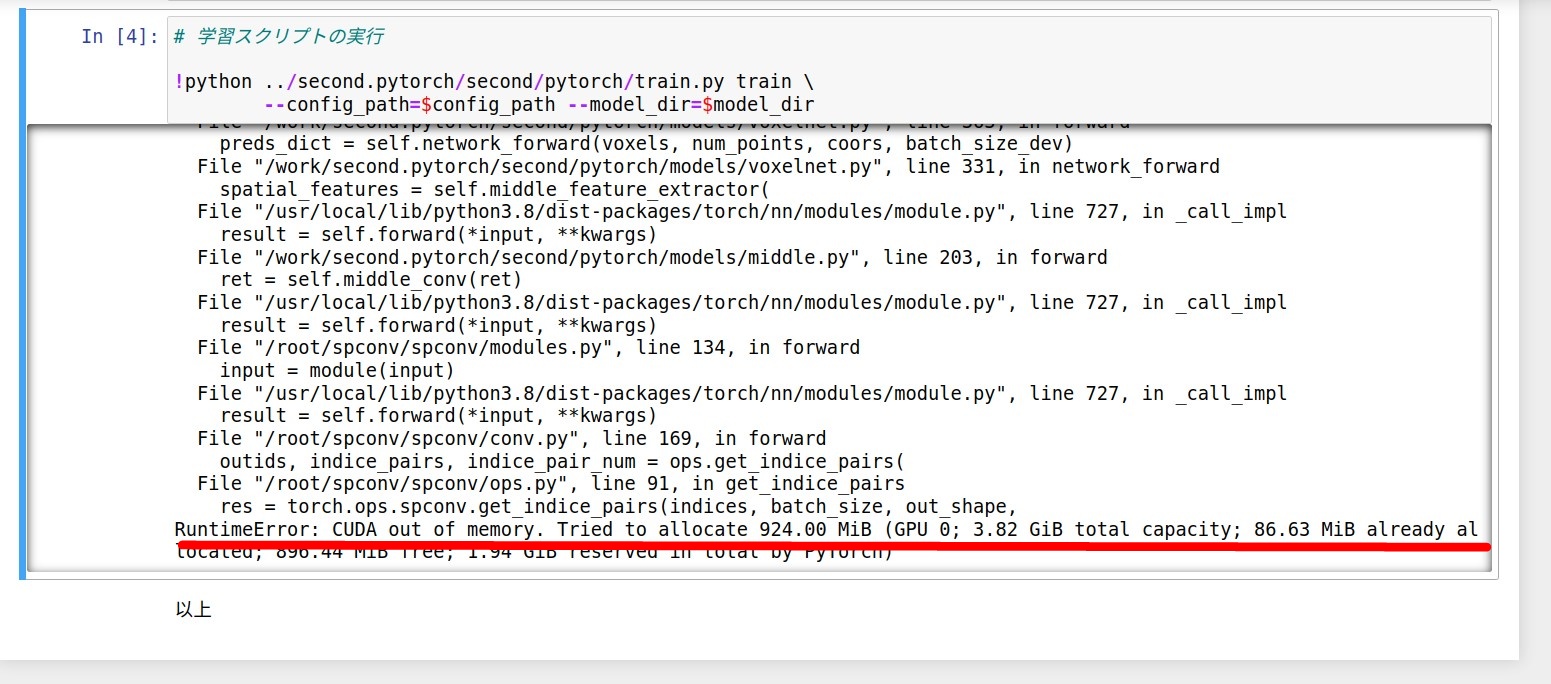
Pytorchで機械学習を回しているときにGPUメモリ不足でエラーになりました。
一番簡単な対策として、バッチサイズ(batchsize)の変更をしました。
CUDA out of memoryになったときに対応したメモを紹介します
機械学習でgpuメモリ不足のためバッチサイズを変更したメモ
デスクトップPCのGPUで機械学習を回しているとエラーが発生しました。
GPUのメモリ不足のエラーです。
RuntimeError: CUDA out of memory
File "/usr/local/lib/python3.8/dist-packages/torch/nn/functional.py", line 2056, in batch_norm
return torch.batch_norm(
RuntimeError: CUDA out of memory. Tried to allocate 32.00 MiB (GPU 0; 3.82 GiB total capacity; 1.16 GiB already allocated; 29.44 MiB free; 1.22 GiB reserved in total by PyTorch)
使用しているグラボが補助電源無しのGTX1650のため、GPUのメモリが4GBしかありません。
そのため、重い学習をすると簡単にエラーが発生します。
今回はバッチサイズを小さくすることで対応しました。その内容を紹介します。
テスト環境(PCスペック)
PCスペックは下記の通りです。
- CPU…Core i5 6400
- GPU…NVIDIA GeForce GTX1650(GDDR6 4GB)
- メモリ…16GB
- SSD…1000GB
筆者が使用しているグラフィックボードに関しては玄人志向のGTX1650となります。
補助電源無しで取り付けやすく、そこそこの性能を出してくれるGPUです。
ただ機械学習させるにはGPUメモリが4GBしかなく、物足りないケースも多々です。

GTX1650をPCに搭載した内容は下記記事で紹介しています。(リンク先はこちら)

KITTI(自動車のデータセット)の3D物体検出
第6回AIエッジコンテストでは、リファレンス環境が用意されていました。
KITTIもしくはコンテストのデータセットで3D物体検出ができるようになっています。
(KITTI…自動車(点群データ+画像)のデータセット。誰でも簡単に入手できます)
https://github.com/pometa0507/6th-ai-reference
docker上、またはColab上でも実行できるようになっています。
Colab上ではGPUのメモリ16GBあるので問題無し
Colabで動かす分には、問題なく学習・評価ができるはずです。
古いGPU(Tesla T4)が選ばれても、メモリは16GBと市販のPCに比べて多いはずです。
Memory-Usage … 15109MiB
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 38C P0 25W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
ただ、最近のColabは利用可能なユニット数(リソース)が管理されています。
(2022年夏ぐらいまでは、ある程度自由に使えたのですが最近は難しいです)
筆者含めてColabでなく、自宅にあるPCで学習させたい人が多数だと思います。
dockerだとPCのGPU次第
個人のPCのdokcer上で学習すると、装着しているGPUによります。
筆者のはメモリ4GBなので、Colab環境に比べて1/4と非常に小さいです。
Memory-Usage…3910MiB
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 465.19.01 Driver Version: 465.19.01 CUDA Version: 11.3 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... On | 00000000:01:00.0 Off | N/A |
| 35% 43C P8 N/A / 75W | 16MiB / 3910MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 913 G /usr/lib/xorg/Xorg 9MiB |
| 0 N/A N/A 1041 G /usr/bin/gnome-shell 4MiB |
+-----------------------------------------------------------------------------+
そのままGithubのデフォルトの設定で動かすと、GPUのメモリ不足のエラーが出ました。
学習(train)と評価(eval)の箇所です。
RuntimeError: CUDA out of memory
File "/usr/local/lib/python3.8/dist-packages/torch/nn/functional.py", line 2056, in batch_norm
return torch.batch_norm(
RuntimeError: CUDA out of memory. Tried to allocate 32.00 MiB (GPU 0; 3.82 GiB total capacity; 1.16 GiB already allocated; 29.44 MiB free; 1.22 GiB reserved in total by PyTorch)
バッチサイズ(batch_size)を変更する
メモリ不足になっている学習と評価のコンフィグを変更します。
今回の学習だと「/second.pytorch/second/configs/all.fhd_painted.config」箇所です。
train(学習)とeval(評価)箇所の両方のbatch_sizeを減らします。
batch_size: 3 → batch_size: 1
train_input_reader: {
dataset: {
dataset_class_name: "KittiDataset"
kitti_info_path: "../data/kitti/kitti_infos_train.pkl" # "/media/yy/960evo/datasets/kitti/kitti_infos_train.pkl"
kitti_root_path: "../data/kitti" # "/media/yy/960evo/datasets/kitti"
}
batch_size: 1
preprocess: {
num_workers: 3
shuffle_points: true
max_number_of_voxels: 30000
eval_input_reader: {
dataset: {
dataset_class_name: "KittiDataset"
kitti_info_path: "../data/kitti/kitti_infos_val.pkl" # "/media/yy/960evo/datasets/kitti/kitti_infos_val.pkl"
kitti_root_path: "../data/kitti" # "/media/yy/960evo/datasets/kitti"
}
batch_size: 1
preprocess: {
max_number_of_voxels: 60000
shuffle_points: false
num_workers: 3
変更後は学習できました。バッチサイズが1の時にGPUメモリが2GB近く使っていました。
単純換算でデフォルトのバッチサイズが3だと、GPUメモリが6GB以上が必要そうです。
Memory-Usage…2084MiB / 3910MiB
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 465.19.01 Driver Version: 465.19.01 CUDA Version: 11.3 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... On | 00000000:01:00.0 Off | N/A |
| 30% 43C P2 N/A / 75W | 2084MiB / 3910MiB | 81% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 913 G /usr/lib/xorg/Xorg 9MiB |
| 0 N/A N/A 1041 G /usr/bin/gnome-shell 4MiB |
| 0 N/A N/A 3665 C python 2065MiB |
+-----------------------------------------------------------------------------+
まとめ
GPUメモリ不足でエラーの場合、バッチサイズの変更が一番簡単だと思います。
とりあえずCUDA out of memoryを回避したい、という場合に実施してみて下さい
今回の記事含めて、第6回AIエッジコンテストの一環でした。
下記にてコンテストでテスト・実施したことのまとめを紹介しています。


コメント