nuScenes形式の3D物体検出(PointPillars)をFPGAでテストしてみました。
使用した評価ボードはKV260です。
第6回AIエッジコンテストのデータセットでも確認しています。
nuScenes形式の3D物体検出をKV260(FPGA)で試したメモ
KV260でnuScenes形式のデータセットの3D物体検出をテストしました。
(KV260…Xilinx(AMD)のFPGAが搭載された評価ボード)
基本的にはVitis AIのサンプル使用して、練習・テストした内容を紹介しています。
また、同じnuScenes形式の第6回AIエッジコンテストのデータセットでも試しました。
筆者で量子化→コンパイルしたモデルも正常に動作するのか含めて確認しています。
実行環境
KV260のFPGA評価ボードの環境でテストしています。
- 評価ボード…KV260
- DPU…DPUCZDX8G_ISA1_B4096
- Vitis AI…2.5

KITTI形式でも動作確認済
KITTI形式のデータセットでも同様にKV260で3D物体検出できることを確認済です。
下記記事にて紹介しています。(リンク先はこちら)
KITTI形式の3D物体検出をKV260(FPGA)で試したメモ
KV260+YOLOXの物体検出でも動作確認済
事前にKV260のDPUを使って、物体検出(YOLO)の動作も確認済です。
プラットフォームの構築やKV260でのコマンド例含めて紹介しています。
下記記事です。(リンク先はこちら)
今回のテストでは上記記事での環境は構築済という旨で紹介していきます。
3D物体検出に必要なモデルはコンパイル済
下記記事にて3D物体検出(PointPillars+nuScenes)のモデルをコンパイル済です。
Vitis AIでPytorchのcompileをしてみたメモ
ただし、Xilinx公式からコンパイル済のモデルも提供されています。
最初はXilinxの提供のモデルをダウンロードして使用して確認します。
(最後に筆者でコンパイルしたモデルに一部入れ替えて、動作するか確認します)
nuScenes形式で3D物体検出(PointPillars)のテスト
KV260にはLANコネクタ経由でPCから接続しています。
KV260でのコマンドの実行はMobaXtermのターミナルから実行しています。
コンパイル済のモデル+LIDAR点群をKV260に送る
下記のXilinxのコンパイル済モデルとデータを送ります。
|
1 2 3 4 5 |
wget https://www.xilinx.com/bin/public/openDownload?filename=pointpillars_nuscenes_40000_64_0_pt-zcu102_zcu104_kv260-r2.5.0.tar.gz tar -xzvf openDownload\?filename\=pointpillars_nuscenes_40000_64_0_pt-zcu102_zcu104_kv260-r2.5.0.tar.gz wget https://www.xilinx.com/bin/public/openDownload?filename=pointpillars_nuscenes_40000_64_1_pt-zcu102_zcu104_kv260-r2.5.0.tar.gz tar -xzvf openDownload\?filename\=pointpillars_nuscenes_40000_64_1_pt-zcu102_zcu104_kv260-r2.5.0.tar.gz scp -r pointpillars_nuscenes_40000_64_0_pt pointpillars_nuscenes_40000_64_1_pt petalinux@192.168.11.13:~ |
今回使うnuScenes(mini)のLIDAR点群のデータは下記です。
n008-2018-08-27-11-48-51-0400__LIDAR_TOP__1535385111448839.pcd.bin
IDはscene_id = 3, frame_id = 39です。
その時の全6方向のカメラの内、前方と後方のカメラ画像は下記になります。


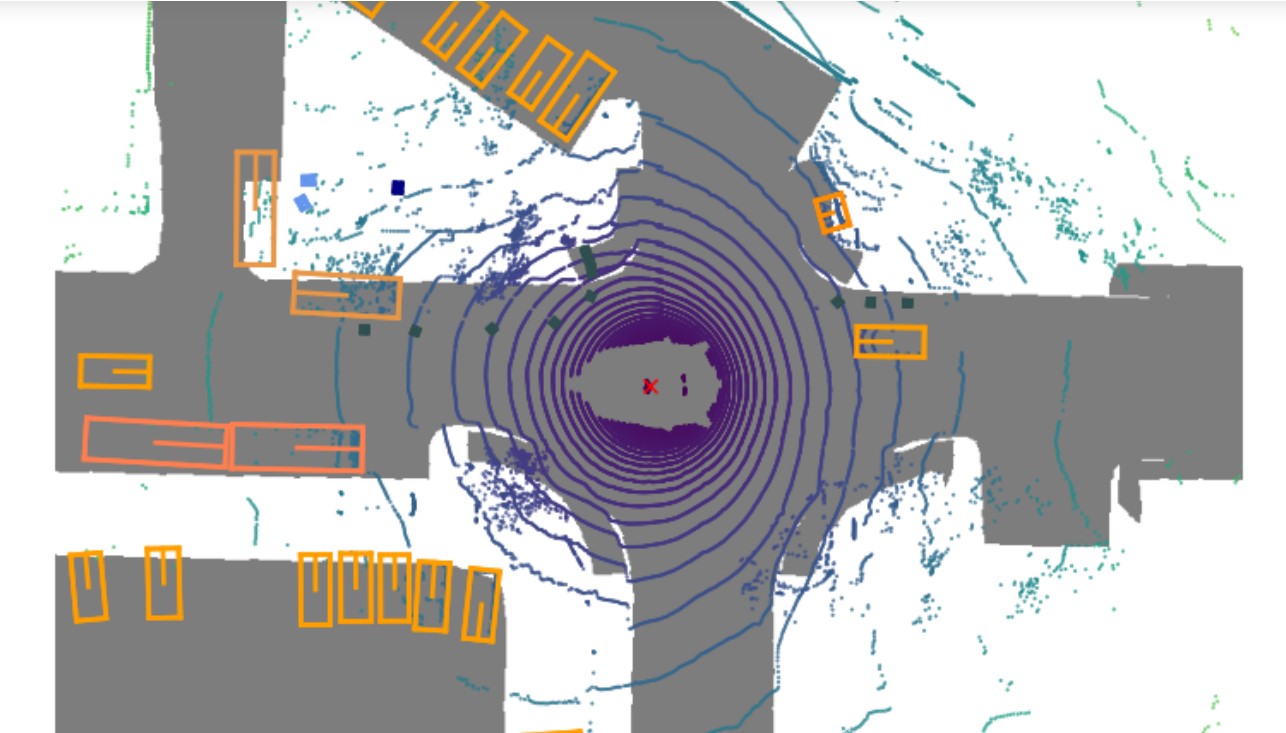
LIDAR点群は360で検出しており、nuscenes-devkitで確認すると下記イメージです。
(下記のマップ+LIDAR点群の右方向が、自動車の前方向になっています)
自動車含めて大量に検出する3D物体があります。
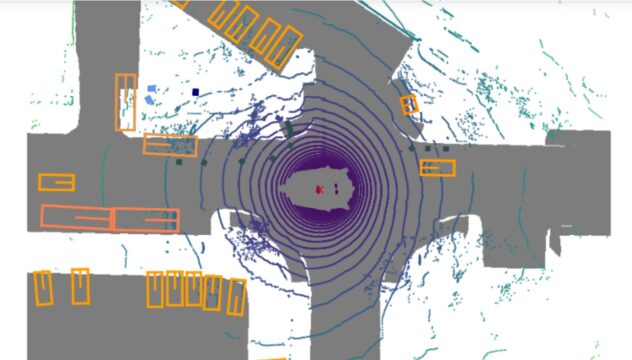
sample_pointpillars_nuscenes.infoを作る
ライブラリを確認しますと、プログラムを動かすにはファイルを作成する必要があります。
下記のReadmeにも記載されている、「sample_pointpillars_nuscenes.info」です。
※動かすプログラムは「test_bin_pointpillars_nuscenes.cpp」をビルドしたものです
https://github.com/Xilinx/Vitis-AI/tree/2.5/examples/Vitis-AI-Library/samples/pointpillars_nuscenes
LIDAR点群のファイル位置に加えて、タイムスタンプ・sweepsも記載しときます。
※タイムスタンプ(timestamp)もnuscenes-devkitで確認できます。
※sweeps(線形補間)のデータは入れていないので「0」です。
下記のようなファイル(sample_pointpillars_nuscenes_test.info)を作成しました。
|
1 2 3 |
lidar_path:./n008-2018-08-27-11-48-51-0400__LIDAR_TOP__1535385111448839.pcd.bin timestamp:1535385111448839 sweeps:0 |
KV260でnuScenes+PointPillarsで3D物体検出をする
必要なモデル・ファイルを、KV260のVitis AIライブラリ内に置きます。
その後「/usr/share/vitis_ai_library/samples/pointpillars_nuscenes」で3D物体検出をします。
|
1 2 3 4 5 6 7 8 9 |
sudo cp -rf pointpillars_nuscenes_40000_64_0_pt/ /usr/share/vitis_ai_library/models/ sudo cp -rf pointpillars_nuscenes_40000_64_1_pt/ /usr/share/vitis_ai_library/models/ sudo cp n008-2018-08-27-11-48-51-0400__LIDAR_TOP__1535385111448839.pcd.bin /usr/share/vitis_ai_library/samples/pointpillars_nuscenes/ sudo cp sample_pointpillars_nuscenes_test.info /usr/share/vitis_ai_library/samples/pointpillars_nuscenes/ sudo xmutil listapps sudo xmutil unloadapp sudo xmutil loadapp aiedge_4096 cd /usr/share/vitis_ai_library/samples/pointpillars_nuscenes ./test_bin_pointpillars_nuscenes pointpillars_nuscenes_40000_64_0_pt pointpillars_nuscenes_40000_64_1_pt ./sample_pointpillars_nuscenes_test.info |
実際に3D物体検出のプログラムを走らせると、下記のようになりました。
大量に検出している「0」が自動車のはずです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
uscenes pointpillars_nuscenes_40000_64_0_pt pointpillars_nuscenes_40000_64_1_pt ./sample_pointpillars_nuscenes_test.info batch : 0 label: 0 bbox: -2.728 15.4407 -1.04664 1.95018 4.60718 1.72271 6.34569 0.0625 -2.625 score: 0.952574 label: 0 bbox: -19.1916 -6.2 -1.85228 2.1675 5.58582 2.26329 5.27409 0 0 score: 0.952574 label: 0 bbox: 14.3193 -15.4407 -2.60957 1.95018 4.60718 1.83381 1.57 0 0 score: 0.939913 label: 0 bbox: 14.8153 -12.152 -2.55401 1.95018 4.60718 1.72271 4.77409 0 0 score: 0.924142 label: 0 bbox: 24.552 -8.23178 -2.68257 2.1675 4.92947 1.87633 6.28319 0 0 score: 0.817575 label: 0 bbox: 40.92 -8.00068 -2.28649 1.83202 4.32805 1.61833 3.20409 0 0.0625 score: 0.731059 label: 0 bbox: 13.64 -20.8967 -2.60949 1.83202 4.32805 1.61833 1.6325 0 0 score: 0.731059 label: 0 bbox: 14.8153 -17.9207 -2.66168 1.83202 4.32805 1.72271 1.57 0 0 score: 0.622459 label: 0 bbox: -1.24 -36.456 -2.60949 1.95018 4.32805 1.61833 3.20409 0 0 score: 0.562177 label: 0 bbox: 13.64 -23.064 -2.71716 1.83202 4.32805 1.61833 1.5075 0 0 score: 0.5 label: 0 bbox: 35.5118 29.512 -1.10121 2.30729 5.58582 2.12616 1.6325 0 0 score: 0.437824 label: 0 bbox: 35.9122 37.448 -0.248065 2.30729 5.58582 2.12616 1.445 0 0 score: 0.377541 label: 0 bbox: -22.568 -11.656 -1.96348 1.95018 4.32805 1.61833 5.21159 0 0 score: 0.377541 label: 0 bbox: 13.64 -33.48 -2.9325 1.95018 4.60718 1.61833 1.57 0 0 score: 0.377541 label: 0 bbox: 35.464 40.424 -0.240842 2.07595 4.60718 1.83381 1.5075 0 0 score: 0.320821 label: 0 bbox: -20.7673 -8.68 -1.85581 1.95018 4.32805 1.61833 5.27409 0 0 score: 0.320821 label: 0 bbox: 28.52 -32.984 -3.14791 1.95018 4.60718 1.83381 4.89909 0 0 score: 0.320821 label: 1 bbox: -5.704 -21.6238 -2.70542 2.30729 5.94607 2.26329 6.47069 0 -0.0625 score: 0.679179 label: 1 bbox: 36.0078 37.448 -0.560241 2.30729 5.94607 2.40926 1.5075 0 0 score: 0.320821 label: 2 bbox: -11.7854 11.656 -1.15736 2.35236 1.8042 3.88218 6.10319 0 0 score: 0.377541 label: 3 bbox: 4.216 -26.592 -2.76191 3.05965 12.0132 3.58395 3.14159 0.0625 3.3125 score: 0.982014 label: 3 bbox: 4.216 -36.952 -2.87748 2.87427 10.6016 3.8151 3.14159 0 0 score: 0.7773 label: 4 bbox: -11.656 -27.9762 -2.53479 2.30729 7.17233 2.26329 1.695 0 0 score: 0.904651 label: 4 bbox: -5.75178 -21.5282 -2.60778 2.30729 6.32956 2.40926 6.47069 0 0 score: 0.437824 label: 7 bbox: -29.0774 14.0745 -0.958795 0.663449 0.640378 1.75748 4.52409 0 0 score: 0.377541 label: 7 bbox: 5.51965 -13.0825 -2.05722 0.751786 0.772444 1.75748 6.08659 -0.0625 0 score: 0.320821 label: 7 bbox: -4.8349 -19.0345 -2.38675 0.706238 0.772444 1.75748 3.2575 0 0 score: 0.320821 label: 7 bbox: -6.63455 -19.0345 -2.44342 0.751786 0.772444 1.87083 3.07 0 0 score: 0.320821 label: 7 bbox: -9.73345 -25.048 -2.60643 0.663449 0.681679 1.75748 5.02409 0 0 score: 0.320821 label: 8 bbox: -5.63324 11.6914 -1.28267 0.396945 0.403593 0.937495 5.04069 0 0 score: 0.377541 label: 8 bbox: -4.10986 -7.22738 -2.02433 0.396945 0.403593 0.827337 4.66569 0 0 score: 0.377541 |
nuScenesで検出したlabel名に関して
今回の3D物体検出に関してはmmdetection3dをベースにして処理しています。
(ライブラリのVitis AI側でラベルの入れ替えはしていないと思いますが…)
おそらく、前処理のnuscenes_converterpyの下記順番でカテゴリ化されています。
|
1 2 3 |
nus_categories = ('car', 'truck', 'trailer', 'bus', 'construction_vehicle', 'bicycle', 'motorcycle', 'pedestrian', 'traffic_cone', 'barrier') |
今回の3D物体検出した結果からも多分あっているとは思います。
- 全方向に存在している自動車_carが「0」が大量にあり。
- 後方の大きな、バス_busの「3」と重機_construction_vehicleの「4」も高い評価値。
- 近くのコーン_traffic_coneの「7」も検出できている。
第6回AIエッジコンテストのデータセットで確認
同じnuScenes形式の第6回AIエッジコンテストのデータセットでも確認してみます。
2例ほど確認した結果ですが、自動車などは問題なく3D物体検出できていました。
ただ、人や自転車などの小さい物体の検出漏れが多かったです。
3D物体検出数が少ないデータ例
一つ目はシンプルなデータです(IDはscene_id = 2, frame_id = 1です)
LIDAR点群データとしては下記となります。
/3d_labels/samples/LIDAR_TOP/CXu8FUXumyRCt1FfFTjNFqZt_1.bin
自動車前方のカメラです。少し小さいですが自動車と自転車が1台づつ確認できます。
また右サイド側には工事中の障壁も確認できます。
/3d_labels/samples/CAM_FRONT/CXu8FUXumyRCt1FfFTjNFqZt_1.jpg

nuscenes-devkitで確認したLIDAR点群としては下記イメージです。
写真同様に自動車前方には2つの物体がアノテーションされています。
※後方にも自動車が有りそうですが、このデータは前方のみのアノテーションということです。

3D物体検出(PointPillars)すると下記結果となりました。
- 前方(後方含めた)の自動車_carの「0」を検出できている
- また右側サイドの障壁_barrier「9」も若干検出できている
- 残念ながら小さい自転車_bicycle「5」は検出できず…
|
1 2 3 4 5 6 7 8 9 10 11 |
xilinx-k26-starterkit-20221:/usr/share/vitis_ai_library/samples/pointpillars_nuscenes$ ./test_bin_pointpillars_nuscenes pointpillars_nuscenes_40000_64_0_pt pointpillars_nuscenes_40000_64_1_pt ./sample_pointpillars_nuscenes_signate1.info batch : 0 label: 0 bbox: -24.3687 -0.560682 -1.74821 1.83202 4.60718 1.83381 4.71159 5.75 -0.25 score: 0.880797 label: 0 bbox: -9.85532 8.36732 -1.64047 1.83202 4.32805 1.61833 4.71159 0 0 score: 0.731059 label: 0 bbox: -9.672 6.2 -1.58499 1.83202 4.06582 1.72271 4.64909 0 0 score: 0.731059 label: 0 bbox: -9.176 2.728 -1.74814 1.83202 4.32805 1.61833 4.64909 0 0 score: 0.679179 label: 0 bbox: -32.984 9.176 -1.20987 1.95018 4.60718 1.83381 3.07909 0 0.1875 score: 0.5 label: 0 bbox: 29.016 0.431318 -1.97797 1.95018 4.90432 2.07798 1.445 0.1875 0.125 score: 0.437824 label: 0 bbox: 0.431318 -29.512 -0.0840778 1.83202 4.06582 1.52028 1.445 0 0 score: 0.437824 label: 0 bbox: -38.2567 -1.736 -1.69266 1.95018 4.32805 1.72271 4.21159 0 0 score: 0.377541 label: 9 bbox: 7.688 2.728 -2.00971 3.19734 0.585965 0.982971 6.28319 0 0 score: 0.320821 |
3D物体検出数が多いデータ例
二つ目は3D物体検出数が多いデータです(IDはscene_id = 29, frame_id = 73です)
/3d_labels/samples/LIDAR_TOP/HavlOgYpwQNuWPnzpPti53w5_73.bin
このデータに関してはリファレンス環境の検出結果例でも紹介されていたものです。
https://github.com/pometa0507/6th-ai-reference2/blob/master/notebook/1-5_single_inference.ipynb
自動車前方の画像には数台の車と、小さいですが左前方に歩行者が確認できます

nuscenes-devkitで確認したLIDAR点群としては下記イメージです。
360°のLIDAR点群だと前方以外にも多くの自動車、大きい車両が確認できています。
※このデータに関しては360°のアノテーションがされていました。
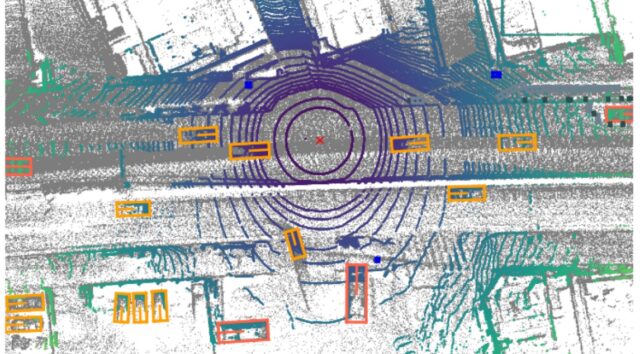
3D物体検出(PointPillars)すると下記結果となりました。
- 多くの自動車_carの「0」を高い評価値で検出できている
- 大き目な車両もトラック_truck「1」として検出できている
- 残念ながら小さい歩行者_pedestrian「7」は検出できず…
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
xilinx-k26-starterkit-20221:/usr/share/vitis_ai_library/samples/pointpillars_nuscenes$ ./test_bin_pointpillars_nuscenes pointpillars_nuscenes_40000_64_0_pt pointpillars_nuscenes_40000_64_1_pt ./sample_pointpillars_nuscenes_signate2.info batch : 0 label: 0 bbox: -14.9447 0.744001 -1.80033 1.95018 4.60718 1.72271 4.64909 3.9375 0.1875 score: 0.924142 label: 0 bbox: 19.096 -7.00868 -2.07115 1.95018 4.60718 1.61833 1.5075 -4.125 0.25 score: 0.904651 label: 0 bbox: 11.16 -0.743999 -1.908 1.83202 4.32805 1.72271 4.64909 2.5625 -0.0625 score: 0.880797 label: 0 bbox: -23.8727 -8.99268 -2.12334 1.83202 4.60718 1.72271 1.57 0 0 score: 0.880797 label: 0 bbox: -8.99268 -1.42332 -1.9373 1.95018 4.90432 2.212 4.64909 1.125 0 score: 0.851953 label: 0 bbox: 12.9607 -34.1593 -2.87702 1.95018 4.60718 1.72271 2.95409 -1.375 7.625 score: 0.817575 label: 0 bbox: -3.04068 -13.4567 -2.44634 1.83202 4.06582 1.72271 2.82909 -1.375 5.5 score: 0.731059 label: 0 bbox: -4.712 -35.96 -2.60949 1.83202 4.32805 1.61833 3.07909 -0.0625 2.375 score: 0.731059 label: 0 bbox: 42.408 -7.00868 -2.01567 1.95018 4.32805 1.72271 1.6325 -6.9375 0.5625 score: 0.562177 label: 0 bbox: -20.088 -21.576 -2.5019 1.95018 4.60718 1.83381 6.22069 0 0 score: 0.562177 label: 0 bbox: -9.76756 -24.552 -2.68558 2.45609 6.73778 2.90612 1.5075 1.4375 0.5 score: 0.5 label: 0 bbox: -7.688 -35.7767 -2.71723 1.83202 4.32805 1.83381 6.22069 0 0 score: 0.5 label: 1 bbox: 4.712 -19.6398 -2.68558 2.6145 6.73778 2.90612 3.14159 -0.125 6.375 score: 0.817575 label: 1 bbox: 4.216 -33.9282 -2.68558 2.6145 6.32956 2.90612 3.14159 0 0 score: 0.679179 label: 1 bbox: -9.52865 -24.552 -2.59754 2.45609 6.32956 2.73005 4.64909 1.3125 0.125 score: 0.562177 label: 1 bbox: -23.064 -21.0322 -2.46623 2.45609 5.58582 2.12616 1.57 0 0 score: 0.5 |
自分で量子化・コンパイルしたモデルでも確認してみる
下記記事にて筆者で量子化したモデルをコンパイル済です。
Vitis AIでPytorchのcompileをしてみたメモ
一部のモデルを置き換えてテストしてみます。
(あまり意味はないかもしれませんが、せっかく学習→量子化→コンパイルまでしたので…)
同様な結果が出るかチェックの意図です。
|
1 2 3 |
sudo rm /usr/share/vitis_ai_library/models/pointpillars_nuscenes_40000_64_1_pt/pointpillars_nuscenes_40000_64_1_pt.xmodel ls -l sudo cp pointpillars_nuscenes_40000_64_1_pt.xmodel /usr/share/vitis_ai_library/models/pointpillars_nuscenes_40000_64_1_pt/ |
筆者で作ったモデルでも無事に3D物体検出できました。
基本的には結果は変わりませんでした。
前者の検出数が少ない例での確認ですが、ほんの少し自動車の検出が強めになったようです。
- 一番評価値の高い自動車 score: 0.880797 →score: 0.904651
- (評価値は低いが)大き目な車両をトラック_truck「1」として検出している
|
1 2 3 4 5 6 7 8 9 10 11 |
scenes pointpillars_nuscenes_40000_64_0_pt pointpillars_nuscenes_40000_64_1_pt ./sample_pointpillars_nuscenes_signate1.info batch : 0 label: 0 bbox: -24.3687 -0.560682 -1.80033 1.95018 4.32805 1.72271 4.64909 7.125 -0.125 score: 0.904651 label: 0 bbox: -9.98468 8.49668 -1.59145 1.83202 4.06582 1.52028 4.64909 0 0 score: 0.679179 label: 0 bbox: -32.984 9.176 -1.20987 1.95018 4.60718 1.83381 3.07909 0 0 score: 0.562177 label: 0 bbox: -9.672 6.2 -1.64047 1.83202 4.06582 1.61833 4.64909 0 0 score: 0.562177 label: 0 bbox: -8.99268 2.728 -1.74814 1.83202 4.06582 1.61833 4.64909 0 0 score: 0.437824 label: 0 bbox: -38.2567 -1.736 -1.69266 1.95018 4.32805 1.72271 4.21159 0 0 score: 0.437824 label: 0 bbox: 29.1993 0.431318 -1.97797 1.95018 4.90432 2.07798 1.5075 -0.25 -0.0625 score: 0.320821 label: 1 bbox: 29.5598 0.248001 -1.85228 2.1675 5.58582 2.26329 1.5075 2.6875 0.0625 score: 0.320821 label: 9 bbox: 7.688 2.728 -2.00971 3.19734 0.585965 0.982971 6.28319 0 0 score: 0.320821 |
まとめ
KV260でnuScenes形式でもPointPillarsの3D物体検出ができました。
第6回AIエッジコンテストのデータセットでも検出することができました。
今回の記事含めて、第6回AIエッジコンテストの一環でした。
下記にてコンテストでテスト・実施したことのまとめを紹介しています。



コメント