
Zephyr RTOSでは、デバイスの性能(処理速度や応答速度)を簡単に測定できます。
公式ベンチマークテスト(latency_measure)が用意されています。
ラズパイ5(A76)、ラズパイ4B(A72)、Pico2W(M33)、Pico(M0+)で比較したテスト内容・結果を紹介します。
RTOSとしての応答速度を比較してみた(Zephyrでのベンチマーク)
Zephyr RTOSでは、デバイスの性能(処理速度や応答速度)を簡単に測定できます。
公式ベンチマークテスト(latency_measure)が用意されています。
下記のようなベンチマークが簡単に実施できました。
ラズパイ4B(A72)、Pico2W(M33)、Pico(M0+)で比較したテスト内容・結果を紹介します。
数値が小さいほど高性能(高速)です。単位はすべて ナノ秒 (ns) です。
大きいコアのA72がモチロン高速なのですが、Pico2W(M33)も頑張っていました。
*追記ラズパイ5(A76)でも測定出来ましたので追記しました。更に高速でした。
*再追記。おそらくラズパイ5(A76)2400MHz、RPi4B(A72)は600MHzで測定していたようです
| 項目 | 内容 | RPi5(A76) | RPi4B(A72) | Pico2W(M33) | Pico(M0+) |
| Context Switch | スレッド切り替え | 47 | 464 | 1,145 | 2,165 |
| ISR Resume | 割り込みから復帰 | 38 | 273 | 2,897 | 5,573 |
| Mutex Lock | 排他制御ロック | 7 | 236 | 471 | 740 |
| Semaphore Take | 待機あり取得 | 51 | 615 | 1,794 | 3,205 |
| Heap Malloc | メモリ確保 | 35 | 376 | 4,199 | 8,830 |
| Thread Create | スレッド作成 | 480 | 3,876 | 1,481 | 2,870 |
(Geminiにも協力してもらった)まとめとしては下記となります。
-
Pico 2 W (M33) はPico(M0+)と比べて「約2倍」速い
-
ほぼ全ての項目で、初代Picoの半分の時間で処理を完了しています。RTOSを載せ替えるだけでシステム全体の応答性が2倍になることを意味します。
-
-
スレッド作成 (Thread Create) の逆転現象
-
表の一番下にある通り、スレッド作成だけは RPi 4Bよりも Pico 2 W の方が高速 です (1,481ns vs 3,876ns)。
-
理由: RPi 4B (Cortex-A72) は高機能な分、メモリ管理やキャッシュの一貫性制御などのオーバーヘッドが大きいため、単純なスレッド構造体の初期化においては、構造がシンプルなマイコン (Pico 2 W) が勝ることがあります。
-
-
RPi 5 vs RPi 4B:「10倍」高速化
-
RPi 4Bも十分高速でしたが、RPi 5はそのさらに10倍高速です。
-
詳細なテスト内容・結果を紹介していきます。
ベンチマーク
よく見かけるデバイスとしてのスペック比較のCoremarkベンチマークもあります。
ただ今回使用したZephyr(RTOS)のベンチマークは、下記のlatency_measureを使いました。
RTOSとしての比較・ベンチマークしてみたいと思ったためです。
RTOSとしての応答速度を比較(Latency Measure)
- 割り込み遅延
- コンテキストスイッチ
- ミューテックスのロック解除など、
OSのオーバーヘッドを含めた速度を測定する場合、Zephyr標準の latency_measure を使います。
リアルタイム性を重視する場合に重要です。
ラズパイでZephyr(RTOS)を実装
実装・測定方法としては、公式のリポジストリをそのままビルドしただけです。
普通にZephyrのwest使ってビルドして、書き込んだだけです。
Pico2W(M33)、Pico(M0+)に関しては、そのままFlashまで出来ます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
cd %HOMEPATH% zephyrproject\.venv\Scripts\activate.bat cd zephyrproject/zephyr #Pico west build -p always -b rpi_pico tests/benchmarks/latency_measure #Pico2(W) west build -p always -b rpi_pico2/rp2350a/m33/w tests/benchmarks/latency_measure #4B west build -p always -b rpi_4b tests/benchmarks/latency_measure #5 west build -p always -b rpi_5 tests/benchmarks/latency_measure west flash -r uf2 |
普通のラズパイ4Bへの書き込み
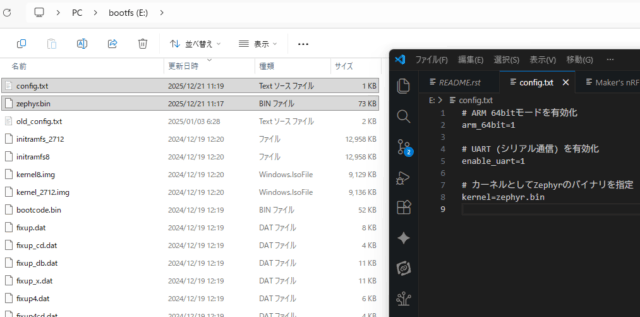
ラズパイ4Bに関しては、最初のブートファイルを弄る必要があります。
config.txtを下記のように編集して、ビルドしたzephyr.binファイルも入れます。
|
1 2 3 4 5 6 7 8 |
# ARM 64bitモードを有効化 arm_64bit=1 # UART (シリアル通信) を有効化 enable_uart=1 # カーネルとしてZephyrのバイナリを指定 kernel=zephyr.bin |
筆者は手を抜いて下記感じで、ラズパイのOS(Raspbian)が入った環境を直接弄りました。
公式の手順を確認したい方は下記を参照ください。

USBシリアルで結果表示
デフォルトでベンチマーク結果をUART出力してくれますので、配線をします。
Pico2W(M33)、Pico(M0+)は下記形です。
-
Pico Pin 1 (GP0 / TX) -> アダプタの RX
-
Pico Pin 2 (GP1 / RX) -> アダプタの TX
-
Pico GND -> アダプタの GND

ラズパイ4B(A72)は下記形です。
-
USB変換器の GND -> RPi4の GND (Pin 6)
-
USB変換器の RX -> RPi4の TX (Pin 8)
-
USB変換器の TX -> RPi4の RX (Pin 10)

ベンチマーク結果
あとは電源ONすれば勝手にRTOSがベンチマーク・結果表示してくれます。
各結果を貼り付けておきます。
ラズパイ5(A76)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
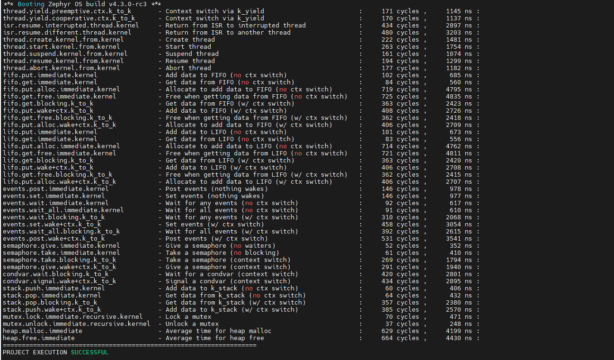
*** Booting Zephyr OS build v4.3.0-3034-g2062a21ed267 *** thread.yield.preemptive.ctx.k_to_k - Context switch via k_yield : 2 cycles , 47 ns : thread.yield.cooperative.ctx.k_to_k - Context switch via k_yield : 2 cycles , 46 ns : isr.resume.interrupted.thread.kernel - Return from ISR to interrupted thread : 2 cycles , 38 ns : isr.resume.different.thread.kernel - Return from ISR to another thread : 1 cycles , 32 ns : thread.create.kernel.from.kernel - Create thread : 25 cycles , 480 ns : thread.start.kernel.from.kernel - Start thread : 5 cycles , 94 ns : thread.suspend.kernel.from.kernel - Suspend thread : 2 cycles , 40 ns : thread.resume.kernel.from.kernel - Resume thread : 2 cycles , 42 ns : thread.abort.kernel.from.kernel - Abort thread : 0 cycles , 17 ns : fifo.put.immediate.kernel - Add data to FIFO (no ctx switch) : 0 cycles , 2 ns : fifo.get.immediate.kernel - Get data from FIFO (no ctx switch) : 0 cycles , 1 ns : fifo.put.alloc.immediate.kernel - Allocate to add data to FIFO (no ctx switch) : 2 cycles , 50 ns : fifo.get.free.immediate.kernel - Free when getting data from FIFO (no ctx switch) : 2 cycles , 45 ns : fifo.get.blocking.k_to_k - Get data from FIFO (w/ ctx switch) : 3 cycles , 68 ns : fifo.put.wake+ctx.k_to_k - Add data to FIFO (w/ ctx switch) : 5 cycles , 95 ns : fifo.get.free.blocking.k_to_k - Free when getting data from FIFO (w/ ctx switch) : 3 cycles , 68 ns : fifo.put.alloc.wake+ctx.k_to_k - Allocate to add data to FIFO (w/ ctx switch) : 5 cycles , 98 ns : lifo.put.immediate.kernel - Add data to LIFO (no ctx switch) : 0 cycles , 1 ns : lifo.get.immediate.kernel - Get data from LIFO (no ctx switch) : 0 cycles , 1 ns : lifo.put.alloc.immediate.kernel - Allocate to add data to LIFO (no ctx switch) : 2 cycles , 48 ns : lifo.get.free.immediate.kernel - Free when getting data from LIFO (no ctx switch) : 2 cycles , 44 ns : lifo.get.blocking.k_to_k - Get data from LIFO (w/ ctx switch) : 3 cycles , 68 ns : lifo.put.wake+ctx.k_to_k - Add data to LIFO (w/ ctx switch) : 4 cycles , 84 ns : lifo.get.free.blocking.k_to_k - Free when getting data from LIFO (w/ ctx switch) : 3 cycles , 69 ns : lifo.put.alloc.wake+ctx.k_to_k - Allocate to add data to LIFO (w/ ctx switch) : 4 cycles , 83 ns : events.post.immediate.kernel - Post events (nothing wakes) : 0 cycles , 16 ns : events.set.immediate.kernel - Set events (nothing wakes) : 0 cycles , 16 ns : events.wait.immediate.kernel - Wait for any events (no ctx switch) : 0 cycles , 6 ns : events.wait_all.immediate.kernel - Wait for all events (no ctx switch) : 0 cycles , 7 ns : events.wait.blocking.k_to_k - Wait for any events (w/ ctx switch) : 2 cycles , 54 ns : events.set.wake+ctx.k_to_k - Set events (w/ ctx switch) : 4 cycles , 81 ns : events.wait_all.blocking.k_to_k - Wait for all events (w/ ctx switch) : 3 cycles , 70 ns : events.post.wake+ctx.k_to_k - Post events (w/ ctx switch) : 5 cycles , 97 ns : semaphore.give.immediate.kernel - Give a semaphore (no waiters) : 0 cycles , 6 ns : semaphore.take.immediate.kernel - Take a semaphore (no blocking) : 0 cycles , 6 ns : semaphore.take.blocking.k_to_k - Take a semaphore (context switch) : 2 cycles , 51 ns : semaphore.give.wake+ctx.k_to_k - Give a semaphore (context switch) : 3 cycles , 60 ns : condvar.wait.blocking.k_to_k - Wait for a condvar (context switch) : 3 cycles , 72 ns : condvar.signal.wake+ctx.k_to_k - Signal a condvar (context switch) : 4 cycles , 86 ns : stack.push.immediate.kernel - Add data to k_stack (no ctx switch) : 0 cycles , 0 ns : stack.pop.immediate.kernel - Get data from k_stack (no ctx switch) : 0 cycles , 0 ns : stack.pop.blocking.k_to_k - Get data from k_stack (w/ ctx switch) : 3 cycles , 70 ns : stack.push.wake+ctx.k_to_k - Add data to k_stack (w/ ctx switch) : 4 cycles , 76 ns : mutex.lock.immediate.recursive.kernel - Lock a mutex : 0 cycles , 7 ns : mutex.unlock.immediate.recursive.kernel - Unlock a mutex : 0 cycles , 3 ns : heap.malloc.immediate - Average time for heap malloc : 1 cycles , 35 ns : heap.free.immediate - Average time for heap free : 2 cycles , 37 ns : =================================================================== PROJECT EXECUTION SUCCESSFUL |
ラズパイ4B(A72)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
*** Booting Zephyr OS build v4.3.0-rc3 *** thread.yield.preemptive.ctx.k_to_k - Context switch via k_yield : 25 cycles , 464 ns : thread.yield.cooperative.ctx.k_to_k - Context switch via k_yield : 25 cycles , 463 ns : isr.resume.interrupted.thread.kernel - Return from ISR to interrupted thread : 14 cycles , 273 ns : isr.resume.different.thread.kernel - Return from ISR to another thread : 16 cycles , 305 ns : thread.create.kernel.from.kernel - Create thread : 209 cycles , 3876 ns : thread.start.kernel.from.kernel - Start thread : 47 cycles , 876 ns : thread.suspend.kernel.from.kernel - Suspend thread : 24 cycles , 452 ns : thread.resume.kernel.from.kernel - Resume thread : 25 cycles , 468 ns : thread.abort.kernel.from.kernel - Abort thread : 37 cycles , 699 ns : fifo.put.immediate.kernel - Add data to FIFO (no ctx switch) : 13 cycles , 251 ns : fifo.get.immediate.kernel - Get data from FIFO (no ctx switch) : 13 cycles , 249 ns : fifo.put.alloc.immediate.kernel - Allocate to add data to FIFO (no ctx switch) : 35 cycles , 658 ns : fifo.get.free.immediate.kernel - Free when getting data from FIFO (no ctx switch) : 33 cycles , 625 ns : fifo.get.blocking.k_to_k - Get data from FIFO (w/ ctx switch) : 35 cycles , 663 ns : fifo.put.wake+ctx.k_to_k - Add data to FIFO (w/ ctx switch) : 60 cycles , 1120 ns : fifo.get.free.blocking.k_to_k - Free when getting data from FIFO (w/ ctx switch) : 36 cycles , 666 ns : fifo.put.alloc.wake+ctx.k_to_k - Allocate to add data to FIFO (w/ ctx switch) : 60 cycles , 1120 ns : lifo.put.immediate.kernel - Add data to LIFO (no ctx switch) : 13 cycles , 253 ns : lifo.get.immediate.kernel - Get data from LIFO (no ctx switch) : 13 cycles , 248 ns : lifo.put.alloc.immediate.kernel - Allocate to add data to LIFO (no ctx switch) : 35 cycles , 660 ns : lifo.get.free.immediate.kernel - Free when getting data from LIFO (no ctx switch) : 33 cycles , 624 ns : lifo.get.blocking.k_to_k - Get data from LIFO (w/ ctx switch) : 35 cycles , 663 ns : lifo.put.wake+ctx.k_to_k - Add data to LIFO (w/ ctx switch) : 60 cycles , 1120 ns : lifo.get.free.blocking.k_to_k - Free when getting data from LIFO (w/ ctx switch) : 36 cycles , 666 ns : lifo.put.alloc.wake+ctx.k_to_k - Allocate to add data to LIFO (w/ ctx switch) : 60 cycles , 1120 ns : events.post.immediate.kernel - Post events (nothing wakes) : 26 cycles , 483 ns : events.set.immediate.kernel - Set events (nothing wakes) : 26 cycles , 483 ns : events.wait.immediate.kernel - Wait for any events (no ctx switch) : 13 cycles , 241 ns : events.wait_all.immediate.kernel - Wait for all events (no ctx switch) : 13 cycles , 245 ns : events.wait.blocking.k_to_k - Wait for any events (w/ ctx switch) : 35 cycles , 663 ns : events.set.wake+ctx.k_to_k - Set events (w/ ctx switch) : 73 cycles , 1368 ns : events.wait_all.blocking.k_to_k - Wait for all events (w/ ctx switch) : 36 cycles , 678 ns : events.post.wake+ctx.k_to_k - Post events (w/ ctx switch) : 74 cycles , 1383 ns : semaphore.give.immediate.kernel - Give a semaphore (no waiters) : 12 cycles , 223 ns : semaphore.take.immediate.kernel - Take a semaphore (no blocking) : 12 cycles , 228 ns : semaphore.take.blocking.k_to_k - Take a semaphore (context switch) : 33 cycles , 615 ns : semaphore.give.wake+ctx.k_to_k - Give a semaphore (context switch) : 56 cycles , 1053 ns : condvar.wait.blocking.k_to_k - Wait for a condvar (context switch) : 48 cycles , 895 ns : condvar.signal.wake+ctx.k_to_k - Signal a condvar (context switch) : 73 cycles , 1365 ns : stack.push.immediate.kernel - Add data to k_stack (no ctx switch) : 12 cycles , 238 ns : stack.pop.immediate.kernel - Get data from k_stack (no ctx switch) : 12 cycles , 238 ns : stack.pop.blocking.k_to_k - Get data from k_stack (w/ ctx switch) : 36 cycles , 668 ns : stack.push.wake+ctx.k_to_k - Add data to k_stack (w/ ctx switch) : 60 cycles , 1115 ns : mutex.lock.immediate.recursive.kernel - Lock a mutex : 12 cycles , 236 ns : mutex.unlock.immediate.recursive.kernel - Unlock a mutex : 1 cycles , 20 ns : heap.malloc.immediate - Average time for heap malloc : 20 cycles , 376 ns : heap.free.immediate - Average time for heap free : 20 cycles , 386 ns : =================================================================== PROJECT EXECUTION SUCCESSFUL |
Pico2W(M33)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
*** Booting Zephyr OS build v4.3.0-rc3 *** thread.yield.preemptive.ctx.k_to_k - Context switch via k_yield : 171 cycles , 1145 ns : thread.yield.cooperative.ctx.k_to_k - Context switch via k_yield : 170 cycles , 1137 ns : isr.resume.interrupted.thread.kernel - Return from ISR to interrupted thread : 434 cycles , 2897 ns : isr.resume.different.thread.kernel - Return from ISR to another thread : 480 cycles , 3203 ns : thread.create.kernel.from.kernel - Create thread : 222 cycles , 1481 ns : thread.start.kernel.from.kernel - Start thread : 263 cycles , 1754 ns : thread.suspend.kernel.from.kernel - Suspend thread : 161 cycles , 1074 ns : thread.resume.kernel.from.kernel - Resume thread : 194 cycles , 1299 ns : thread.abort.kernel.from.kernel - Abort thread : 177 cycles , 1182 ns : fifo.put.immediate.kernel - Add data to FIFO (no ctx switch) : 102 cycles , 685 ns : fifo.get.immediate.kernel - Get data from FIFO (no ctx switch) : 84 cycles , 560 ns : fifo.put.alloc.immediate.kernel - Allocate to add data to FIFO (no ctx switch) : 719 cycles , 4795 ns : fifo.get.free.immediate.kernel - Free when getting data from FIFO (no ctx switch) : 725 cycles , 4835 ns : fifo.get.blocking.k_to_k - Get data from FIFO (w/ ctx switch) : 363 cycles , 2423 ns : fifo.put.wake+ctx.k_to_k - Add data to FIFO (w/ ctx switch) : 408 cycles , 2726 ns : fifo.get.free.blocking.k_to_k - Free when getting data from FIFO (w/ ctx switch) : 362 cycles , 2418 ns : fifo.put.alloc.wake+ctx.k_to_k - Allocate to add data to FIFO (w/ ctx switch) : 406 cycles , 2709 ns : lifo.put.immediate.kernel - Add data to LIFO (no ctx switch) : 101 cycles , 673 ns : lifo.get.immediate.kernel - Get data from LIFO (no ctx switch) : 83 cycles , 556 ns : lifo.put.alloc.immediate.kernel - Allocate to add data to LIFO (no ctx switch) : 714 cycles , 4762 ns : lifo.get.free.immediate.kernel - Free when getting data from LIFO (no ctx switch) : 721 cycles , 4811 ns : lifo.get.blocking.k_to_k - Get data from LIFO (w/ ctx switch) : 363 cycles , 2420 ns : lifo.put.wake+ctx.k_to_k - Add data to LIFO (w/ ctx switch) : 406 cycles , 2708 ns : lifo.get.free.blocking.k_to_k - Free when getting data from LIFO (w/ ctx switch) : 362 cycles , 2415 ns : lifo.put.alloc.wake+ctx.k_to_k - Allocate to add data to LIFO (w/ ctx switch) : 406 cycles , 2707 ns : events.post.immediate.kernel - Post events (nothing wakes) : 146 cycles , 978 ns : events.set.immediate.kernel - Set events (nothing wakes) : 146 cycles , 977 ns : events.wait.immediate.kernel - Wait for any events (no ctx switch) : 92 cycles , 617 ns : events.wait_all.immediate.kernel - Wait for all events (no ctx switch) : 91 cycles , 610 ns : events.wait.blocking.k_to_k - Wait for any events (w/ ctx switch) : 310 cycles , 2068 ns : events.set.wake+ctx.k_to_k - Set events (w/ ctx switch) : 458 cycles , 3054 ns : events.wait_all.blocking.k_to_k - Wait for all events (w/ ctx switch) : 392 cycles , 2615 ns : events.post.wake+ctx.k_to_k - Post events (w/ ctx switch) : 531 cycles , 3541 ns : semaphore.give.immediate.kernel - Give a semaphore (no waiters) : 52 cycles , 352 ns : semaphore.take.immediate.kernel - Take a semaphore (no blocking) : 61 cycles , 410 ns : semaphore.take.blocking.k_to_k - Take a semaphore (context switch) : 269 cycles , 1794 ns : semaphore.give.wake+ctx.k_to_k - Give a semaphore (context switch) : 291 cycles , 1940 ns : condvar.wait.blocking.k_to_k - Wait for a condvar (context switch) : 420 cycles , 2801 ns : condvar.signal.wake+ctx.k_to_k - Signal a condvar (context switch) : 434 cycles , 2895 ns : stack.push.immediate.kernel - Add data to k_stack (no ctx switch) : 60 cycles , 406 ns : stack.pop.immediate.kernel - Get data from k_stack (no ctx switch) : 64 cycles , 432 ns : stack.pop.blocking.k_to_k - Get data from k_stack (w/ ctx switch) : 357 cycles , 2380 ns : stack.push.wake+ctx.k_to_k - Add data to k_stack (w/ ctx switch) : 385 cycles , 2570 ns : mutex.lock.immediate.recursive.kernel - Lock a mutex : 70 cycles , 471 ns : mutex.unlock.immediate.recursive.kernel - Unlock a mutex : 37 cycles , 248 ns : heap.malloc.immediate - Average time for heap malloc : 629 cycles , 4199 ns : heap.free.immediate - Average time for heap free : 664 cycles , 4430 ns : =================================================================== PROJECT EXECUTION SUCCESSFUL |
Pico(M0+)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
*** Booting Zephyr OS build v4.3.0-rc3 *** thread.yield.preemptive.ctx.k_to_k - Context switch via k_yield : 270 cycles , 2165 ns : thread.yield.cooperative.ctx.k_to_k - Context switch via k_yield : 267 cycles , 2142 ns : isr.resume.interrupted.thread.kernel - Return from ISR to interrupted thread : 696 cycles , 5573 ns : isr.resume.different.thread.kernel - Return from ISR to another thread : 1656 cycles , 13248 ns : thread.create.kernel.from.kernel - Create thread : 358 cycles , 2870 ns : thread.start.kernel.from.kernel - Start thread : 683 cycles , 5465 ns : thread.suspend.kernel.from.kernel - Suspend thread : 339 cycles , 2715 ns : thread.resume.kernel.from.kernel - Resume thread : 334 cycles , 2679 ns : thread.abort.kernel.from.kernel - Abort thread : 236 cycles , 1895 ns : fifo.put.immediate.kernel - Add data to FIFO (no ctx switch) : 156 cycles , 1248 ns : fifo.get.immediate.kernel - Get data from FIFO (no ctx switch) : 114 cycles , 915 ns : fifo.put.alloc.immediate.kernel - Allocate to add data to FIFO (no ctx switch) : 1163 cycles , 9310 ns : fifo.get.free.immediate.kernel - Free when getting data from FIFO (no ctx switch) : 1130 cycles , 9045 ns : fifo.get.blocking.k_to_k - Get data from FIFO (w/ ctx switch) : 235406 cycles , 1883250 ns : fifo.put.wake+ctx.k_to_k - Add data to FIFO (w/ ctx switch) : 611 cycles , 4889 ns : fifo.get.free.blocking.k_to_k - Free when getting data from FIFO (w/ ctx switch) : 523 cycles , 4189 ns : fifo.put.alloc.wake+ctx.k_to_k - Allocate to add data to FIFO (w/ ctx switch) : 606 cycles , 4853 ns : lifo.put.immediate.kernel - Add data to LIFO (no ctx switch) : 235034 cycles , 1880272 ns : lifo.get.immediate.kernel - Get data from LIFO (no ctx switch) : 112 cycles , 901 ns : lifo.put.alloc.immediate.kernel - Allocate to add data to LIFO (no ctx switch) : 1150 cycles , 9202 ns : lifo.get.free.immediate.kernel - Free when getting data from LIFO (no ctx switch) : 1122 cycles , 8979 ns : lifo.get.blocking.k_to_k - Get data from LIFO (w/ ctx switch) : 521 cycles , 4171 ns : lifo.put.wake+ctx.k_to_k - Add data to LIFO (w/ ctx switch) : 606 cycles , 4854 ns : lifo.get.free.blocking.k_to_k - Free when getting data from LIFO (w/ ctx switch) : 523 cycles , 4189 ns : lifo.put.alloc.wake+ctx.k_to_k - Allocate to add data to LIFO (w/ ctx switch) : 605 cycles , 4844 ns : events.post.immediate.kernel - Post events (nothing wakes) : 196 cycles , 1569 ns : events.set.immediate.kernel - Set events (nothing wakes) : 197 cycles , 1577 ns : events.wait.immediate.kernel - Wait for any events (no ctx switch) : 142 cycles , 1143 ns : events.wait_all.immediate.kernel - Wait for all events (no ctx switch) : 147 cycles , 1176 ns : events.wait.blocking.k_to_k - Wait for any events (w/ ctx switch) : 235362 cycles , 1882903 ns : events.set.wake+ctx.k_to_k - Set events (w/ ctx switch) : 668 cycles , 5349 ns : events.wait_all.blocking.k_to_k - Wait for all events (w/ ctx switch) : 598 cycles , 4786 ns : events.post.wake+ctx.k_to_k - Post events (w/ ctx switch) : 776 cycles , 6214 ns : semaphore.give.immediate.kernel - Give a semaphore (no waiters) : 73 cycles , 585 ns : semaphore.take.immediate.kernel - Take a semaphore (no blocking) : 84 cycles , 676 ns : semaphore.take.blocking.k_to_k - Take a semaphore (context switch) : 400 cycles , 3205 ns : semaphore.give.wake+ctx.k_to_k - Give a semaphore (context switch) : 433 cycles , 3467 ns : condvar.wait.blocking.k_to_k - Wait for a condvar (context switch) : 601 cycles , 4809 ns : condvar.signal.wake+ctx.k_to_k - Signal a condvar (context switch) : 235520 cycles , 1884165 ns : stack.push.immediate.kernel - Add data to k_stack (no ctx switch) : 90 cycles , 724 ns : stack.pop.immediate.kernel - Get data from k_stack (no ctx switch) : 82 cycles , 662 ns : stack.pop.blocking.k_to_k - Get data from k_stack (w/ ctx switch) : 512 cycles , 4101 ns : stack.push.wake+ctx.k_to_k - Add data to k_stack (w/ ctx switch) : 575 cycles , 4606 ns : mutex.lock.immediate.recursive.kernel - Lock a mutex : 92 cycles , 740 ns : mutex.unlock.immediate.recursive.kernel - Unlock a mutex : 51 cycles , 408 ns : heap.malloc.immediate - Average time for heap malloc : 1103 cycles , 8830 ns : heap.free.immediate - Average time for heap free : 1056 cycles , 8450 ns : =================================================================== PROJECT EXECUTION SUCCESSFUL |
ベンチマーク比較・まとめ
RTOSの性能を評価する上で最も重要な指標を抜粋・整理しました。
(Geminiにも協力してもらいました)単位はすべて ナノ秒 (ns) です。
大きいコアのA72がモチロン高速なのですが、Pico2W(M33)も頑張っていました。
特に、スレッド作成がPico2W(M33)の方が4B(A72)より早いのが面白い結果となりました。
*追記ラズパイ5(A76)でも測定出来ましたので追記しました。更に高速でした。
処理時間比較表 (単位: ns)
数値が小さいほど高性能(高速)です。
| 項目 | 内容 | RPi5(A76) | RPi4B(A72) | Pico2W(M33) | Pico(M0+) |
| Context Switch | スレッド切り替え | 47 | 464 | 1,145 | 2,165 |
| ISR Resume | 割り込みから復帰 | 38 | 273 | 2,897 | 5,573 |
| Mutex Lock | 排他制御ロック | 7 | 236 | 471 | 740 |
| Semaphore Take | 待機あり取得 | 51 | 615 | 1,794 | 3,205 |
| Heap Malloc | メモリ確保 | 35 | 376 | 4,199 | 8,830 |
| Thread Create | スレッド作成 | 480 | 3,876 | 1,481 | 2,870 |
性能倍率・比較まとめ
「Pico 2 W」が「初代Pico」に対してどれくらい速くなったか、および「RPi 4B」がどれほど異次元かを表しています。
| 比較項目 | Pico 2W (M33)vs Pico(M0+) | RPi 4B(A72) vs Pico 2W(M33) |
| 基本動作(Context Switch) | 約 1.9倍 高速 | RPi 4B が約 2.5倍 速い |
| 割り込み応答(ISR Resume) | 約 1.9倍 高速 | RPi 4B が約 10倍 速い |
| 同期処理(Mutex/Semaphore) | 約 1.6〜1.8倍 高速 | RPi 4B が約 2〜3倍 速い |
| メモリ確保(Malloc) | 約 2.1倍 高速 | RPi 4B が約 11倍 速い |
データから読み取れる特記事項
-
Pico 2 W (M33) はPico(M0+)と比べて「約2倍」速い
-
ほぼ全ての項目で、初代Picoの半分の時間で処理を完了しています。RTOSを載せ替えるだけでシステム全体の応答性が2倍になることを意味します。
-
-
スレッド作成 (Thread Create) の逆転現象
-
表の一番下にある通り、スレッド作成だけは RPi 4Bよりも Pico 2 W の方が高速 です (1,481ns vs 3,876ns)。
-
理由: RPi 4B (Cortex-A72) は高機能な分、メモリ管理やキャッシュの一貫性制御などのオーバーヘッドが大きいため、単純なスレッド構造体の初期化においては、構造がシンプルなマイコン (Pico 2 W) が勝ることがあります。
-
-
RPi 5 vs RPi 4B:「10倍」高速化
-
RPi 4Bも十分高速でしたが、RPi 5はそのさらに10倍高速です。
-
ラズパイ5での高速化の考察
RPi 4Bも十分高速でしたが、RPi 5はそのさらに10倍高速です。
-
コンテキストスイッチ: 464ns → 47ns (約10倍速い)
-
割り込み応答: 273ns → 38ns (約7倍速い)
-
メモリ確保(Malloc): 376ns → 35ns (約10倍速い)
なぜこれほど速いのか?
-
アーキテクチャの進化: Cortex-A72 (RPi4) から Cortex-A76 (RPi5) への変更により、命令実行効率(IPC)が劇的に向上しています。
-
クロック周波数: 1.5GHz/1.8GHz から 2.4GHz への向上。
-
メモリ/キャッシュ: L2/L3キャッシュの帯域幅と速度が大幅に向上しており、OSのカーネル操作がほぼキャッシュ内で完結していると考えられます。
-
Mutex Lock (7ns): ロック取得がたった7ナノ秒ということは、メモリアクセス待ちが一切発生せず、CPUのL1キャッシュだけで爆速で処理が完了していることを示唆しています。
ラズパイ5(A76)のベンチマークは見送り
ラズパイ5も4B同様にRTOS実装して、テストしたのですがシリアル出力されませんでした。
*追記。Zephyrのメンテナーの方が対応していただき、ラズパイ5でも測定可能となりました。
但し従来のような40ピンのGPIOの配線ではなく、専用UARTコネクタの接続となります。

理由はラズパイ5以降SoCからPCIE経由で各GPIO接続されているためです。
単純にUART出力されず、PCIEドライバ経由で読み取る必要がありました。
さすがに面倒なのでラズパイ5の結果は見送ることにしました。
またブート方法に関しても4Bと差分があります。詳細は下記プルリクを参考ください。
この場を借りて、Zephyrのメンテナーの方には感謝申し上げます。

まとめ
Zephyr RTOSでは、デバイスの性能(処理速度や応答速度)を簡単に測定できます。
公式ベンチマークテスト(latency_measure)が用意されています。
ラズパイ5(A76)、ラズパイ4B(A72)、Pico2W(M33)、Pico(M0+)で比較したテスト内容・結果を紹介しました。


コメント