KR260で360°カメラの画像を物体検出してみました。
DPU-PYNQのサンプルプログラムを使って、YOLOv3でテストしています。
KR260で360°カメラの画像をYOLOv3の物体検出してみる
KR260から360°カメラを撮影してみました。
そして撮影した写真を、KR260でYOLOの物体検出のテストしています。

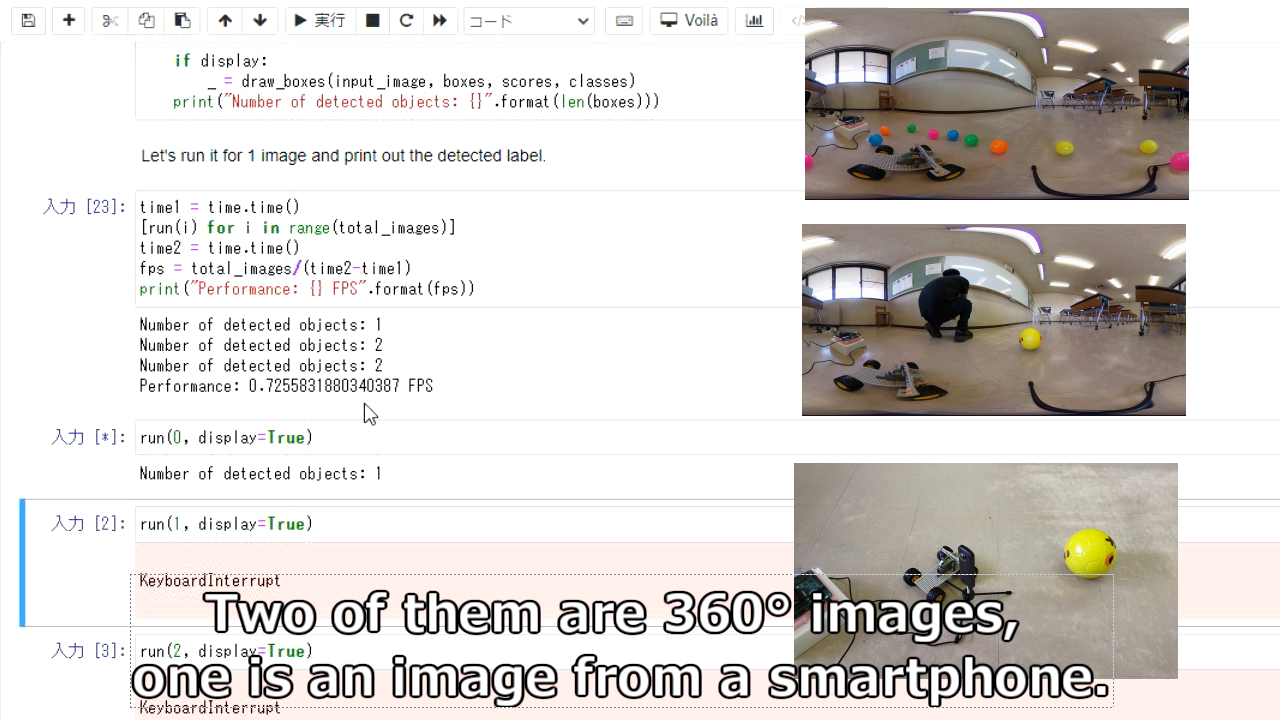
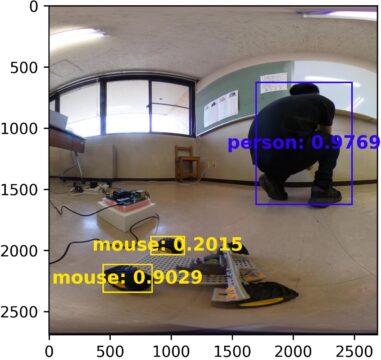
360°の画像を物体検出した結果です。
人は検出できていますが、黄色のボールが検出できていません。
やはり色々と補正が必要そうです。


2枚の画像に分割して、縦横比を1:1にするとより検出できるようになります。
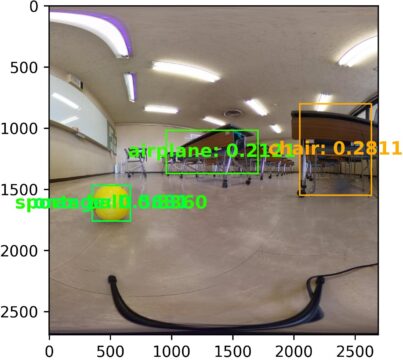
まず普通にスマートフォンで撮影した写真をKR260+Yoloで物体検出してみました。

普通の写真ではボールとして認識できています。
実際にjupyter_notebooksでテスト動画としては下記になります。
pythonのプログラムにしても同様にテストもしています。
元々PYNQ-DPUのサンプルプログラムがありましたので、それを修正した形です。
使用したモデル・修正方法に関して紹介していきます。
DPU-PYNQ
DPU-PYNQのサンプルプログラムは下記にあります。
その中に物体検出のYOLOのサンプルが入っています。(dpu_yolov3.ipynb)
コンテストの主催者側から提供された、下記をインストールすると自動的に入っています。
TensorFlow2 + YOLOv3
サンプルのままだと、若干古いTensorflowのフレームワークとなっています。
またデータセットもVOC2007とかなり古いです。
そのため同じyolov3ですが、まだ比較的新しいモデルを用意します。
Vitis AIの下記Tensorflow2のyolov3です。データセットはCOCO2017です
ダウンロード・解凍します。
|
1 2 |
wget https://www.xilinx.com/bin/public/openDownload?filename=tf2_yolov3_3.5.zip unzip openDownload\?filename\=tf2_yolov3_3.5.zip |
Vitis AIでコンパイル
PCでVitis-AIを起動して、TensorFlow2をアクティベートします。
今回はKR260用にモデルを作成しています。
|
1 2 3 4 5 6 7 8 |
(vitis-ai-tensorflow2) vitis-ai-user@iotengineer-Inspiron-3650:/workspace/tf2_yolov3_3.5$ history 1 conda activate vitis-ai-tensorflow2 2 cd tf2_yolov3_3.5/ 4 echo '{' > arch.json 5 echo ' "fingerprint": "0x101000016010407"' >> arch.json 6 echo '}' >> arch.json 5 vai_c_tensorflow2 -m quantized/quantized.h5 -a arch.json -n kr260_yolov3_tf2 -o ./compiled --options '{"input_shape": "1,416,416,3"}' 6 history |
モデル作成後はKR260に転送します。.xmodelを使います。
|
1 2 3 4 5 |
iotengineer@iotengineer-Inspiron-3650:~/Vitis-AI/tf2_yolov3_3.5$ scp -r compiled/ ubuntu@192.168.11.7:/home/ubuntu/ ubuntu@192.168.11.7's password: md5sum.txt 100% 33 23.1KB/s 00:00 meta.json 100% 189 161.6KB/s 00:00 kr260_yolov3_tf2.xmodel 100% 61MB 30.8MB/s 00:01 |
またCOCO2017用のリストを作成しときます。80種類のリストとなっています。
ipynbファイル
実際に動かしたipynbファイルは下記GitHubにファイルを置いています。
主に修正した箇所です。
作成したtf2のモデルをロードして、COCO2017のクラスで分類するようにしています。
またimgフォルダのJPGファイルを画像認識させるようにしています。
|
1 2 3 |
overlay.load_model("kr260_yolov3_tf2.xmodel") classes_path = "img/coco2017_classes.txt" original_images = [i for i in os.listdir(image_folder) if i.endswith("JPG")] |
KR260でipynbファイルを開いて、実行を進めていきます。
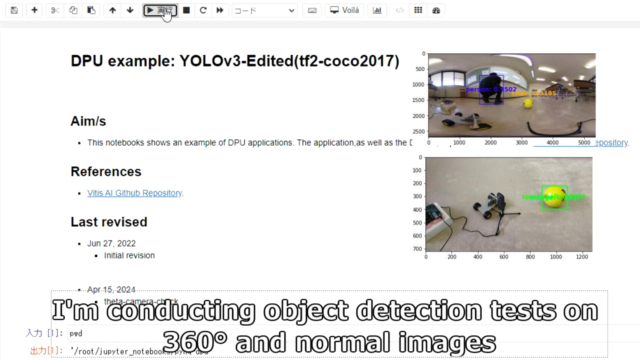
KR260でDPUを使うための.bitファイルはデフォルトのものを使用しています。
TensorFlow2のモデルを読み込んでいます。
VARTを使って、DPUでYOLOv3の物体検出を行います。
COCO2017の80のカテゴリで物体検出しています。
今回テストした写真は360°画像が2枚、普通のカメラ画像が1枚です。
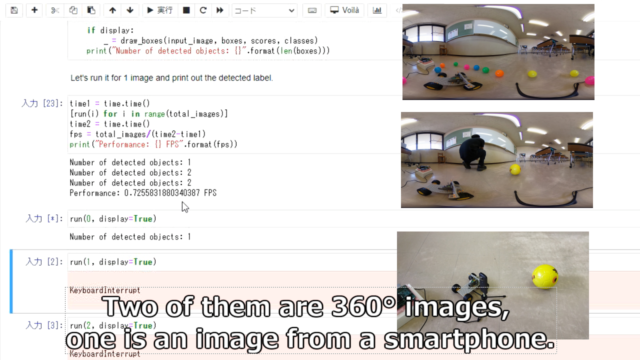
360°画像は上手く物体検出できていないことが分かります。
手前に並んでいるボールが全く検出できていません。
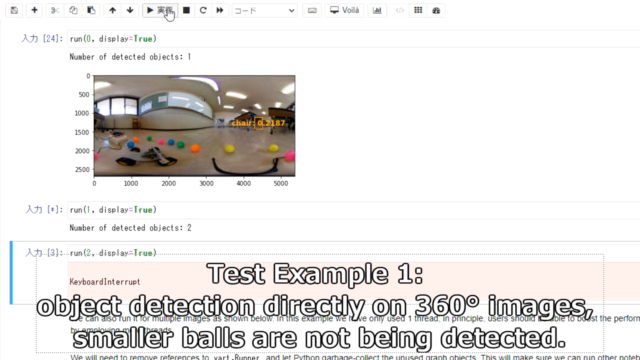
大きい人などは検出できますが、ボールなどは検出できていません。
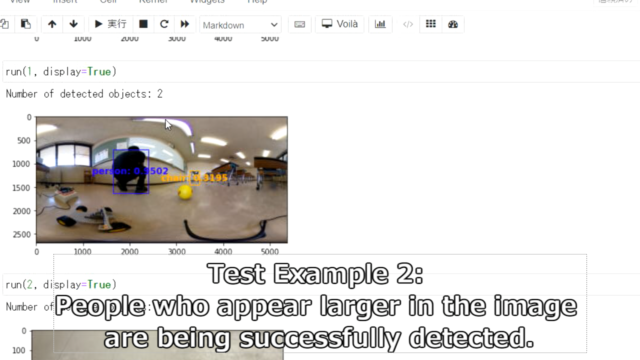
普通のスマホカメラで撮影した画像のボールは物体検出できています。

pythonファイル
同様なプログラムをpythonにして実行してみました。
こちらも下記GitHubに置いています
実行したコマンドの履歴は下記です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
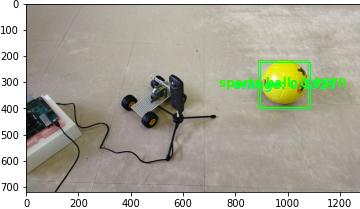
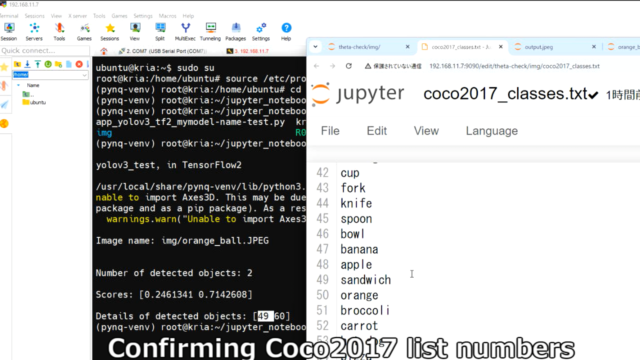
ubuntu@kria:~$ sudo su root@kria:/home/ubuntu# source /etc/profile.d/pynq_venv.sh (pynq-venv) root@kria:/home/ubuntu# cd $PYNQ_JUPYTER_NOTEBOOKS (pynq-venv) root@kria:~/jupyter_notebooks# cd theta-check/ (pynq-venv) root@kria:~/jupyter_notebooks/theta-check# ls app_yolov3_tf2_mymodel-name-test.py kr260_yolov3_tf2.xmodel theta_camera_check.ipynb img R0010155.JPG theta-dpu_yolov3_tf2_coco2017.ipynb (pynq-venv) root@kria:~/jupyter_notebooks/theta-check# python3 app_yolov3_tf2_mymodel-name-test.py yolov3_test, in TensorFlow2 /usr/local/share/pynq-venv/lib/python3.10/site-packages/matplotlib/projections/__init__.py:63: UserWarning: U nable to import Axes3D. This may be due to multiple versions of Matplotlib being installed (e.g. as a system package and as a pip package). As a result, the 3D projection is not available. warnings.warn("Unable to import Axes3D. This may be due to multiple versions of " Image name: img/orange_ball.JPEG Number of detected objects: 2 Scores: [0.2461341 0.7142608] Details of detected objects: [49 60] (pynq-venv) root@kria:~/jupyter_notebooks/theta-check# exit |
オレンジのボールを物体検出したところ、周りの机も検出していることが分かります。
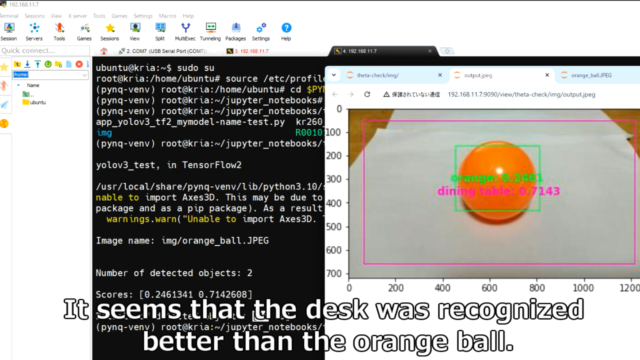
Coco2017のリストの49_orangeとして検出されています。
※txtファイルの番号は0ではなく1から数えているので、順番が一つずれています。
まとめ
KR260でDPU-PYNQを使って物体検出をしてみました。
.ipynbファイル、また.pyファイルからも実行できました。
今回のKR260で実施した内容は、下記記事で紹介したテストの一部です。


コメント