GoogleのAutoML Vision Edgeのサービスを使うことで機械学習で必要なモデルを簡単に作成でき、Edge TPUで画像認識を簡単に使えました。
機械学習の画像認識を「始めたい」「業務に使いたい」方におすすめの記事です。
AutoML Vision Edgeとは
Googleが提供しているクラウド上のサービスGoogle Cloud Platform(GCP)の一つです。
AutoML Vision Edgeは専門知識がない一般人でも、 最先端の機械学習と画像認識のエッジ用モデルを簡単に作成することができるサービスです。
AutoML Vision Edgeを使えば簡単にオリジナルの機械学習のモデルが作れます。今回は工具を分類する機械学習のモデルを作成する手順を1から紹介していきます。

そしてEdge TPUで画像認識するまでの記事となっています

簡単に機械学習を入門してみたい方は
特にオリジナルのモデルは必要なく「簡単に機械学習を始めてみたい」という方は下記記事をおすすめします(リンク先はこちらから)

ラズベリーパイ(raspberry pi)とEdge TPUのCoral USB Acceleratorを組み合わせることで、色々な機械学習(物体の検出・リアルタイムでの分類)を試しています

Google Cloud Platform(GCP)に登録する
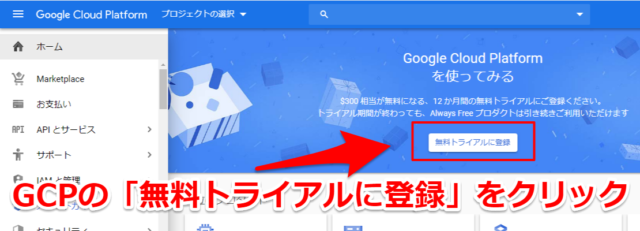
AutoML Vision Edgeを使うためには最初にGoogle Cloud Platform(GCP)に登録する必要があります。無料トライアルがあり、自動課金されることは無いので安心して使えます。
下記Google Cloud Platform(GCP)のURLから「無料トライアルに登録」をクリックします。(リンク先はこちらから)

特に迷うことは無いですが、最初に国や利用規約を確認して「同意して実行」を選択します。

その後に「お支払プロファイル」「お客様情報」を入力していきます。
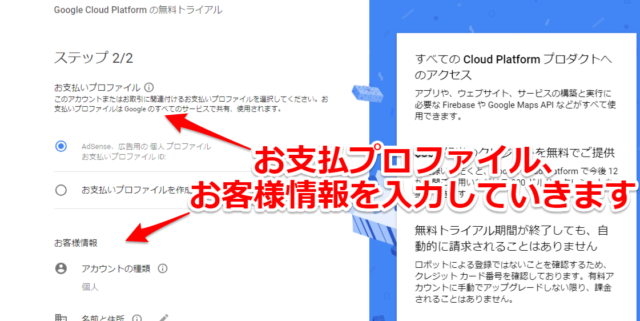
住所等の他にクレジットカードも登録する必要がありますが、あくまでロボットによる登録でないことを確認するためということです。自動課金されることはありません。
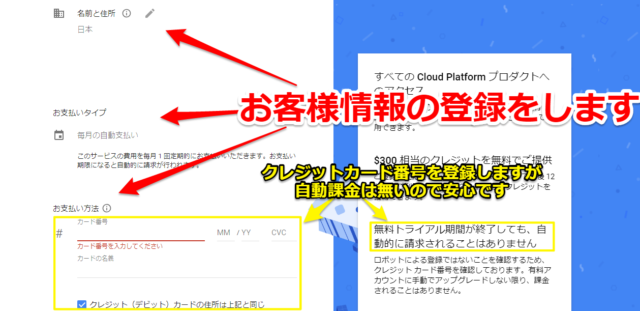
無事登録が終了すればGoogle Cloud Platform(GCP)が使えるようになります。
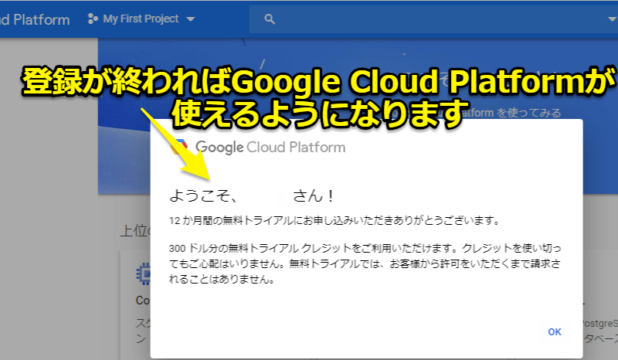
Googleの機械学習は無料枠内で使用できます
まだGCP未経験の方は「本当に無料なの?」「クラウドの課金制って怖くない?」と思われるかもしれません。ですが本当に無料枠内で使えます。

筆者が実際に今回紹介する機械学習で1時間ほどGCPを使ってみましたが、最初にもらえる無料トライアルのクレジットのおかげで無料(0円)でした。
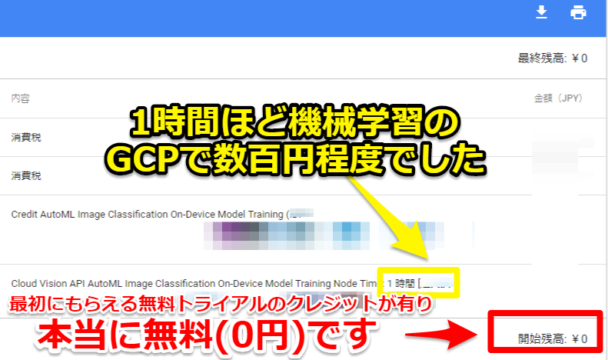
※今回の30枚の写真からAuto Ml Vision Edgeでモデルを作る簡単なケースで数百円ほどです。(あくまで1例なので詳細の金額は伏せています)
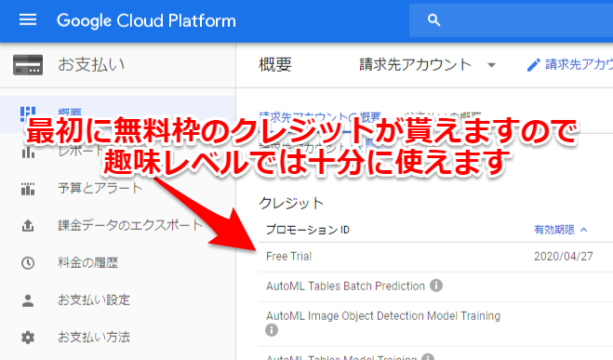
おそらく最初無料トライアルで約数万~十万ほどのクレジットが貰えますので、趣味レベルでは十分に使えると思います。
AutoML Vision Edgeの使い方・始め方
GCPに登録できましたので早速AutoML Vision Edgeを使っていきますが、その前に機械学習用に必要な写真を撮っておきます。
機械学習に必要な写真を撮っておく
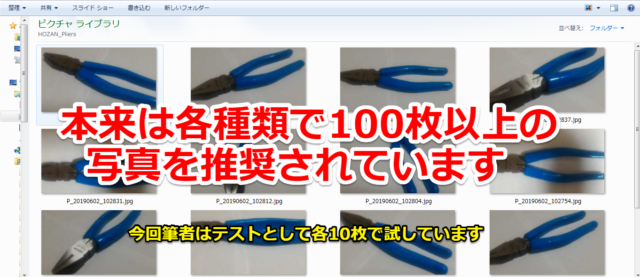
今回筆者は「ペンチ」「VESSEL製ワイヤーストリッパー」「HOZAN製ワイヤーストリッパー」の3種類を分類していきます。

本来は各種類で100枚以上の写真を用意することを推奨されていますが、今回は筆者はお試しテストということで各10枚で試しています。
最新のAutoML Visionの使い方
<<20200104追記>>
今回の記事で(ベータ版の)AutoML Vision Edgeの紹介をしますが、最新版の使い方を下記記事で説明しています。
基本的な流れは同じですが、設定に関して変更されている箇所もありますのでよろしければご覧ください。
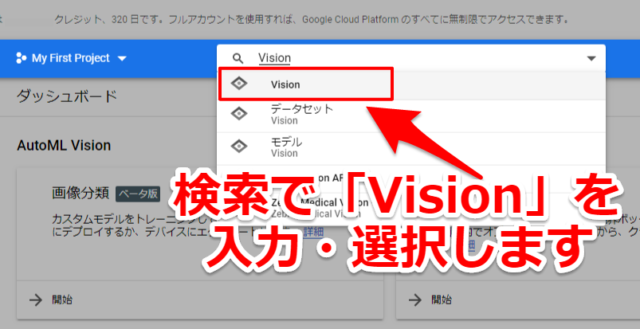
AutoML Visionを開始する
登録したGCPのページに行き、検索で「Vision」と入力して選択します
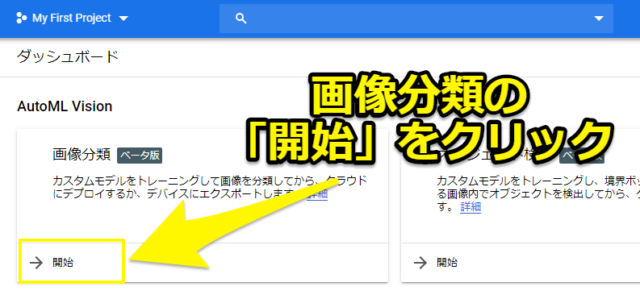
そして画像分類の「開始」をクリックします。
AutoML Visionでデータセット(DATASET)する
AutoML Visionの画面に切り替わりますので「NEW DATASET」を選択して、新しくデータセットを開始していきます。
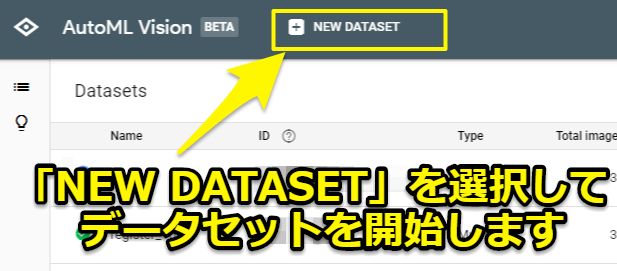
まずはデータセットの名前を入力します。各個人の自由に決めてもらえれば大丈夫です。筆者はtools(工具)としました。
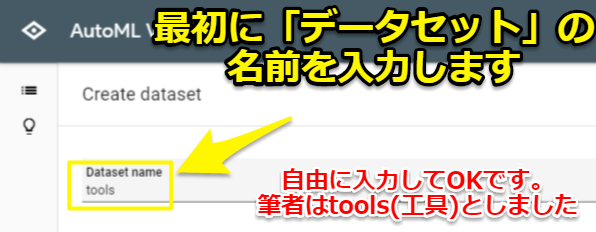
AutoML Visionに写真をアップロードする
次に機械学習用に撮った写真をアップロードしていきます。Import imagesの項目で「SELECT FILES」を選択します。
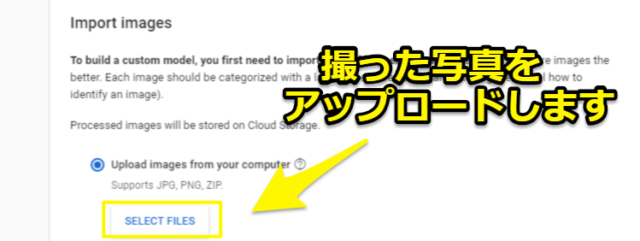
そして機械学習させたい写真を選択すればOKです。(一括ですべて選択しなくとも、写真は後でも追加できます)
GCP(Google Cloud Platform)に写真がアップロードされます。
AutoML Visionでラベルをつける
アップロードした写真にラベルを付けていきます。
最初に「Add label」の項目を選択して使うラベルを追加していきます。
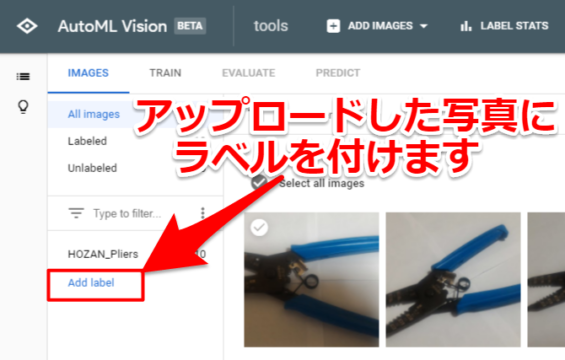
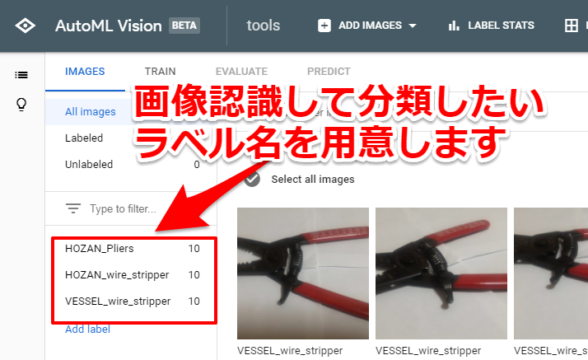
画像認識して分類させたいラベル名を付けてあげます。今回筆者は下記3つのラベル名を用意しました。
「ペンチ⇒HOZAN_Pliers」
「VESSEL製ワイヤーストリッパー⇒VESSEL_wire_stripper」
「HOZAN製ワイヤーストリッパー⇒HOZAN_wire_stripper」
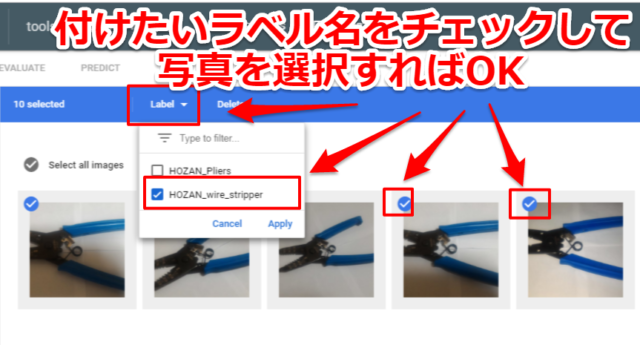
アップロードした写真にラベルを付ける
写真とラベル名を紐付るには「Label」のタブで登録したラベルをチェックして写真を選択していけばOKです。
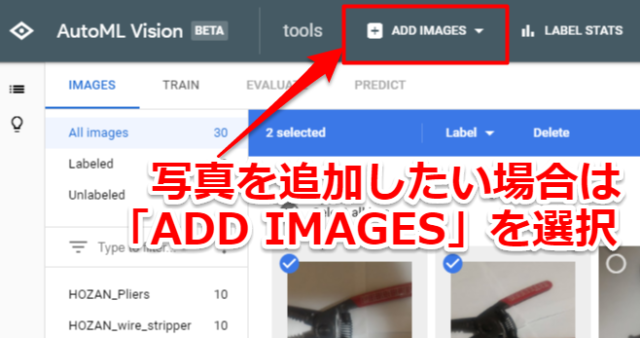
もし追加で写真をアップロードしたい場合は「ADD IMAGES」を選択してもらえれば大丈夫です
AutoML Visonでトレーニングをする
写真のアップロード・ラベルづけが終了しましたらデータをセットタブ「TRAIN」を選択します。
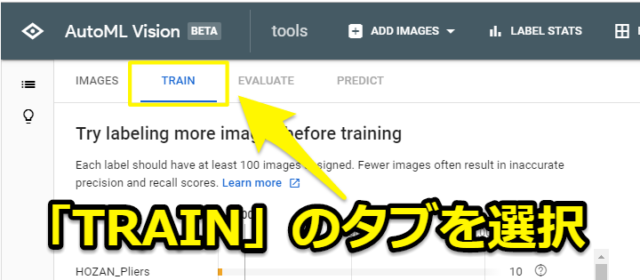
画面が切り替わりますので「START TRAINING」をクリックすることで機械学習のトレーニングの設定を行います。
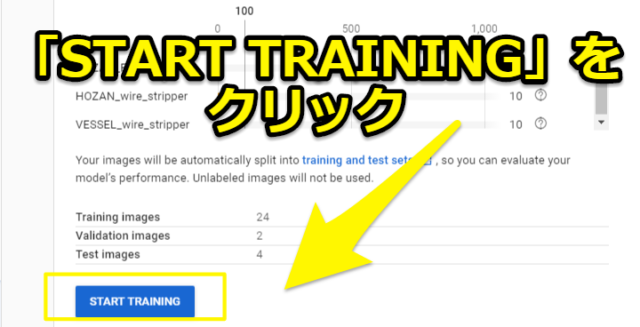
「Train new model」の画面が出てきますので、モデル名・モデルタイプを選択します。
筆者の場合はモデル名はデフォルト、タイプはEdgeを選択しています。

そして「Optimize model for:」の項目でモデルをどのように最適化するか、「Show latency estimates for」の項目で遅延の推定を決定します。
筆者は最適化を「Best trade-off」、遅延の推定は「Edge TPU」を選択しています。
「Set a node hour budget」の項目ではGCPのクラウド上で使うノード数を選択できます。
おそらく使うノード数を増やせば機械学習のトレーニングが早く終わる分、予算も高くなると思われます。筆者は推奨の「2 nodes hours」を選択しました。

最後に「START TRAINING」を選択すればトレーニングが開始されます。終わるまではしばらく待ちましょう。筆者の場合は1時間ほどで終わりました。
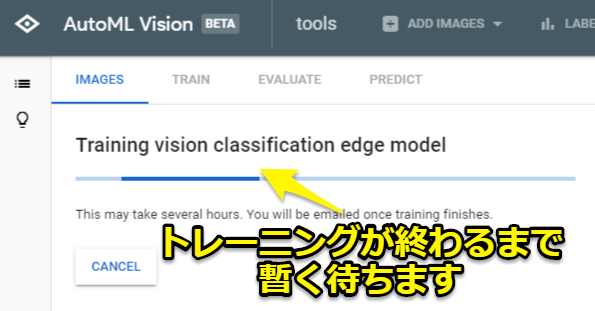
AutoML Visionの評価(EVALUATE)を確認する
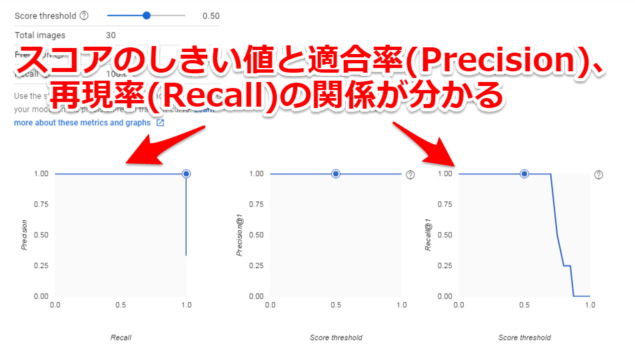
トレーニングが終われば機械学習のモデルを出力できますが、その前に結果(EVALUATE)を確認してみます。モデルのスコアの詳細を確認できます
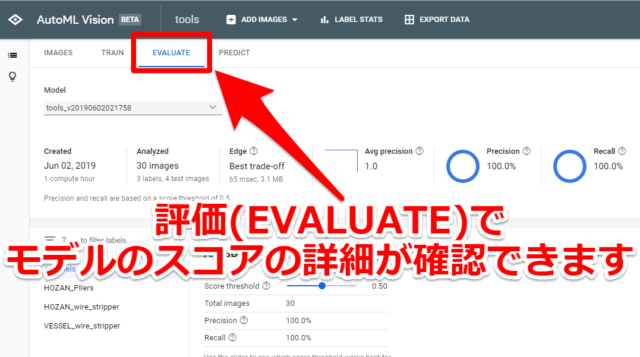
スコアのしきい値(Score threshold)と適合率(Precision)、再現率(Recall)の関係性が分かります。(詳細はGCPの初心者向けガイドに載っています。リンク先はこちら)
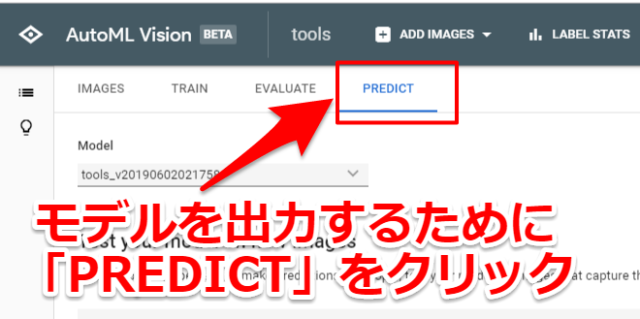
AutoML Visionでエッジのモデルを出力する
今回は作成したモデルを出力しますので「PREDICT」のタブをクリックします。
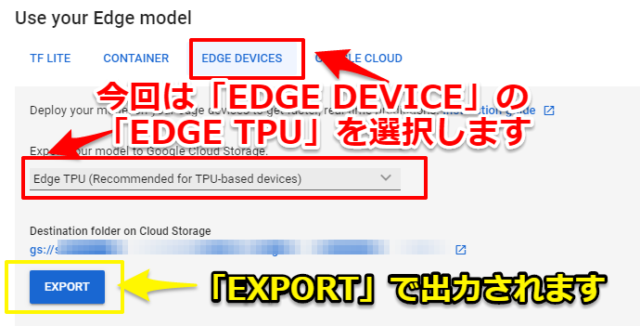
「Use Your Edge model」の項目で「EDGE DEVICE」→「Edge TPU」を選択して「EXPORT」クリックするとモデルが出力されます。
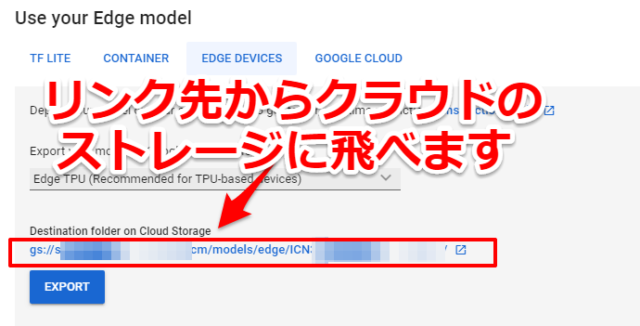
リンクが貼られているので出力先のクラウドのストレージに飛びます。
クラウドのストレージに出力されたモデルのフォルダがありますので選択します
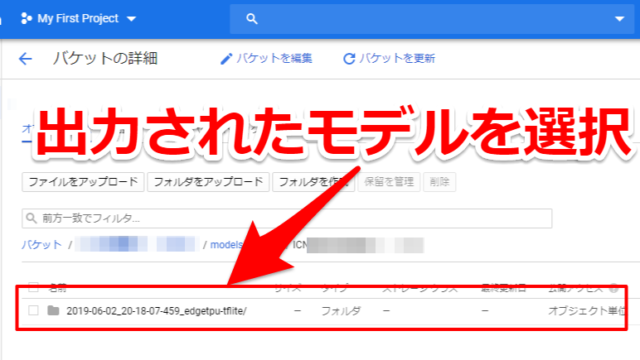
モデルを選択すると3つのファイルが出てきますのでダウンロードします。これで無事、機械学習のモデルを作成・入手することができました
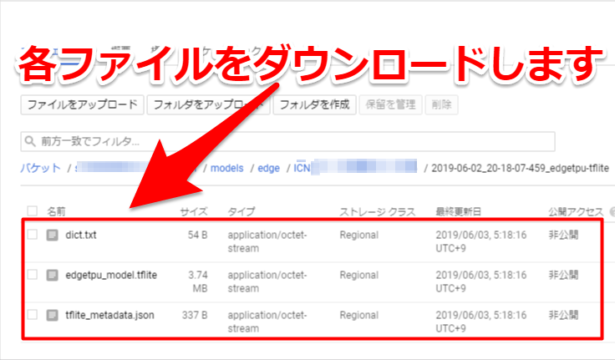
ダウンロードできるファイル
ダウンロードできる3つのファイル(dict.txt、model.tflite、tflite_metadata.json)を簡単に説明しときます
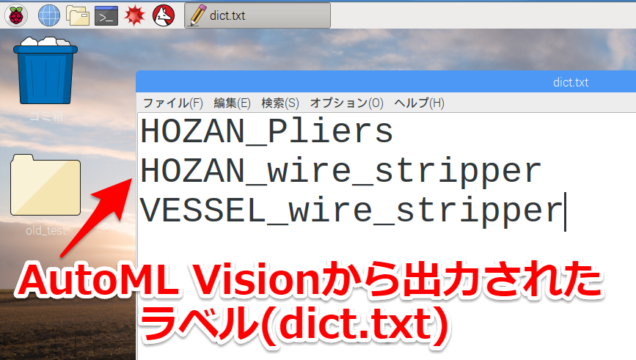
dict.txt…ラベルのテキスト情報。今回の場合は「HOZAN_Pliers」「VESSEL_wire_stripper」「HOZAN_wire_stripper」と登録した3つのラベル情報が入っていました。
HOZAN_wire_stripper
VESSEL_wire_stripper
model.tflite …TensorFlow Liteのモデルです。この機械学習のモデルを元に画像認識を行います
tflite_metadata.json…設定ファイル。モデル作った際の設定、対応しているTensorFlowのVer等が記載されています
"batchSize": 1,
"imageChannels": 3,
"imageHeight": 224,
"imageWidth": 224,
"inferenceType": "QUANTIZED_UINT8",
"inputTensor": "image",
"inputType": "QUANTIZED_UINT8",
"outputTensor": "scores",
"supportedTfVersions": [
"1.10",
"1.11",
"1.12",
"1.13"
]
}
AutoML Visionで作ったモデルをEdge TPUで使う
今回はAutoML Visionで作ったモデルをEdge TPUで使っていきたいと思います。

Edge TPUの使い方の詳細は以前の記事「Google Edge TPUを購入してラズベリーパイと機械学習してみた」ご確認ください。(リンク先はこちらから)

ラズベリーパイとEdge TPUで機械学習
Edge TPUはPythonで動作させていきます。筆者はラズベリーパイ(raspberry pi)とEdge TPUのCoral USB Accelerator環境下で動かしています。

今回は簡単なデモとして写真の画像認識を行いますが、応用すればEdge TPUならではのリアルタイムの画像認識も可能です。以前の記事で紹介しています。(リンク先はこちらから)

AutoML Visionで出力されたラベルを修正する
まずは必要なファイル(dict.txt,model.tflite,画像認識させたい写真)をラズベリーパイ側にコピーしときます。
(今回は設定ファイルのtflite_metadata.jsonは今回は特に必要としません。)
あとラベル(dict.txt)を少し編集しておきます。AutoML Visionから出力されたファイルだと下記のようにラベル名が並んでいるだけですが
Edge TPUのAPIで使えるデフォルトのコマンドに対応するためにラベルを少し修正します。各ラベルの前に数字とスペースを頭に付けてあげます。
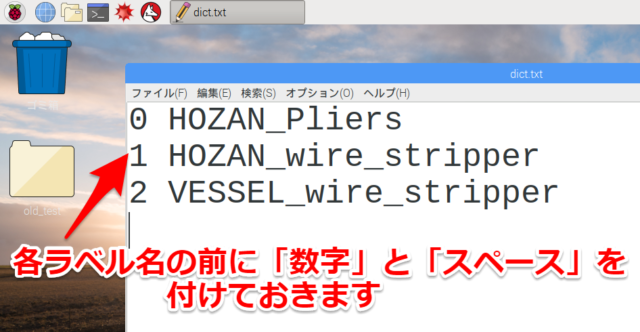
また必要なファイル(dict.txt,model.tflite,画像認識させたい写真)は任意の場所に置いてもらって構いません。
筆者は「/home/pi/python-tflite-source/edgetpu/test_data」の中にまとめて入れています
Python+AutoML Visionで作ったモデルで画像認識
今回はAutoML Visionでモデルを作った写真とは別に3枚の写真を用意しました。これらが分類できるか確認してみます
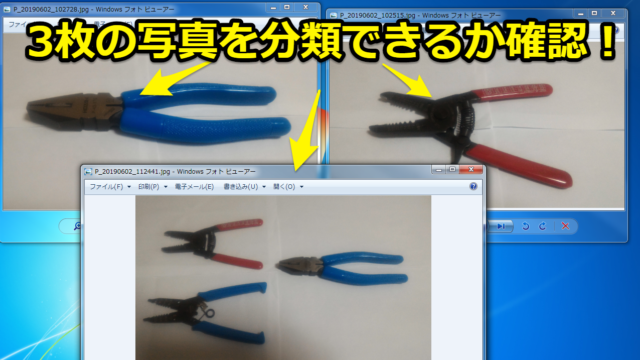
ではラズベリーパイでディレクトリを移動して、いざPythonのプログラムを実行します。
Pythonを使えると機械学習を実践する上で役立ちます
今回のテストレベルでは必要ないのですが、機械学習を学ぶ上でやはりPythonを使えるようになると色々と応用が効くようになります。
筆者は下記記事で紹介しているUdemy
で勉強することで機械学習の簡単なデバッグ・改造は出来るようになりました。
初心者が高い参考書を買って一人でPython勉強するよりは「非常に分かりやすく」「費用が抑えられる」はずですのでご参考ください。リンク先はこちらから
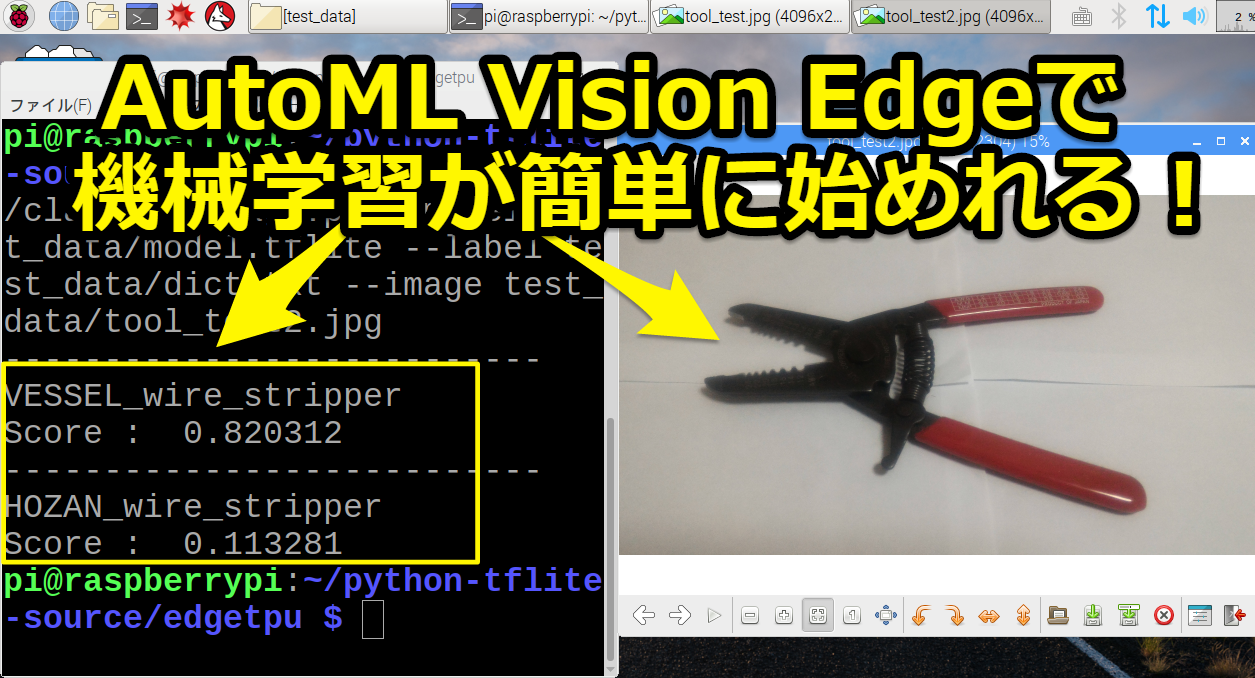
AutoML Vision Edgeのテスト結果
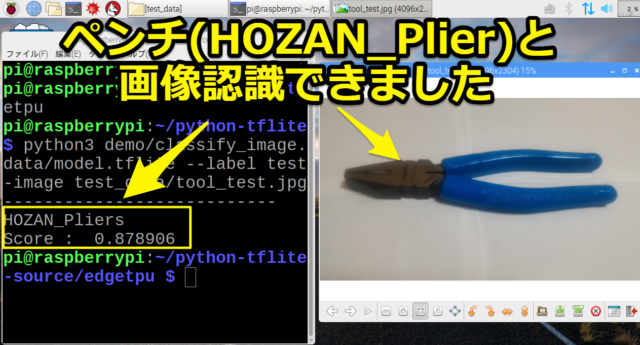
テスト結果はどの写真もしっかり分類できていました。
まずは「ペンチ」ですが「HOZAN_Pliers」としっかり画像認識できています。
HOZAN_Pliers
Score : 0.878906
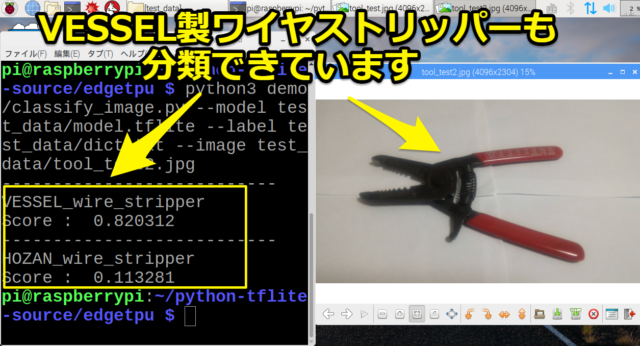
次に「VESSEL製ワイヤーストリッパー」も「VESSEL_wire_stripper」と高スコアを出しています。
またホーザン製ワイヤーストリッパーの「HOZAN_wire_stripper」も少しスコア付いていました。
VESSEL_wire_stripper
Score : 0.820312
---------------------------
HOZAN_wire_stripper
Score : 0.113281
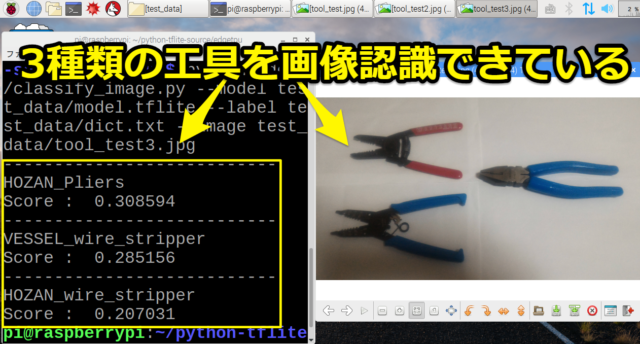
最後に3つの工具をまとめて撮った写真ですが、3つのラベルともに平均的なスコアとなり画像認識ができていました。
HOZAN_Pliers
Score : 0.308594
---------------------------
VESSEL_wire_stripper
Score : 0.285156
---------------------------
HOZAN_wire_stripper
Score : 0.207031
まとめ・感想
初心者でもAutoML Visionを使えば簡単にカスタマイズした機械学習のモデルを作成することができます。
そしてラズベリーパイ(raspberry pi)とEdge TPUのCoral USB Acceleratorで簡単にテストすることができます
非常に便利なツールだと思いますのでぜひ皆様も使ってみてください
















コメント
他の記事も合わせ、興味深い内容をありがとうございます。
よければ一つ(二つ)質問させてください。
データセットとしてオブジェクト検出を試しているのですが、
「AutoML Visionでエッジのモデルを出力する」ところで、躓いています。
この先の表示内容が、英語から日本語に変わっただけでなく色々と違うと思っています。
エラーで出力が進まないのですが、なにかアドバイスを頂けると助かります。
あと、データを保存しておくだけでクラウドにモデルをデプロイなどしないのであれば、料金は発生しないのでしょうか?当方、色んな面で素人なので戸惑っています。
何卒、よろしくお願いします。
お世話になっております。
管理人のミソジです。連絡が遅くなり申し訳ありません
筆者が分かる範囲で回答させてください
>>「AutoML Visionでエッジのモデルを出力する」ところで、躓いています。
⇒恐らくリージョンの問題かと思います
最新のAutoMLでモデル出力した記事を下記にアップしました。
よろしければご覧ください
https://misoji-engineer.com/archives/kaggle-automl.html
>>あと、データを保存しておくだけでクラウドにモデルをデプロイなどしないのであれば、料金は発生しないのでしょうか?
⇒一概に無いとは筆者からは言い切ることが出来ないのですが、
筆者自身が個人的に使っている(遊んでいる)範囲では
特に保存するだけで料金は発生していないのが現状です。
お返事ありがとうございます。自分が書き込んだコメントの記事を忘れていて、新しい記事の方で確認しました。ありがとうございます。
費用は、とりあえず直近で、0円の請求メールが来ました。注意して使用したいと思います。
AutoML Vision Edgeの画像分類ではなく、オブジェクト検出で学習をしました。
そのモデルを出力して、WEBカメラを用いてリアルタイムでオブジェクト検出を実現させたいのですが、調べても分からなかったので記事を作っていただけると幸いです。