_300m/binary_container_1.bin ls /lib/firmware/xilinx/b4096_300m/ |
また作成したvart.confに差し替えました。
|
1 2 3 |
sudo mv /etc/vart.conf /etc/old_vart.conf sudo cp vart.conf /etc/ sudo reboot |
一度Rebootするのをおススメします。
ここからは冒頭でも紹介したデモ動画の流れと同じになります。
最初にDPUのアプリケーション(b4096_300m)をロードします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
xilinx-kr260-starterkit-20231:~$ sudo xmutil listapps Password: Accelerator Accel_type Base Base_type #slots(PL+AIE) Active_slot b4096_300m XRT_FLAT b4096_300m XRT_FLAT (0+0) -1 k26-starter-kits XRT_FLAT k26-starter-kits XRT_FLAT (0+0) 0, xilinx-kr260-starterkit-20231:~$ sudo xmutil unloadapp remove from slot 0 returns: 0 (Ok) xilinx-kr260-starterkit-20231:~$ sudo xmutil loadapp b4096_300m b4096_300m: loaded to slot 0 xilinx-kr260-starterkit-20231:~$ sudo xmutil listapps Accelerator Accel_type Base Base_type #slots(PL+AIE) Active_slot b4096_300m XRT_FLAT b4096_300m XRT_FLAT (0+0) 0, k26-starter-kits XRT_FLAT k26-starter-kits XRT_FLAT (0+0) -1 |
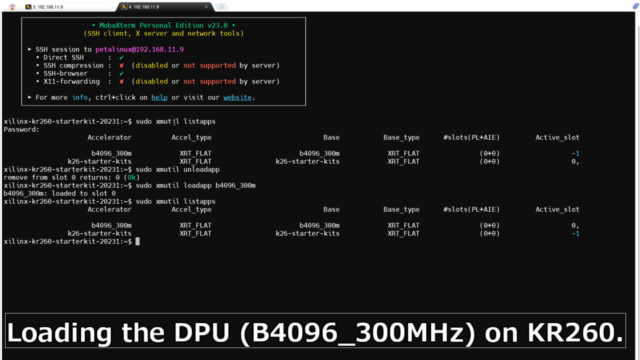
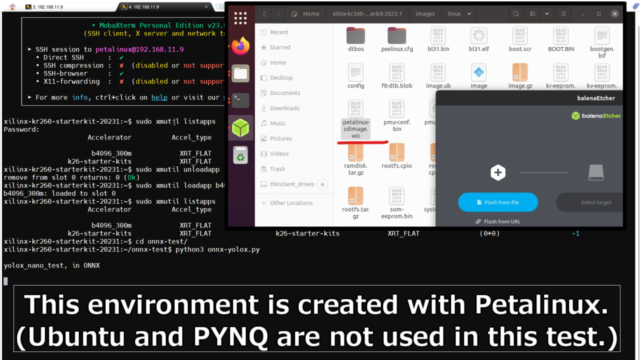
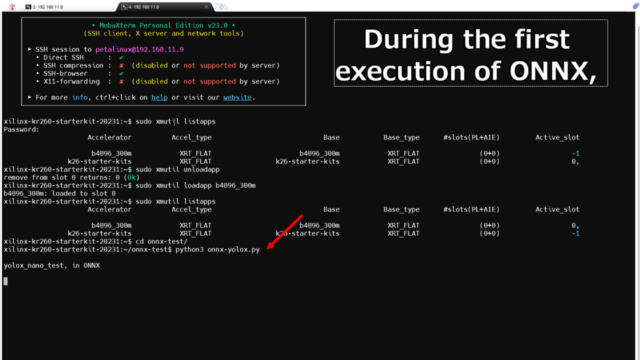
用意したPythonのプログラムを実行します。
onnx-testというフォルダ内で実行しています。
|
1 2 |
xilinx-kr260-starterkit-20231:~$ cd onnx-test/ xilinx-kr260-starterkit-20231:~/onnx-test$ python3 onnx-yolox.py |
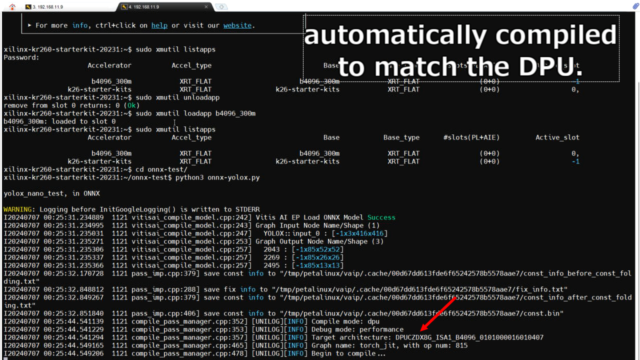
プログラムを実行すると、DPUに合わせるようにコンパイルが開始されます。
※最初は数分かかります。2回目以降はコンパイルは省略されて速くなります。
ログを見ると、ロードされているDPUを読み取り、DPUモードでコンパイルしています。
Debug mode: performance
Target architecture: DPUCZDX8G_ISA1_B4096_0101000016010407
Graph name: torch_jit, with op num: 815
Begin to compile...
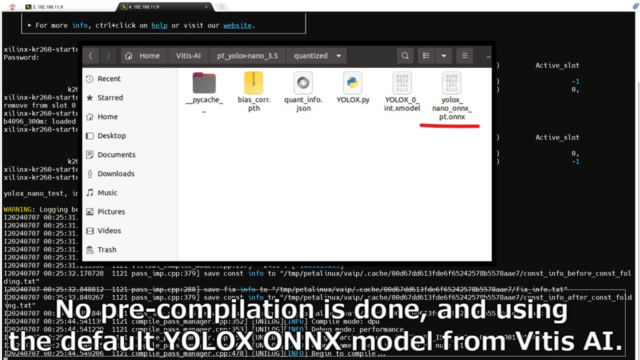
コンパイルが終わると、Pythonのプログラムが実行されます。
実際のログを貼り付けておきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
xilinx-kr260-starterkit-20231:~$ cd onnx-test/ xilinx-kr260-starterkit-20231:~/onnx-test$ python3 onnx-yolox.py yolox_nano_test, in ONNX WARNING: Logging before InitGoogleLogging() is written to STDERR I20240707 00:25:31.234889 1121 vitisai_compile_model.cpp:242] Vitis AI EP Load ONNX Model Success I20240707 00:25:31.234995 1121 vitisai_compile_model.cpp:243] Graph Input Node Name/Shape (1) I20240707 00:25:31.235031 1121 vitisai_compile_model.cpp:247] YOLOX::input_0 : [-1x3x416x416] I20240707 00:25:31.235271 1121 vitisai_compile_model.cpp:253] Graph Output Node Name/Shape (3) I20240707 00:25:31.235306 1121 vitisai_compile_model.cpp:257] 2043 : [-1x85x52x52] I20240707 00:25:31.235337 1121 vitisai_compile_model.cpp:257] 2269 : [-1x85x26x26] I20240707 00:25:31.235366 1121 vitisai_compile_model.cpp:257] 2495 : [-1x85x13x13] I20240707 00:25:32.170728 1121 pass_imp.cpp:379] save const info to "/tmp/petalinux/vaip/.cache/00d67dd613fde6f65242578b5578aae7/const_info_before_const_folding.txt" I20240707 00:25:32.848812 1121 pass_imp.cpp:288] save fix info to "/tmp/petalinux/vaip/.cache/00d67dd613fde6f65242578b5578aae7/fix_info.txt" I20240707 00:25:32.849267 1121 pass_imp.cpp:379] save const info to "/tmp/petalinux/vaip/.cache/00d67dd613fde6f65242578b5578aae7/const_info_after_const_folding.txt" I20240707 00:25:32.851840 1121 pass_imp.cpp:406] save const info to "/tmp/petalinux/vaip/.cache/00d67dd613fde6f65242578b5578aae7/const.bin" I20240707 00:25:44.541139 1121 compile_pass_manager.cpp:352] [UNILOG][INFO] Compile mode: dpu I20240707 00:25:44.541229 1121 compile_pass_manager.cpp:353] [UNILOG][INFO] Debug mode: performance I20240707 00:25:44.541294 1121 compile_pass_manager.cpp:357] [UNILOG][INFO] Target architecture: DPUCZDX8G_ISA1_B4096_0101000016010407 I20240707 00:25:44.549165 1121 compile_pass_manager.cpp:465] [UNILOG][INFO] Graph name: torch_jit, with op num: 815 I20240707 00:25:44.549206 1121 compile_pass_manager.cpp:478] [UNILOG][INFO] Begin to compile... W20240707 00:27:51.125735 1121 PartitionPass.cpp:4160] [UNILOG][WARNING] xir::Op{name = onnx::Conv_232_vaip_1, type = transpose} has been assigned to CPU. W20240707 00:27:51.551687 1121 PartitionPass.cpp:4160] [UNILOG][WARNING] xir::Op{name = 2495, type = transpose} has been assigned to CPU. W20240707 00:27:51.610715 1121 PartitionPass.cpp:4160] [UNILOG][WARNING] xir::Op{name = 2269, type = transpose} has been assigned to CPU. W20240707 00:27:51.669713 1121 PartitionPass.cpp:4160] [UNILOG][WARNING] xir::Op{name = 2043, type = transpose} has been assigned to CPU. I20240707 00:28:25.202344 1121 compile_pass_manager.cpp:489] [UNILOG][INFO] Total device subgraph number 6, DPU subgraph number 1 I20240707 00:28:25.202572 1121 compile_pass_manager.cpp:504] [UNILOG][INFO] Compile done. I20240707 00:28:25.395335 1121 anchor_point.cpp:423] before optimization: onnx::Conv_232_vaip_1_fix <-- transpose@layoutransform -- onnx::DequantizeLinear_229 <-- identity@fuse_DPU -- onnx::DequantizeLinear_229 after optimization: onnx::Conv_232_vaip_1_fix <-- transpose@layoutransform -- onnx::DequantizeLinear_229 I20240707 00:28:25.395582 1121 anchor_point.cpp:423] before optimization: 2495_vaip_664 <-- transpose@fuse_transpose -- onnx::DequantizeLinear_2492 <-- identity@fuse_DPU -- onnx::DequantizeLinear_2492 after optimization: 2495_vaip_664 <-- transpose@fuse_transpose -- onnx::DequantizeLinear_2492 I20240707 00:28:25.395682 1121 anchor_point.cpp:423] before optimization: 2269_vaip_697 <-- transpose@fuse_transpose -- onnx::DequantizeLinear_2266 <-- identity@fuse_DPU -- onnx::DequantizeLinear_2266 after optimization: 2269_vaip_697 <-- transpose@fuse_transpose -- onnx::DequantizeLinear_2266 I20240707 00:28:25.395769 1121 anchor_point.cpp:423] before optimization: 2043_vaip_730 <-- transpose@fuse_transpose -- onnx::DequantizeLinear_2040 <-- identity@fuse_DPU -- onnx::DequantizeLinear_2040 after optimization: 2043_vaip_730 <-- transpose@fuse_transpose -- onnx::DequantizeLinear_2040 2024-07-07 00:28:26.281134980 [W:onnxruntime:, session_state.cc:1169 VerifyEachNodeIsAssignedToAnEp] Some nodes were not assigned to the preferred execution providers which may or may not have an negative impact on performance. e.g. ORT explicitly assigns shape related ops to CPU to improve perf. 2024-07-07 00:28:26.281221749 [W:onnxruntime:, session_state.cc:1171 VerifyEachNodeIsAssignedToAnEp] Rerunning with verbose output on a non-minimal build will show node assignments. I20240707 00:28:26.707309 1121 custom_op.cpp:141] Vitis AI EP running 723 Nodes ['YOLOX::input_0_dynamic_axes_1', 3, 416, 416] YOLOX::input_0 tensor(float) ['DequantizeLinear2043_dim_0', 85, 52, 52] ['DequantizeLinear2269_dim_0', 85, 26, 26] ['DequantizeLinear2495_dim_0', 85, 13, 13] |
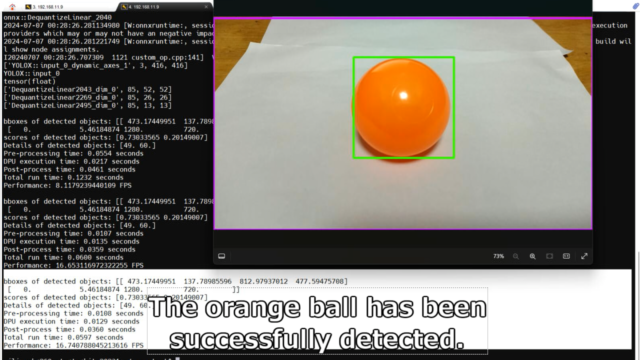
今回は写真1枚をYOLOXで画像認識しています。
実際に画像認識させた結果を表示すると、問題なくオレンジ色のボールが認識されていました。
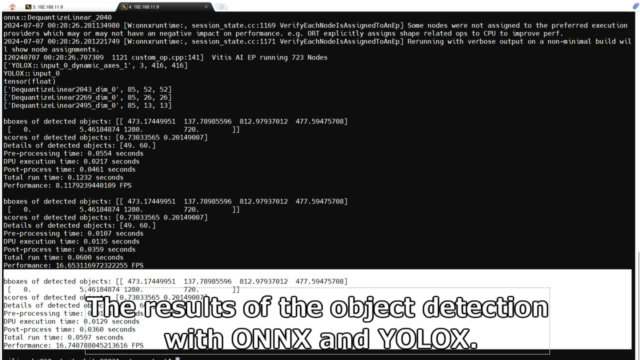
|
1 2 3 4 5 6 7 8 9 |
bboxes of detected objects: [[ 473.17449951 137.78985596 812.97937012 477.59475708] [ 0. 5.46184874 1280. 720. ]] scores of detected objects: [0.73033565 0.20149007] Details of detected objects: [49. 60.] Pre-processing time: 0.0108 seconds DPU execution time: 0.0129 seconds Post-process time: 0.0360 seconds Total run time: 0.0597 seconds Performance: 16.740788045213616 FPS |
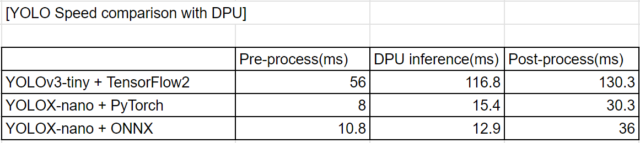
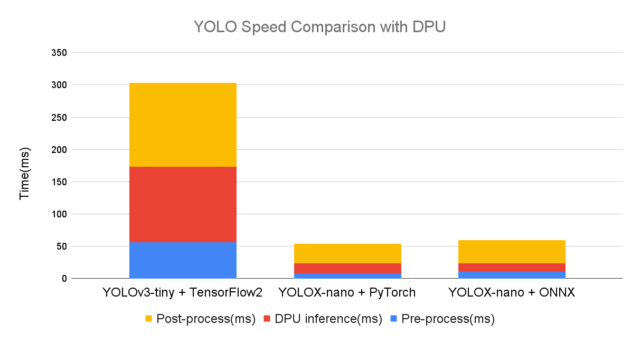
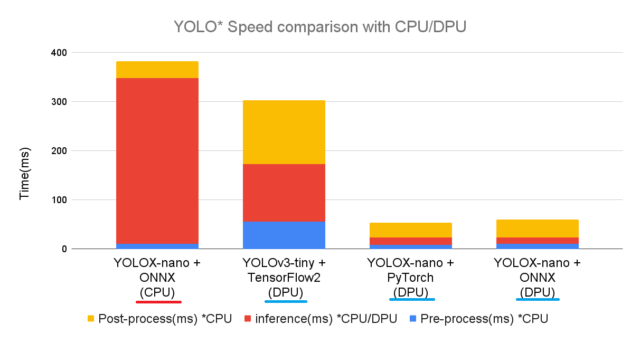
TensorFlow2のYOLOv3、PyTorchのYOLOXとの比較
正確な比較になりませんが、下記記事にてUbuntu環境でテストした内容と速度を比べてみます。
TensorFlow2のYOLOv3、PyTorchのYOLOXでも同様なテストをしました。
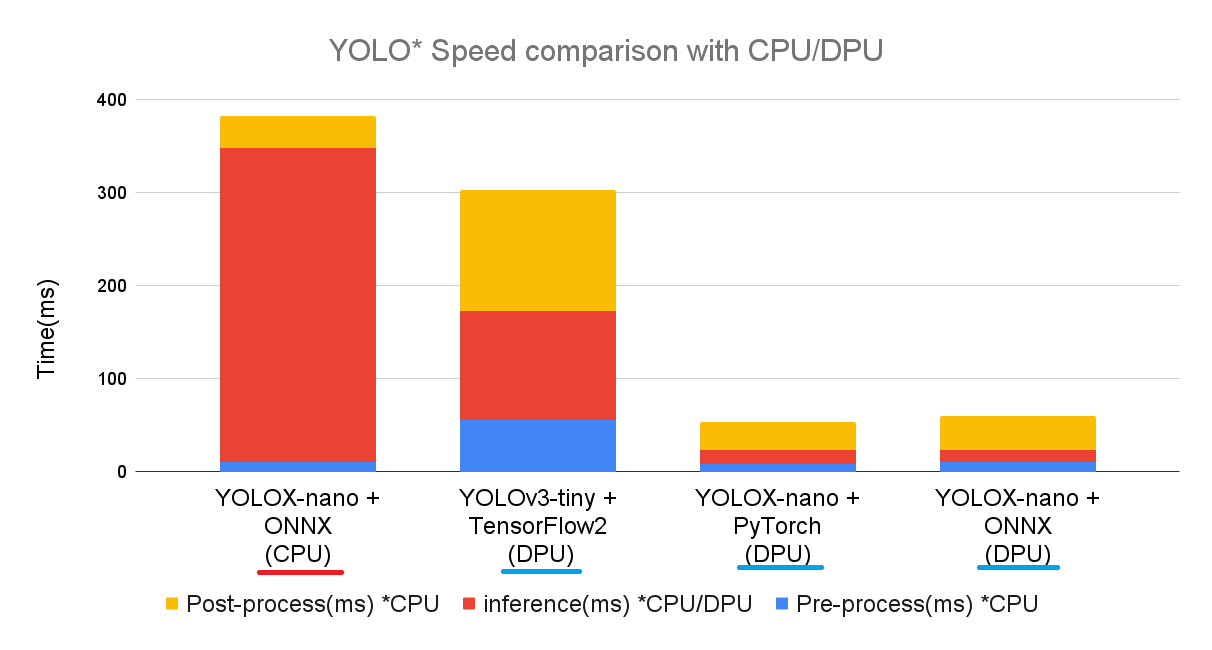
前処理・DPUでの推論・後処理の各比較をすると下記結果となりました。
今回のONNXのYOLOXでは、元のPyTorchから特に何も高速化していません。
YOLOXの2つはほぼ同じ結果となり、ある意味狙い通りの結果となりました。
ONNXでYOLOXのCPUとDPUを比較
ONNXを使えるようになると、KR260上のCPUとDPUの比較も簡単になります。
同じプログラムの1行を修正するだけで、DPUではなくCPUでの推論(inference)にできます。
providers=["CPUExecutionProvider"]
|
1 2 3 4 5 |
session = onnxruntime.InferenceSession( 'yolox_nano_onnx_pt.onnx', # providers=["VitisAIExecutionProvider"], providers=["CPUExecutionProvider"], provider_options=[{"config_file":"/usr/bin/vaip_config.json"}]) |
実際にテストしたデモ動画です。
ONNX+CPUでも問題なくYOLOXの物体検出が出来ています。
|
1 2 3 4 5 6 7 8 9 |
bboxes of detected objects: [[ 470.0975647 137.78985596 809.90246582 477.59475708] [ 0. 5.46184874 1280. 720. ]] scores of detected objects: [0.73085773 0.24486023] Details of detected objects: [49. 60.] Pre-processing time: 0.0106 seconds DPU execution time: 0.3372 seconds Post-process time: 0.0346 seconds Total run time: 0.3824 seconds Performance: 2.6150217559776725 FPS |
DPUの推論(inference)は、CPUと比べて約20倍以上の速度が出ていました。

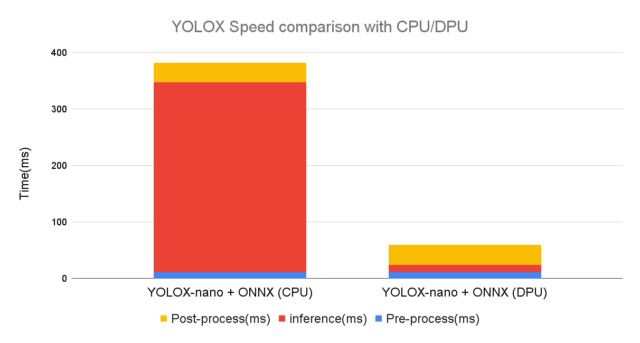
今までのYOLOv3とYOLOXのPyTorchとも、まとめて比較すると下記グラフになります。
DPUを使うことで高速化できることが、よく分かります。
まとめ
ONNXのYOLOXをDPUとPythonで動かしてみました。
KR260上でONNX専用の環境構築して、onnxruntimeを実行しています。
Vitis AI ONNXRuntime Engine (VOE) を使用した旨を紹介しました。
今回のKR260で実施した内容は、下記記事で紹介したテストの一部です。

コメント