KR260のDPUを使って、物体検出をしました。
YOLOX-nano+Pytorchの軽量のモデルを使用してます。
YOLOv3とYOLOXの実行速度の比較までした旨を紹介します。
PYNQでYOLOX-nano + PyTorchの物体検出してみた
KR260のDPUを使って、物体検出をしました。
「YOLOX-nano」+「Pytorch」の軽量のモデルを使用してます。
PYNQ上で動作するプログラム(.ipynb)を作成して、動作することが出来ました。
旧プログラムのYOLOv3との検出速度の比較もしました。
新プログラムのYOLOXが約5倍ほど高速化していることも確認しています。
実行+速度比較したテスト動画が下記となります。
モデル作成からプログラムの内容まで一連の流れを紹介します。
YOLOX
学習済のコンパイル前のモデルは、Xilinx(AMD)からサンプルが提供されています。
今回使用するサンプルは下記にあります。
https://github.com/Xilinx/Vitis-AI/tree/master/model_zoo/model-list/pt_yolox-nano_3.5
YOLOv3
DPU-PYNQのサンプルプログラムとしてYOLOv3-tinyがあります。
KR260+DPU環境で実行する方法は下記記事で紹介しています。
KR260とDPU-PYNQでYOLOv3の物体検出してみる
但しYOLOv3も大分古いVerのため、実際に使っていて検出速度が遅かったです
そのため比較的新しい+軽量のモデルであるYOLOX-nanoを使用しました。
折角なので、速度比較のベンチマーク対象としています。
Vitis AIでYOLOX-nanoのモデルを作成する
最初にLinux環境でKR260用のYOLOXのモデルを作成(コンパイル)します。
YOLOXのサンプルのモデルをダウンロードして解凍します。
|
1 2 |
wget https://www.xilinx.com/bin/public/openDownload?filename=pt_yolox-nano_3.5.zip unzip openDownload\?filename\=pt_yolox-nano_3.5.zip |
Vitis AIでコンパイル
Vitis AIを使ってコンパイルします。今回はpytorchのCPU版のVitis AIを立ち上げています。
(コンパイル自体はCPU版でもGPU版でも変わりありません。)
|
1 2 |
cd Vitis-AI/ ./docker_run.sh xilinx/vitis-ai-pytorch-cpu:latest |
先ほど作ったarch,jsonも引数にして、コンパイルします。
ここではDPUのサイズはB4096に合わせています。
必要に応じてファイルを移動させてください。コンパイルは下記のように実行できました
|
1 2 3 4 5 6 7 8 |
(vitis-ai-pytorch) vitis-ai-user@iotengineer-Inspiron-3650:/workspace/pt_yolox-nano_3.5$ history 1 cd pt_yolox-nano_3.5/ 2 conda activate vitis-ai-pytorch 3 echo '{' > arch.json 4 echo ' "fingerprint": "0x101000016010407"' >> arch.json 5 echo '}' >> arch.json 6 vai_c_xir -x quantized/YOLOX_0_int.xmodel -a arch.json -n yolox_nano_pt -o ./yolox_nano_pt 7 history |
コンパイル後に作成されるフォルダの中に.xmodelが作成されます。
PYNQでのプログラム作成
PYNQ上で動作するプログラムを作成します。今回は.ipynbで作っています。
サンプルプログラムのYOLOv3とはアルゴリズムが違うので、ある程度修正する必要がありました。
実際に動作させたプログラムは下記GitHubに置いています。詳細は下記を参考ください。
概要としては、通常のYOLOX-nanoの処理を行っています。
前処理→DPUでの入出力→後処理→BBOX書き出しを行っています。
通常だとCPUかGPUで推論する箇所を、DPU推論させています。(あと実行時間の測定もしています)
- 前処理…416x416に画像をリサイズ+空いたスペースにパディング処理(114)
- DPU推論…モデル入出力 (1,416,416,3) → ((1, 52, 52, 85) (1, 26, 26, 85) (1, 13, 13, 85))
- 後処理…グリッド・ストライド・nmsなどの処理
- BBOX書き出し…バウンディングボックスを写真に追加
プログラムの一部ですが、下記がメイン箇所です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
def run(image_index, display=False): input_shape=(416, 416) class_score_th=0.3 nms_th=0.45 nms_score_th=0.1 start_time = time.time() input_image = cv2.imread(os.path.join(image_folder, original_images[image_index])) start_time = time.time() # Pre-processing pre_process_start = time.time() #temp_image = copy.deepcopy(input_image) image_height, image_width = input_image.shape[0], input_image.shape[1] image_size = input_image.shape[:2] image_data, ratio = preprocess(input_image, input_shape) pre_process_end = time.time() # Fetch data to DPU and trigger it dpu_start = time.time() image[0,...] = image_data.reshape(shapeIn[1:]) #output_folder = "img/" #result_path = os.path.join(output_folder, f'preprocess.jpg') #cv2.imwrite(result_path, image[0]) job_id = dpu.execute_async(input_data, output_data) dpu.wait(job_id) dpu_end = time.time() # postprocess decode_start = time.time() outputs = np.concatenate([output.reshape(1, -1, output.shape[-1]) for output in output_data], axis=1) bboxes, scores, class_ids = postprocess( outputs, input_shape, ratio, nms_th, nms_score_th, image_width, image_height, ) decode_end = time.time() end_time = time.time() # draw_bbox draw_start = time.time() if display: bboxes_with_scores_and_classes = [] for i in range(len(bboxes)): bbox = bboxes[i].tolist() + [scores[i], class_ids[i]] bboxes_with_scores_and_classes.append(bbox) bboxes_with_scores_and_classes = np.array(bboxes_with_scores_and_classes) display = draw_bbox(input_image, bboxes_with_scores_and_classes, class_names) output_folder = "img/" result_path = os.path.join(output_folder, f'result.jpg') cv2.imwrite(result_path, display) draw_end = time.time() print("Details of detected objects: {}".format(class_ids)) print("Pre-processing time: {:.4f} seconds".format(pre_process_end - pre_process_start)) print("DPU execution time: {:.4f} seconds".format(dpu_end - dpu_start)) print("Post-process time: {:.4f} seconds".format(decode_end - decode_start)) #print("Draw boxes time: {:.4f} seconds".format(draw_end - draw_start)) print("Total run time: {:.4f} seconds".format(end_time - start_time)) print("Performance: {} FPS".format(1/(end_time - start_time))) return bboxes, scores, class_ids |
KR260でテスト
冒頭でも紹介しましたがテスト動画は下記です。
Webブラウザ経由でKR260のipynbファイルを開いています。
Pytorchで変換したYOLOXのモデルを使用しています。
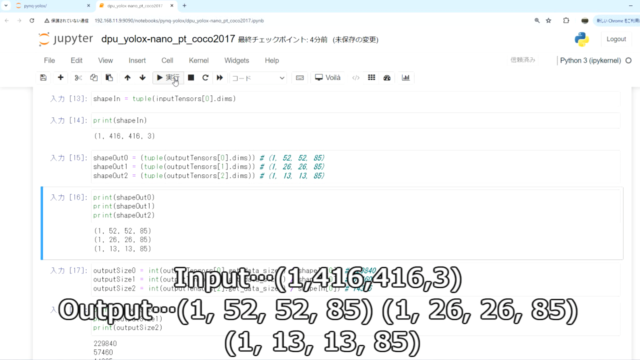
入出力のTensorを確認しています。
(1,416,416,3) → ((1, 52, 52, 85) (1, 26, 26, 85) (1, 13, 13, 85))を確認しています。
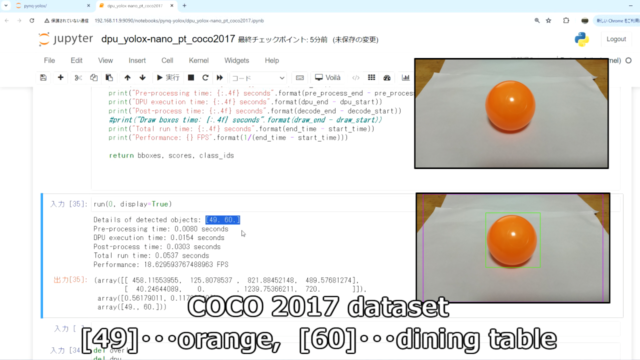
今回のYOLOXはCOCOの80カテゴリで物体検出をしています。
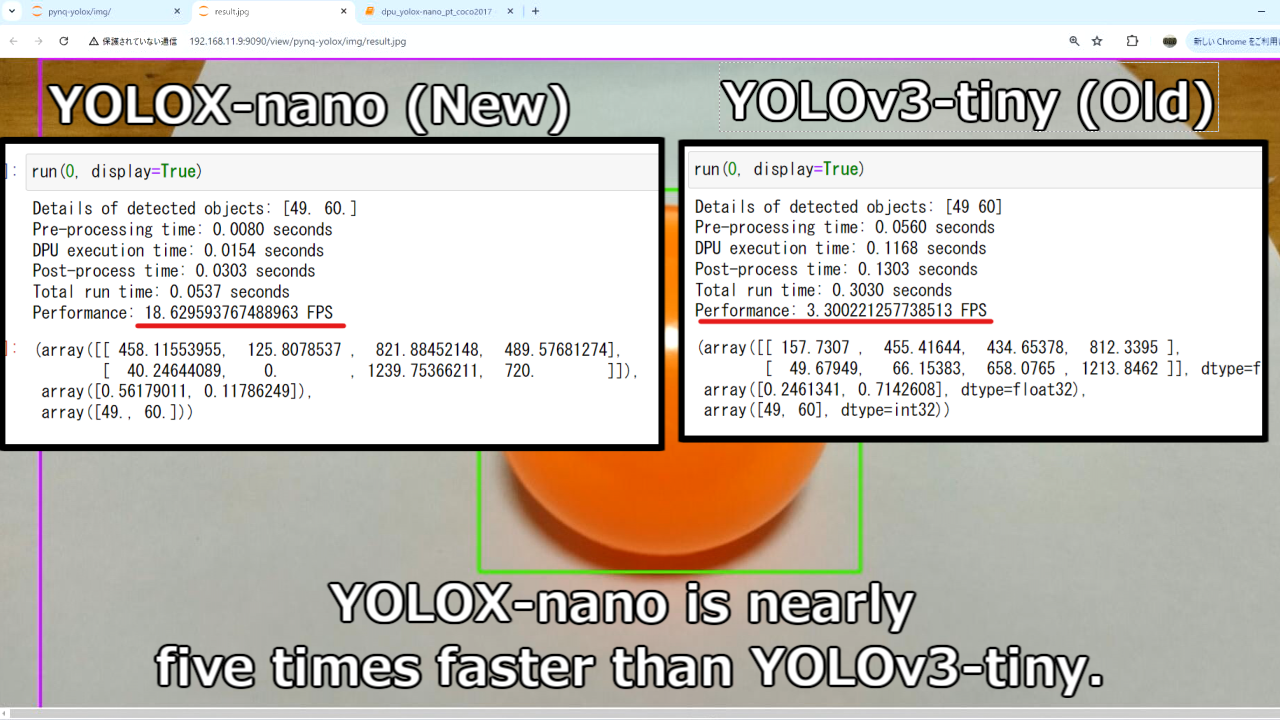
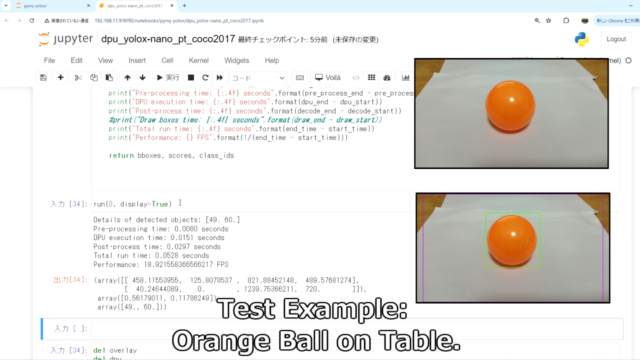
物体検出のテストです。テーブルに乗ったオレンジボールで確認しています。
しっかりオレンジ[49]とダイニングテーブル[60]が検出できています。
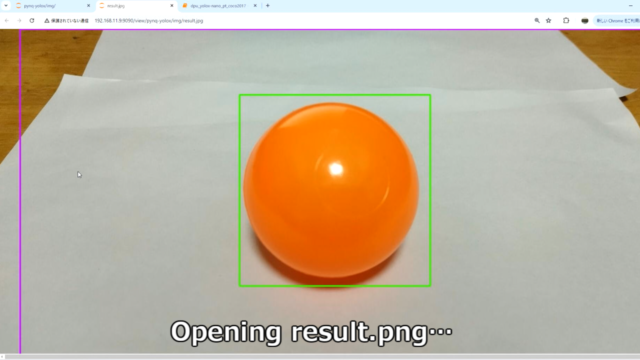
物体検出した結果をresult.pngで保存するようにしています。
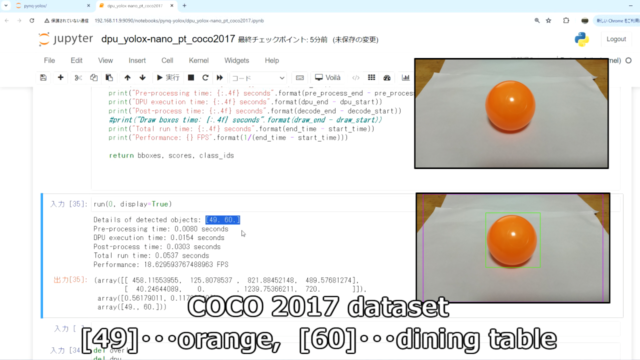
YOLOX-nanoとYOLOv3-tinyの検出速度比較
今回のYOLOX-nanoと古いYOLOv3-tinyで、検出速度の比較してみました。
(あくまで写真1枚の比較例です。)実行環境は同じDPU(B4096)で実施しています。
- DPUの実行時間…0.1168→0.0154 約1/8の検出時間
- CPUの後処理時間…0.1303→0.0303 約1/4の検出時間
- Totalの処理時間…3.30→18.6(FPGA) 約5倍の速度
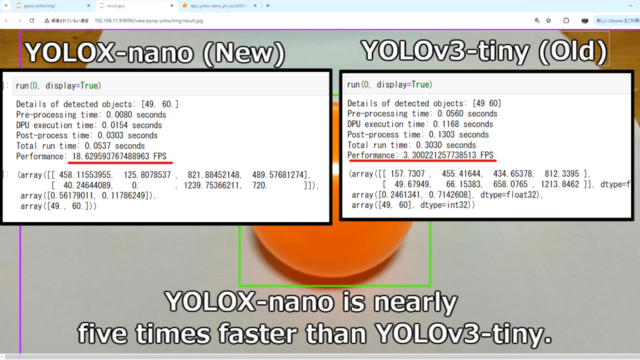
YOLOX-nanoが下記になります。
|
1 2 3 4 5 6 7 8 9 10 11 |
Details of detected objects: [49. 60.] Pre-processing time: 0.0080 seconds DPU execution time: 0.0154 seconds Post-process time: 0.0303 seconds Total run time: 0.0537 seconds Performance: 18.629593767488963 FPS (array([[ 458.11553955, 125.8078537 , 821.88452148, 489.57681274], [ 40.24644089, 0. , 1239.75366211, 720. ]]), array([0.56179011, 0.11786249]), array([49., 60.])) |
YOLOv3-tinyが下記になります。
|
1 2 3 4 5 6 7 8 9 10 11 |
Details of detected objects: [49 60] Pre-processing time: 0.0560 seconds DPU execution time: 0.1168 seconds Post-process time: 0.1303 seconds Total run time: 0.3030 seconds Performance: 3.300221257738513 FPS (array([[ 157.7307 , 455.41644, 434.65378, 812.3395 ], [ 49.67949, 66.15383, 658.0765 , 1213.8462 ]], dtype=float32), array([0.2461341, 0.7142608], dtype=float32), array([49, 60], dtype=int32)) |
360°の物体検出にもYOLOXを展開してみる
今回のYOLOXを360°ライブストリーミングの物体検出にも応用してみました。
YOLOXのテストプログラムが下記となります。
テストした動画が下記となります。
元々360°カメラが古くUSB2.0のタイプのため、単純なライブストリーミングでも6fps程度でした。
1920x960の画像を前後で2分割して、960x960の画像を2つ表示してます。
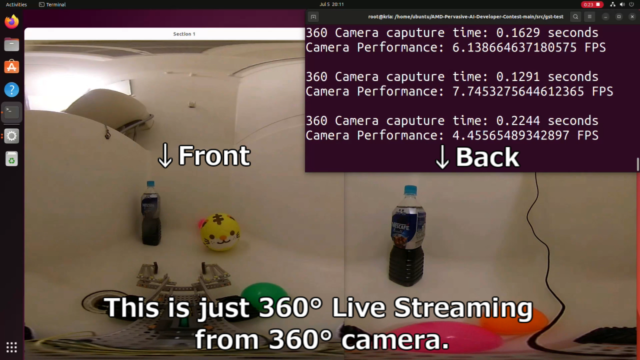

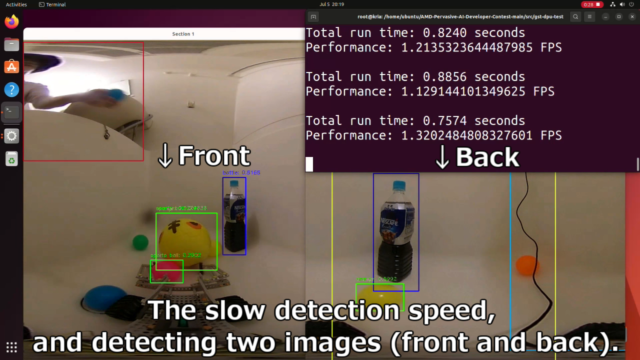
実行速度が遅いYOLOv3の物体検出を実装すると、約1.5fpsまで低下しました。
毎回2枚分の画像を物体検出していますので、影響を大きいです。

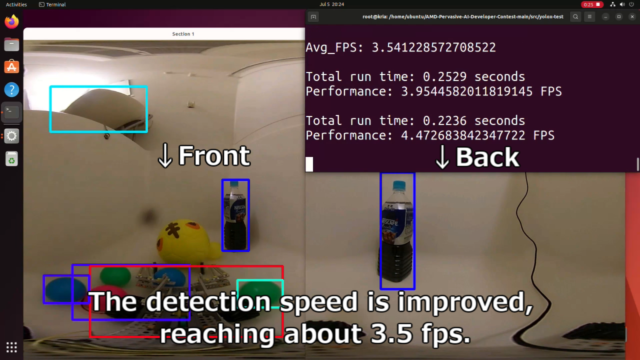
YOLOXに変更すると1.5fps→3.5fps程度になり、大分改善されました。
更に効率よくスレッド化したりすれば、より6fpsに近づいていけそうです。

参照先
・YOLOX-ONNX-TFLite-Sample
https://github.com/Kazuhito00/YOLOX-ONNX-TFLite-Sample/
YOLOv3→Xにして高速化しましたが、この方のコードを本当に参考にさせていただきました。
まとめ
KR260のDPUを使って、物体検出をしました。
YOLOX-nano+Pytorchの軽量のモデルを使用してます。
YOLOv3とYOLOXの実行速度の比較までした旨を紹介しました。
今回のKR260で実施した内容は、下記記事で紹介したテストの一部です。


コメント